
import torch
from diffusers.pipelines import FluxPipeline
from modelscope import snapshot_download
model_id = snapshot_download("AI-ModelScope/FLUX.1-dev")
adapter_id = snapshot_download("alimama-creative/FLUX.1-Turbo-Alpha")
pipe = FluxPipeline.from_pretrained(
model_id,
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
pipe.load_lora_weights(adapter_id)
pipe.fuse_lora()
prompt = "A DSLR photo of a shiny VW van that has a cityscape painted on it. A smiling sloth stands on grass in front of the van and is wearing a leather jacket, a cowboy hat, a kilt and a bowtie. The sloth is holding a quarterstaff and a big book."
image = pipe(
prompt=prompt,
guidance_scale=3.5,
height=1024,
width=1024,
num_inference_steps=8,
max_sequence_length=512).images[0]阿里妈妈技术开源FLUX图像修复&蒸馏加速模型
本文介绍了阿里妈妈技术团队基于FLUX开发的Controlnet修复模型和蒸馏加速模型,填补了社区空白并提升了FLUX的实用性和效率。
·
01
概述
阿里妈妈智能创作与AI应用团队近期开源了两项FLUX 文生图模型的的实用配套模型。Black Forest Lab 的 FLUX [1] 文生图模型具有更高的生成画面质量和指令遵循能力,一经推出便受到业界广泛关注,也有很多优秀的控制插件和 LoRA 微调模型陆续跟进,但是通过修复(Inpainting)进行可控生成的插件还未有公开可用的模型,另一方面 FLUX 12B 的参数量会带来显著的推理时耗和计算开销。
研究团队针对这一行业需求进行了相关探索,开源了基于 FLUX(FLUX.1-dev) 的Controlnet 修复模型以及8步加速 Turbo 模型两个配套模型。更进一步,两个模型可互相兼容配合实用,达到更快的修复生图。两项开源模型收到了社区积极反馈,在HuggingFace 社区居于趋势榜前列。
FLUX修复Controlnet模型主页(已更新至Beta版本):
-
Huggingface 链接:https://huggingface.co/alimama-creative/FLUX.1-dev-Controlnet-Inpainting-Beta
-
ModelScope 链接:https://www.modelscope.cn/models/alimama-creative/FLUX.1-dev-Controlnet-Inpainting-Beta
FLUX8步加速Lora模型主页(Alpha版本):
-
Huggingface 链接:https://huggingface.co/alimama-creative/FLUX.1-Turbo-Alpha
-
ModelScope 链接:https://www.modelscope.cn/models/alimama-creative/FLUX.1-Turbo-Alpha
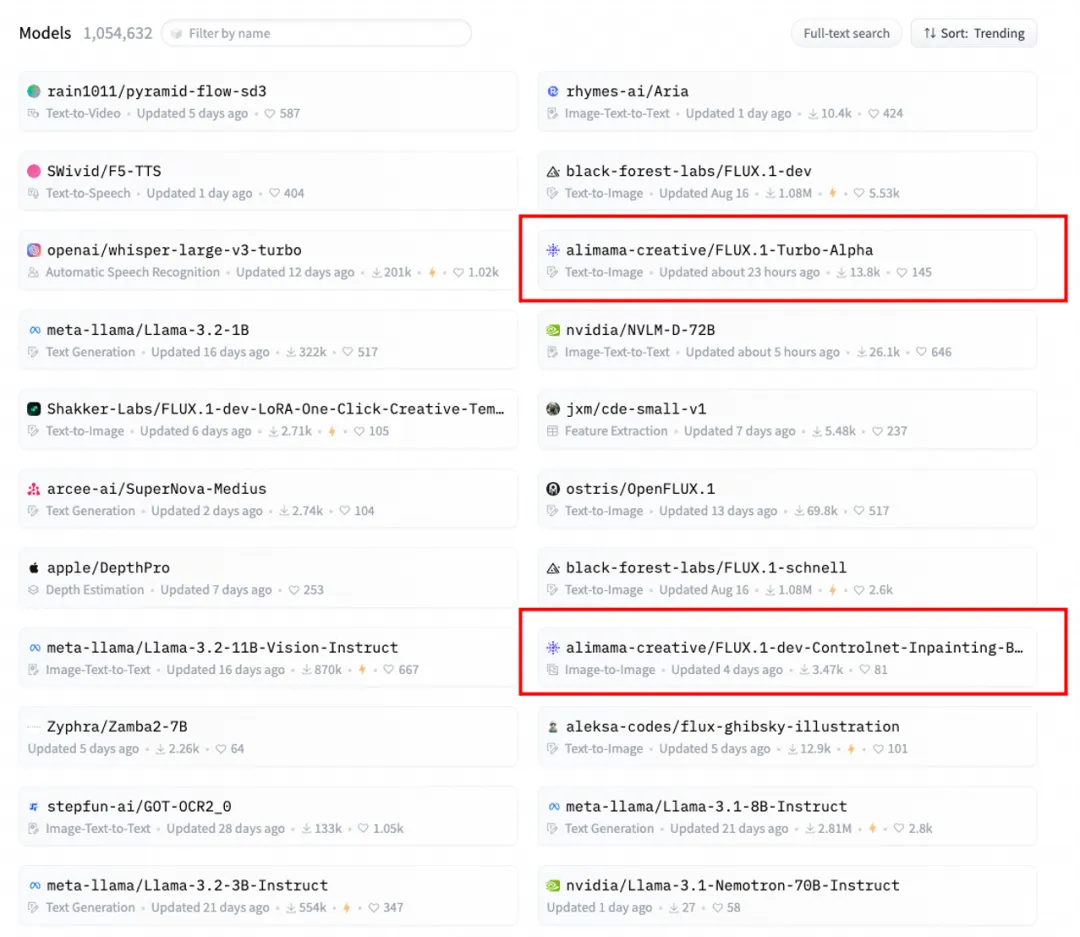
两个模型均排名开源社区趋势榜前列(2024年10月16日)
02
图像修复 Controlnet模型
图像修复(Image Inpainting)对图像的指定区域根据指令进行重新生成。在创意设计领域,设计师可以利用该模型快速修复或改变图像中的特定元素、在个人照片编辑领域,普通用户可以轻松去除照片中不想要的元素或添加新的内容。毫不夸张地说,图像修复的ControlNet 是FLUX基础模型用于图像可控生成的关键插件, 同时相较于其他控制条件(线稿、姿势、深度图等)也有较高的训练难度,对模型在丰富场景中的泛化能力、预测合理性和稳定性有较高要求。
因此,研究团队从FLUX 模型采用的 DiT 模型结构和 Flow Matching [2] 训练机制出发,在嵌入的ControlNet模型结构和训练流程方面进行探索。
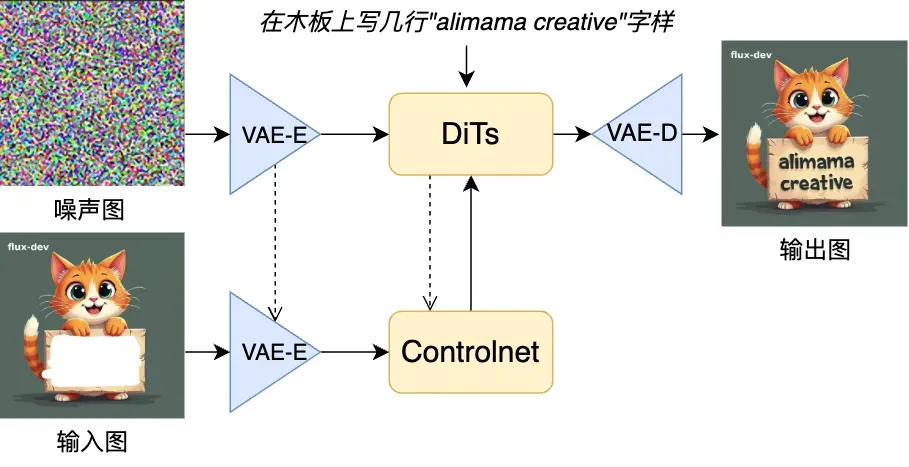
Controlnet模型结构探索
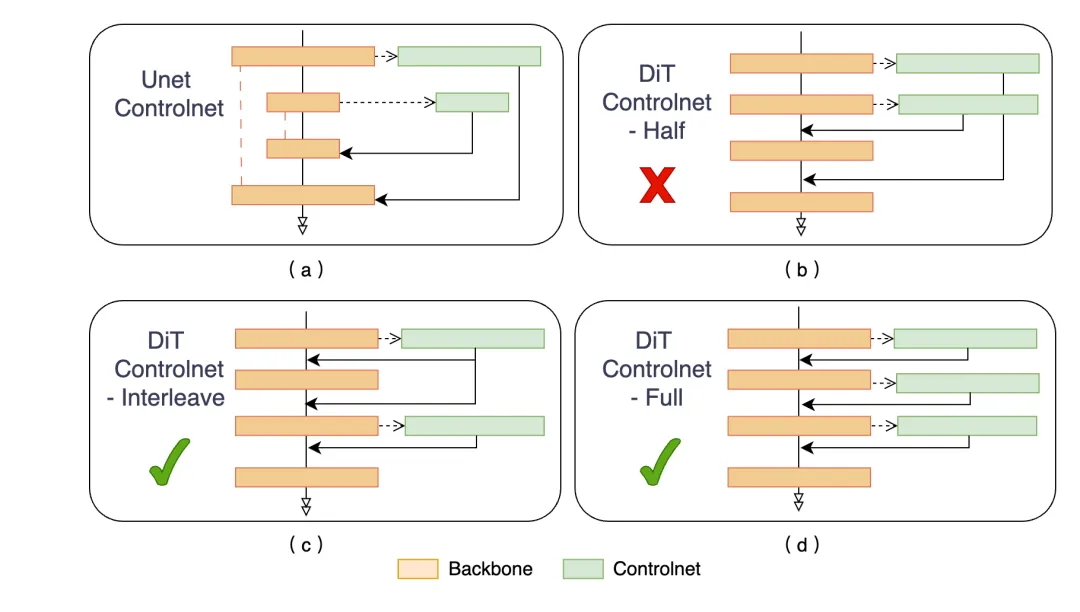
社区普遍使用的Unet Controlnet [3] (图a) ,直接迁移到DiT架构上需要将前一半的特征加到后一半上面。不同于传统的基于Unet的文生图结构,Dit的文生图模型由一系列的transformer block堆叠而成,没有显式的Encoder-Decoder结构,因此直接迁移效果不好。研究团队在同样是 DiT 框架的 SD3 Inpainting 上实验发现更多控制层数的 Full 结构相较于 Half 与 Interleave 结构收敛更快。由于训练时显存限制,FLUX 的inpainting 采用interleave(图c)结构进行训练,在模型收敛效果和显存&计算量取得平衡。
由粗到细的多阶段训练
从公开的图文对数据集和内部数据集过滤出千万量级数据用于训练,并对其中的图片通过多模态大模型进行长Caption重打标。研究团队先在768分辨率进行训练得到Alpha版本,然后在1024分辨率进行继续训练得到 Beta 版本。相比于 Alpha 版本相比,Beta图像修复模型提升了以下特性:
1、从768图像分辨率升级到1024:能够直接处理和生成1024x1024分辨率的图像,无需额外的放大步骤,提供更高质量和更详细的输出结果。得益于多通道VAE的强大重构能力,生成的结果中非重绘区域依然能高保真复原。
2、增强细节生成:经过微调以捕捉和重现修复区域的更精细细节。
3、改进提示词控制:减少额外的控制信号对 FLUX.1底模能力的影响使模型对生成内容提供更精确的控制。
效果对比
对比Diffusers官方开源的基于SDXL的Inpainting模型 [4] ,FLUX-Inpainting模型继承了FLUX 更好基础能力,在指令跟随、文字生成、画面效果方面都有突出优势,
其中最新的Beta版相比一个月前的Alpha版效果有进一步提升。以下是对比结果(都没有进行原图贴回操作):


跟其他扩散模型一样,直接使用Inpainting模型仍需进行多步迭代推理(28步)才能达到比较满意的结果,为加快推理速度,研究团队探索了加速扩散方法:
03
蒸馏加速模型
扩散模型由于需要多步去噪的推理生成方式,使得图片生成速度缓慢,计算资源需求高。尤其是对于 FLUX 模型来讲,其高达12B的参数量,在实际使用中具有较大困难。针对推理加速这个问题,已经有不少优秀的工作在 SD1.5 或 SDXL 上进行了降低采样步数的相关研究,但是对于FLUX的相关加速研究还较少。
由此,阿里妈妈智能创作与AI应用团队探索训练出了一个8步蒸馏模型,使得 FLUX 在8步的采样步数下,接近原本 FLUX 30步左右推理的效果,模型对于修复也适配良好,能够在接近原修复质量同时实现更快的推理。
技术介绍
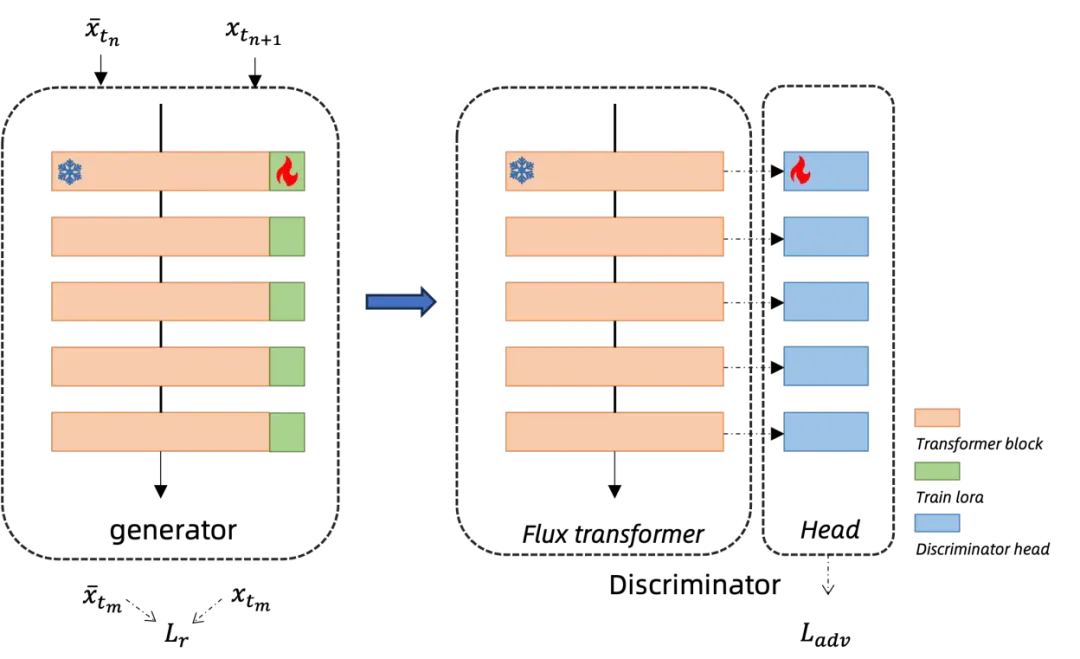
研究团队采用改进的一致性蒸馏算法 [5],并使用了对抗训练来提升蒸馏的效果。对于对抗训练所需的判别器模型,研究团队设计了一种多头的判别器模型,在固定原始 FLUX 的Transformer的权重,在每一层 Transformer Block 后接一个可训练的由几层 MLP 构成的Head,如图所示。判别器的输出由所有Head的均值决定,这样的Head设计,充分利用了FLUX Transformer 的不同层级特征,能够更加有效的监督蒸馏后的效果。
效果&加速对比
研究团队在文生图任务上进行了尝试,对比原始 FLUX.1-dev 28步的结果, 8步 LoRA加速后的结果几乎逼近原始结果。可以看到,加速模型在通用场景、人像场景、电商场景都取得了不错的效果:

图像修复叠加蒸馏加速
加速模型配合修复模型能够在接近原始修复效果的情况下实现更快的修复速度。在H20机器,使用T5xxl-fp16结合FLUX.1-dev-fp8模型进行测试,在true_cfg设置为1的情况下,原始30step需要约26s,叠加加速模型后只需要约8s,推理速度提升了约三倍,效果损失微小。

04
最佳实践
diffusers模型推理
diffusers推理示例代码(A100):
生图速度:
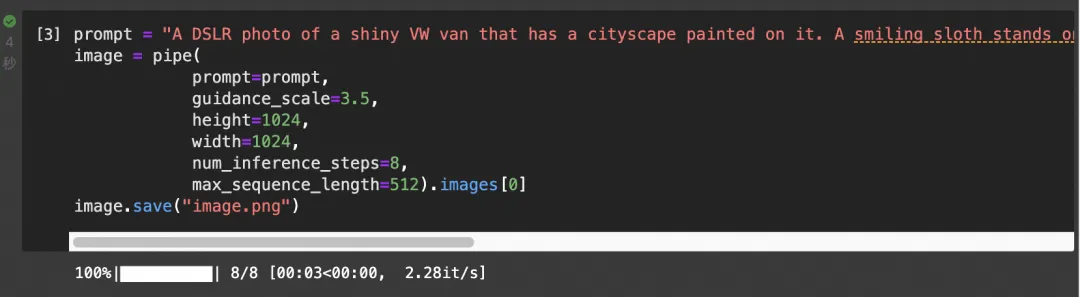
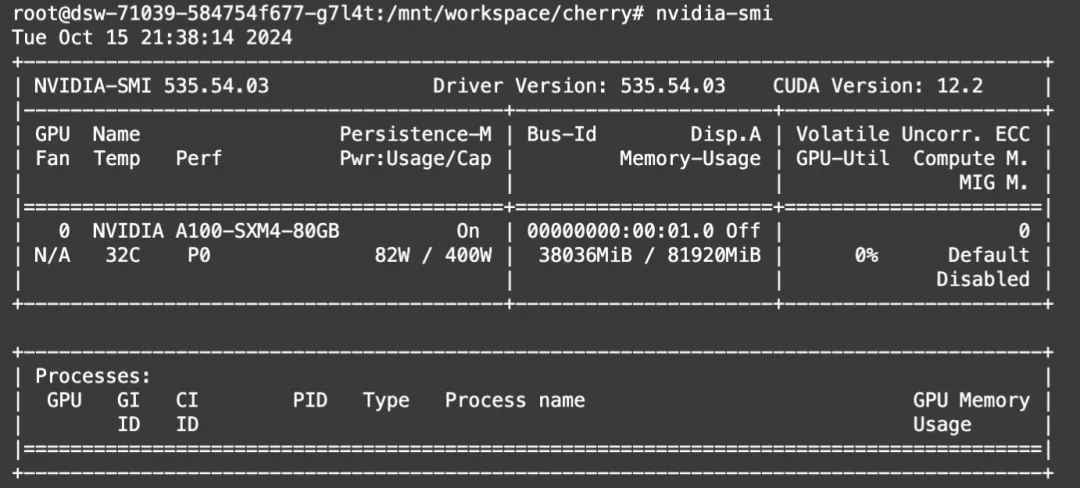
显存占用:
ComfyUI模型体验
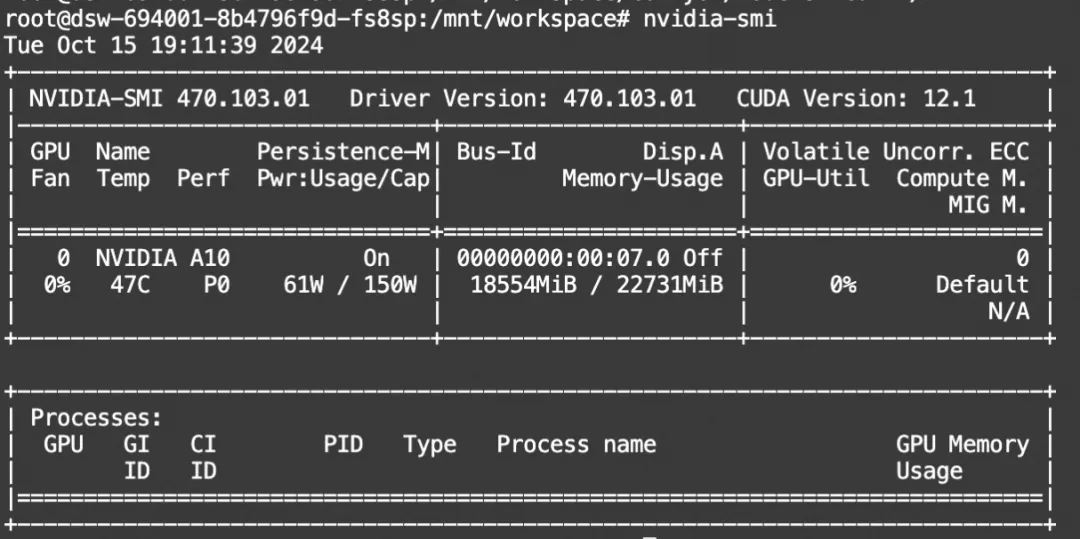
使用diffusers的显存占用较高,下面演示在魔搭免费算力(22G)通过ComfyUI使用FLUX fp8模型+图像修复ControlNet模型+加速模型实现秒级图像修复生图。
环境配置和安装:
-
python 3.10及以上版本
-
pytorch 1.12及以上版本,推荐2.0及以上版本
-
建议使用CUDA 11.4及以上
本文在魔搭社区免费提供的GPU免费算力上体验:
下载和部署ComfyUI(A10)
Clone代码,并安装相关依赖,链接如下:
https://github.com/Suzie1/ComfyUI_Comfyroll_CustomNodes
https://github.com/rgthree/rgthree-comfy
https://github.com/JPS-GER/ComfyUI_JPS-Nodes
https://github.com/pythongosssss/ComfyUI-Custom-Scripts
https://github.com/kijai/ComfyUI-KJNodes
https://github.com/XLabs-AI/x-flux-comfyui
# #@title Environment Setup
from pathlib import Path
OPTIONS = {}
UPDATE_COMFY_UI = True #@param {type:"boolean"}
INSTALL_COMFYUI_MANAGER = True #@param {type:"boolean"}
INSTALL_CUSTOM_NODES_DEPENDENCIES = True #@param {type:"boolean"}
INSTALL_ComfyUI_CustomNodes = True #@param {type:"boolean"}
INSTALL_x_flux_comfyui = True #@param {type:"boolean"}
OPTIONS['UPDATE_COMFY_UI'] = UPDATE_COMFY_UI
OPTIONS['INSTALL_COMFYUI_MANAGER'] = INSTALL_COMFYUI_MANAGER
OPTIONS['INSTALL_CUSTOM_NODES_DEPENDENCIES'] = INSTALL_CUSTOM_NODES_DEPENDENCIES
OPTIONS['INSTALL_ComfyUI_CustomNodes'] = INSTALL_ComfyUI_CustomNodes
OPTIONS['INSTALL_x_flux_comfyui'] = INSTALL_x_flux_comfyui
current_dir = !pwd
WORKSPACE = f"{current_dir[0]}/ComfyUI"
%cd /mnt/workspace/
![ ! -d $WORKSPACE ] && echo -= Initial setup ComfyUI =- && git clone https://github.com/comfyanonymous/ComfyUI
%cd $WORKSPACE
if OPTIONS['UPDATE_COMFY_UI']:
!echo "-= Updating ComfyUI =-"
!git pull
if OPTIONS['INSTALL_COMFYUI_MANAGER']:
%cd custom_nodes
![ ! -d ComfyUI-Manager ] && echo -= Initial setup ComfyUI-Manager =- && git clone https://github.com/ltdrdata/ComfyUI-Manager
%cd ComfyUI-Manager
!git pull
if OPTIONS['INSTALL_ComfyUI_CustomNodes']:
%cd ..
!echo -= Initial setup ComfyUI_Comfyroll_CustomNodes =- && git clone https://github.com/Suzie1/ComfyUI_Comfyroll_CustomNodes.git
!echo -= Initial setup ComfyUI_rgthree_comfy =- && git clone https://github.com/rgthree/rgthree-comfy.git
!echo -= Initial setup ComfyUI_JPS =- && git clone https://github.com/JPS-GER/ComfyUI_JPS-Nodes.git
!echo -= Initial setup ComfyUI_Custom_Scripts =- && git clone https://github.com/pythongosssss/ComfyUI-Custom-Scripts.git
!echo -= Initial setup ComfyUI-KJNodes =- && git clone https://github.com/kijai/ComfyUI-KJNodes.git
if OPTIONS['INSTALL_x_flux_comfyui']:
!echo -= Initial setup x-flux-comfyui =- && git clone https://github.com/XLabs-AI/x-flux-comfyui.git
if OPTIONS['INSTALL_CUSTOM_NODES_DEPENDENCIES']:
!pwd
!echo "-= Install custom nodes dependencies =-"
![ -f "custom_nodes/ComfyUI-Manager/scripts/colab-dependencies.py" ] && python "custom_nodes/ComfyUI-Manager/scripts/colab-dependencies.py"
!pip install spandrel
下载模型(包含FLUX.1基础模型fp8版本,encoder模型,vae模型,LoRA模型如FLUX.1-Turbo-Alpha,Controlnet如FLUX.1-dev-Controlnet-Inpainting-Beta等),并存放到models目录的相关子目录下。小伙伴们可以选择自己希望使用的模型并下载。
#@markdown ###Download #@markdown ###Download standard resources
%cd /mnt/workspace/ComfyUI
### FLUX1-DEV
# !modelscope download --model=AI-ModelScope/FLUX.1-dev --local_dir ./models/unet/ flux1-dev.safetensors
!modelscope download --model=AI-ModelScope/flux-fp8 --local_dir ./models/unet/ flux1-dev-fp8.safetensors
### clip
!modelscope download --model=AI-ModelScope/flux_text_encoders --local_dir ./models/clip/ clip_l.safetensors
!modelscope download --model=AI-ModelScope/flux_text_encoders --local_dir ./models/clip/ t5xxl_fp8_e4m3fn.safetensors
### vae
!modelscope download --model=AI-ModelScope/FLUX.1-dev --local_dir ./models/vae/ ae.safetensors
### lora
!modelscope download --model=alimama-creative/FLUX.1-Turbo-Alpha --local_dir ./models/loras/ diffusion_pytorch_model.safetensors
### Controlnet
!modelscope download --model=alimama-creative/FLUX.1-dev-Controlnet-Inpainting-Beta --local_dir ./models/controlnet diffusion_pytorch_model.safetensors resources%cd /mnt/workspace/ComfyUI### FLUX1-DEV# !modelscope download --model=AI-ModelScope/FLUX.1-dev --local_dir ./models/unet/ flux1-dev.safetensors!modelscope download --model=AI-ModelScope/flux-fp8 --local_dir ./models/unet/ flux1-dev-fp8.safetensors### clip!modelscope download --model=AI-ModelScope/flux_text_encoders --local_dir ./models/clip/ clip_l.safetensors!modelscope download --model=AI-ModelScope/flux_text_encoders --local_dir ./models/clip/ t5xxl_fp8_e4m3fn.safetensors### vae!modelscope download --model=AI-ModelScope/FLUX.1-dev --local_dir ./models/vae/ ae.safetensors### lora!modelscope download --model=alimama-creative/FLUX.1-Turbo-Alpha --local_dir ./models/loras/ diffusion_pytorch_model.safetensors### Controlnet!modelscope download --model=alimama-creative/FLUX.1-dev-Controlnet-Inpainting-Beta --local_dir ./models/controlnet diffusion_pytorch_model.safetensors
使用cloudflared运行ComfyUI
!wget "https://modelscope.oss-cn-beijing.aliyuncs.com/resource/cloudflared-linux-amd64.deb"
!dpkg -i cloudflared-linux-amd64.deb
%cd /mnt/workspace/ComfyUI
import subprocess
import threading
import time
import socket
import urllib.request
def iframe_thread(port):
while True:
time.sleep(0.5)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
result = sock.connect_ex(('127.0.0.1', port))
if result == 0:
break
sock.close()
print("\nComfyUI finished loading, trying to launch cloudflared (if it gets stuck here cloudflared is having issues)\n")
p = subprocess.Popen(["cloudflared", "tunnel", "--url", "http://127.0.0.1:{}".format(port)], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
for line in p.stderr:
l = line.decode()
if "trycloudflare.com " in l:
print("This is the URL to access ComfyUI:", l[l.find("http"):], end='')
#print(l, end='')
threading.Thread(target=iframe_thread, daemon=True, args=(8188,)).start()
!python main.py --dont-print-server
load ComfyUI流程图,链接:
t2I_flux_turbo加速生图:
https://modelscope.cn/models/alimama-creative/FLUX.1-Turbo-Alpha/resolve/master/workflows/t2I_flux_turbo.json
inpainting加速生图:
https://modelscope.cn/models/alimama-creative/FLUX.1-Turbo-Alpha/resolve/master/workflows/alimama_flux_inpainting_turbo_8step.json
t2I_flux_turbo加速生图流程图如下:
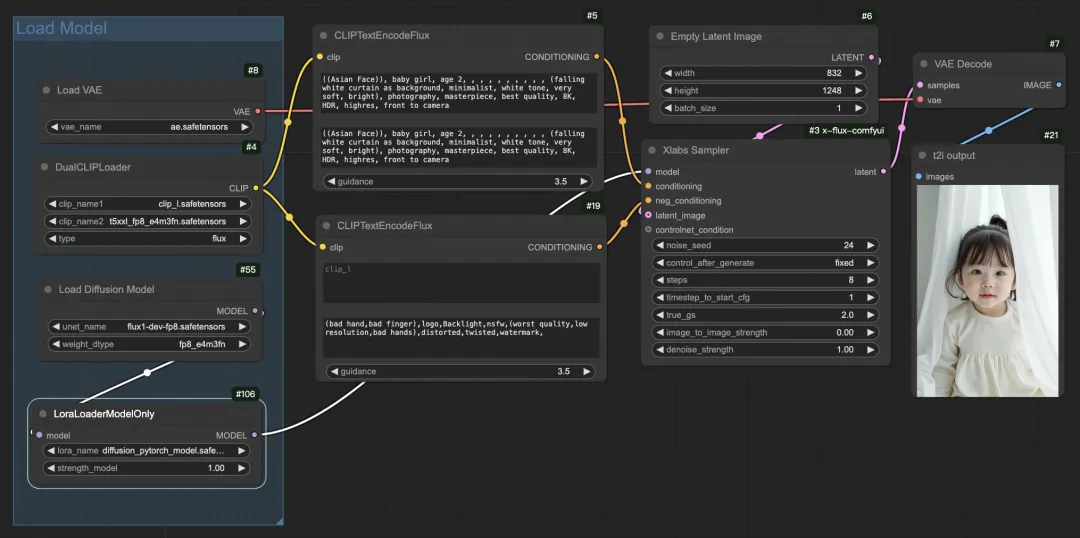
inpainting加速生图流程图如下:
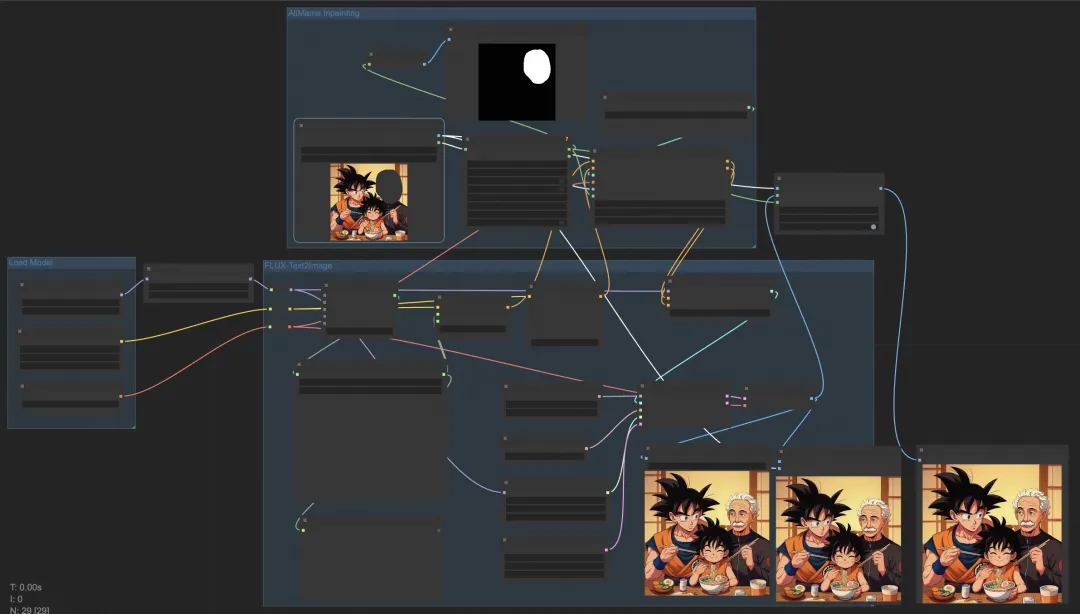
显存占用:
05
总结
本文介绍了阿里妈妈技术团队基于FLUX开发的Controlnet修复模型和蒸馏加速模型,填补了社区空白并提升了FLUX的实用性和效率。未来研究团队将着力提高复杂纹理和结构的理解生成能力,增加多尺寸支持,探索4步生图的加速方案。研究团队相信,持续创新将使FLUX在AI创意生成等众多领域发挥更大潜力。
引用
[1] https://github.com/black-forest-labs/flux
[2]Lipman Y, Chen R T Q, Ben-Hamu H, et al. Flow matching for generative modeling[J]. arXiv preprint arXiv:2210.02747, 2022.
[3]Zhang L, Rao A, Agrawala M. Adding conditional control to text-to-image diffusion models[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 3836-3847.
[4] https://huggingface.co/diffusers/stable-diffusion-xl-1.0-inpainting-0.1
[5] Luo S, Tan Y, Huang L, et al. Latent consistency models: Synthesizing high-resolution images with few-step inference[J]. arXiv preprint arXiv:2310.04378, 2023.
点击链接👇,直达原文
https://www.modelscope.cn/models/alimama-creative/FLUX.1-Turbo-Alpha?from=csdnzishequ_text?from=csdnzishequ_text

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献644条内容
已为社区贡献644条内容

所有评论(0)