
Qwen2.0正式开源及评测数据集理解
6月7日,阿里巴巴正式开源了大模型——Qwen2。同时官方网站给出了与其他大模型,在不同的基准测试数据集上的对比。本文将介绍如何理解这些常用的基准测试数据集。
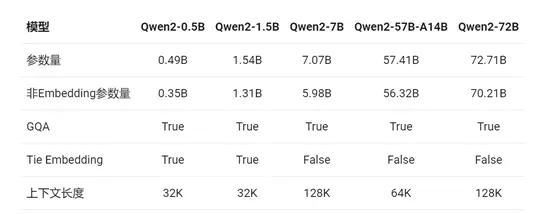
6月7日,阿里巴巴正式开源了大模型——Qwen2。Qwen2一共有5种预训练和指令微调模型,包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B。

与相比Qwen1.5,Qwen2的性能实现大幅度提升。在测试数据方面,在针对预训练语言模型的评估中,对比当前最优的开源模型,Qwen2-72B在包括自然语言理解、知识、代码、数学及多语言等多项能力上均显著超越当前领先的模型,例如,Llama-3-70B以及Qwen1.5最大的模型Qwen1.5-110B,主要益于预训练数据及训练方法的优化。
| Datasets | Llama-3-70B-Instruct | Qwen1.5-72B-Chat | Qwen2-72B-Instruct |
| English | |||
| MMLU | 82.0 | 75.6 | 82.3 |
| MMLU-Pro | 56.2 | 51.7 | 64.4 |
| GPQA | 41.9 | 39.4 | 42.4 |
| TheroemQA | 42.5 | 28.8 | 44.4 |
| MT-Bench | 8.95 | 8.61 | 9.12 |
| Arena-Hard | 41.1 | 36.1 | 48.1 |
| IFEval (Prompt Strict-Acc.) | 77.3 | 55.8 | 77.6 |
| Coding | |||
| HumanEval | 81.7 | 71.3 | 86.0 |
| MBPP | 82.3 | 71.9 | 80.2 |
| MultiPL-E | 63.4 | 48.1 | 69.2 |
| EvalPlus | 75.2 | 66.9 | 79.0 |
| LiveCodeBench | 29.3 | 17.9 | 35.7 |
| Mathematics | |||
| GSM8K | 93.0 | 82.7 | 91.1 |
| MATH | 50.4 | 42.5 | 59.7 |
| Chinese | |||
| C-Eval | 61.6 | 76.1 | 83.8 |
| AlignBench | 7.42 | 7.28 | 8.27 |
来自:魔搭社区
另外,在7B参数版本,也与业内相同量级参数的大模型做了比较,参考如下:
| Datasets | Llama-3-8B-Instruct | Yi-1.5-9B-Chat | GLM-4-9B-Chat | Qwen1.5-7B-Chat | Qwen2-7B-Instruct |
| English | |||||
| MMLU | 68.4 | 69.5 | 72.4 | 59.5 | 70.5 |
| MMLU-Pro | 41.0 | - | - | 29.1 | 44.1 |
| GPQA | 34.2 | - | - | 27.8 | 25.3 |
| TheroemQA | 23.0 | - | - | 14.1 | 25.3 |
| MT-Bench | 8.05 | 8.20 | 8.35 | 7.60 | 8.41 |
| Coding | |||||
| Humaneval | 62.2 | 66.5 | 71.8 | 46.3 | 79.9 |
| MBPP | 67.9 | - | - | 48.9 | 67.2 |
| MultiPL-E | 48.5 | - | - | 27.2 | 59.1 |
| Evalplus | 60.9 | - | - | 44.8 | 70.3 |
| LiveCodeBench | 17.3 | - | - | 6.0 | 26.6 |
| Mathematics | |||||
| GSM8K | 79.6 | 84.8 | 79.6 | 60.3 | 82.3 |
| MATH | 30.0 | 47.7 | 50.6 | 23.2 | 49.6 |
| Chinese | |||||
| C-Eval | 45.9 | - | 75.6 | 67.3 | 77.2 |
| AlignBench | 6.20 | 6.90 | 7.01 | 6.20 | 7.21 |
来自:魔搭社区
这些评测集合分别是什么含义? 初学者而言,可能会觉得不知所云,无从理解。这里将给以简单介绍说明,方便理解。
英文测试(考试和推理)
MMLU (Massive Multi-task Language Understanding,大规模多任务语言理解)
- 特点:MMLU是一个大规模的基准测试,旨在评估模型在零次学习和少次学习设置下获得的知识。它涵盖了STEM、人文科学、社会科学等57个科目,难度从初级到高级专业水平不等。
- 一句话介绍:MMLU是一个多学科的基准测试,用于衡量模型在广泛领域的知识和推理能力。
- 网站链接:https://paperswithcode.com/dataset/mmlu
MMLU-Pro
- 特点:MMLU-Pro是MMLU的升级版,旨在通过更复杂的问题和更多的选项来更严格地评估大型语言模型。它包含来自各个学科领域的1.2万个复杂问题,每个问题有10个答案选项,且增加了更多以推理为重点的问题。
- 一句话介绍:MMLU-Pro是一个更具挑战性和复杂性的基准测试,用于评估大型语言模型的高级推理能力。
GPQA
- 特点:全称为"Graduate-Level Google-Proof Q&A Benchmark",是一个由纽约大学的研究者提出的具有挑战性的数据集。这个数据集包含448个多项选择题,由生物学、物理学和化学领域的专家编写。GPQA数据集的设计考虑了专家与非专家之间的知识差距,通过让专家编写问题并验证答案的客观性,同时让非专家尝试解决问题,确保了问题的挑战性和广泛性。即便是在该领域已取得或正在攻读博士学位的专家,正确率也只有65%,显示了其难度。
- 一句话介绍:GPQA是一个由专家和非专家共同创建的高质量、高难度的问答数据集。
- 网站链接:arXiv - CS - Artificial IntelligencePub Date : 2023-11-20, DOI: arxiv-2311.12022 David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, Samuel R. Bowman
TheoremQA(Chen,2023a):一个由 STEM 定理驱动的问答数据集,包含 800 个 QA 对,涵盖数学、EE&CS、物理和金融领域的 350 多个定理。它测试了大语言模型在应用定理解决具有挑战性大学级问题方面的局限性。
MT-Bench: 为一个多轮对话数据集,用于测试模型的对话和遵循指令的能力,包含80条数据。
编码能力(Coding):
HumanEval: Hand-Written Evaluation Set,是工作《Evaluating Large Language Models Trained on Code》(https://arxiv.org/abs/2107.03374)中提到的一个代码评测基准。一共包括164条样本,还是很少量的,可以用json进行更为直观的理解,地址:https://github.com/abacaj/code-eval/blob/main/human-eval/data/HumanEval.jsonl.gz
MBPP(Math-Bench Python Programming dataset)数据集由 Google 等研究人员开发,包含约1000个众包的 Python 编程问题,设计为可由初级程序员解决,覆盖编程基础和标准库功能等。每个问题包括任务描述、代码解决方案和3个自动化测试用例。MBPP 数据集用于测试大语言模型从自然语言描述中生成 Python 代码的能力。
MultiPL-E: 是一个多编程语言基准测试,用于评估大型语言模型(LLMs)的代码生成性能。它使用了 OpenAI 的 HumanEval 数据集和 MBPP Python 基准测试,并使用小型编译器将它们转换为其他语言,支持18种编程语言的评估。MultiPL-E 旨在提供一种可扩展和多语言的方法来评估神经代码生成。
Evalplus: 用于LLM合成代码的严谨性评估。它是LLM4Code的严格评估框架,具有:
✨ HumanEval+:比原来的HumanEval多80倍的测试!
✨ MBPP+:比原来的MBPP多35倍的测试!
✨ 评估框架:我们的包/图像/工具可以在上述基准上轻松、安全地评估LLM。
LiveCodeBench:全面无污染评估大型语言模型的代码能力
大语言模型(LLMs)应用在与代码相关的应用上已经成为一个突出的领域,吸引了学术界和工业界的极大兴趣。然而,随着新的和改进的LLMs的开发,现有的评估基准(如HumanEval、MBPP)已不再足以评估它们的能力。在这项工作中,我们提出了LiveCodeBench,一个对代码语言模型进行全面和无污染的评估,它持续从三个竞赛平台(LeetCode、AtCoder和CodeForces)中收集新问题。值得注意的是,我们的基准还关注更广泛范围的代码相关能力,如自我修复、代码执行和测试输出预测,而不仅仅是代码生成。目前,LiveCodeBench收录了2023年5月至2024年2月间发布的四百个高质量编程问题。我们在LiveCodeBench上评估了9个基础LLMs和20个指令调整的LLMs。我们提供了关于污染、整体性能比较、现有基准中可能存在的过拟合以及单个模型比较的经验性发现。我们将发布所有提示和模型完成结果,供社区进一步分析,同时还提供一个通用工具包,用于添加新场景和模型。
链接:http://arxiv.org/abs/2403.07974v1
数学(Mathematics):
GSM8K
https://github.com/OFA-Sys/gsm8k-ScRel
https://huggingface.co/datasets/gsm8k
GSM8K(小学数学 8K)是一个包含 8.5K 高质量语言多样化小学数学单词问题的数据集。创建该数据集是为了支持对需要多步骤推理的基本数学问题进行问答的任务。
GSM8K 是一个高质量的英文小学数学问题测试集,包含 7.5K 训练数据和 1K 测试数据。这些问题通常需要 2-8 步才能解决,有效评估了数学与逻辑能力。
MATH
https://github.com/hendrycks/math
MATH 是一个由数学竞赛问题组成的评测集,由 AMC 10、AMC 12 和 AIME 等组成,包含 7.5K 训练数据和 5K 测试数据。
中文测试(Chinese)
C-Eval
中文数据集:https://cevalbenchmark.com/
使用教程:https://github.com/hkust-nlp/ceval/blob/main/README_zh.md
C-Eval是一个全面的中文基础模型评测数据集,它包含了 13948 个多项选择题,涵盖了 52 个学科和四个难度级别。
通常你可以直接从模型的生成中使用正则表达式提取出答案选项(A,B,C,D)。在少样本测试中,模型通常会遵循少样本给出的固定格式,所以提取答案很简单。然而有时候,特别是零样本测试和面对没有做过指令微调的模型时,模型可能无法很好的理解指令,甚至有时不会回答问题。这种情况下我们推荐直接计算下一个预测token等于"A", "B", "C", "D"的概率,然后以概率最大的选项作为答案 -- 这是一种受限解码生成的方法,MMLU的官方测试代码中是使用了这种方法进行测试。注意这种概率方法对思维链的测试不适用。更加详细的评测教程。
AlignBench
GitHub - kekewind/AlignBench: 多维度中文对齐评测基准 | Benchmarking Chinese Alignment of LLMs
智谱AI发布了专为中文大语言模型(LLM)而生的对齐评测基准AlignBench。AlignBench 的数据集来自于真实的使用场景,经过初步构造、敏感性筛查、参考答案生成和难度筛选等步骤,确保具有真实性和挑战性。数据集分为8个大类,包括知识问答、写作生成、角色扮演等多种类型的问题。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 36
36 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)