
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .

ExVideo+CogVideoX,更长、更优!再次升级的开源视频生成能力
DiffSynth-Studio 再次为 CogVideoX 带来新的增强模块——ExVideo-CogVideoX-LoRA-129f-v1
·
上个月,DiffSynth-Studio 支持了 CogVideoX 模型,并提供了一系列配置拉满的生成能力,今天,DiffSynth-Studio 再次为 CogVideoX 带来新的增强模块——ExVideo-CogVideoX-LoRA-129f-v1,这个模块沿用了 ExVideo 的设计思路,通过后训练(post-training)来扩展模型的能力,让模型能够生成更长的视频。
01
样例展示
我们来看几个样例!先是跟随无人机从皑皑雪山的上空掠过,俯瞰雪域盛景。

再是来到万籁俱寂的极地,欣赏如梦似幻的极光与斗转星移的夜空。

然后穿越到遥远的火星,穿上宇航服,坐在马背上,踏入科幻电影的想象世界!

累了,就回家陪陪家人吧~

想必大家已经领略到了这个模型的魅力,这个模型能够生成 16 秒的长视频。

16 秒有多长呢?我们用最后一个例子说明。我们生成两个人握手的画面,是的,连续握手 16 秒!视频中左侧的角色在视频结尾已经握手握到不想握了,露出了生无可恋的有趣表情。
02
模型介绍
这个模型是基于两个模型构建的——CogVideoX-5B 和 ExVideo-SVD,CogVideoX-5B 是由智谱团队开源的文生视频模型,我们在往期文章中对这个模型做过详细介绍。这个模型是目前开源模型中很强大的视频生成模型,感兴趣的同学可以在魔搭社区下载和体验这个模型。

模型链接:
https://modelscope.cn/models/ZhipuAI/CogVideoX-5b
模型Demo体验:
https://www.modelscope.cn/studios/ZhipuAI/CogVideoX-5b-demo

而 ExVideo 则是由魔搭社区的 DiffSynth-Studio 团队提出的视频生成模型“后训练”(post-training)方法,ExVideo 通过在视频生成模型的基础上添加额外的扩展模块并继续进行训练,大幅度增加模型能够生成的视频长度。此前,DiffSynth-Studio 团队开源了模型 ExVideo-SVD,在模型 Stable Video Diffusion 上验证了训练方案的可行性。

模型链接:
-
ExVideo-SVD
https://modelscope.cn/models/ECNU-CILab/ExVideo-SVD-128f-v1
-
stable-video-diffusion-img2vid-xt
https://modelscope.cn/models/ai-modelscope/stable-video-diffusion-img2vid-xt
而今天的新模型,则是这两个模型的结合,利用 ExVideo 扩展训练的思路,增强 CogVideoX-5B 模型的生成能力。由于 CogVideoX-5B 是基于 DiT 的模型结构,与 Stable Video Diffusion 模型不同,没有卷积部分,取而代之的是大量全连接层,所以 LoRA 很适合作为扩展模块的架构,这次的模型正是以 LoRA 的形式发布。
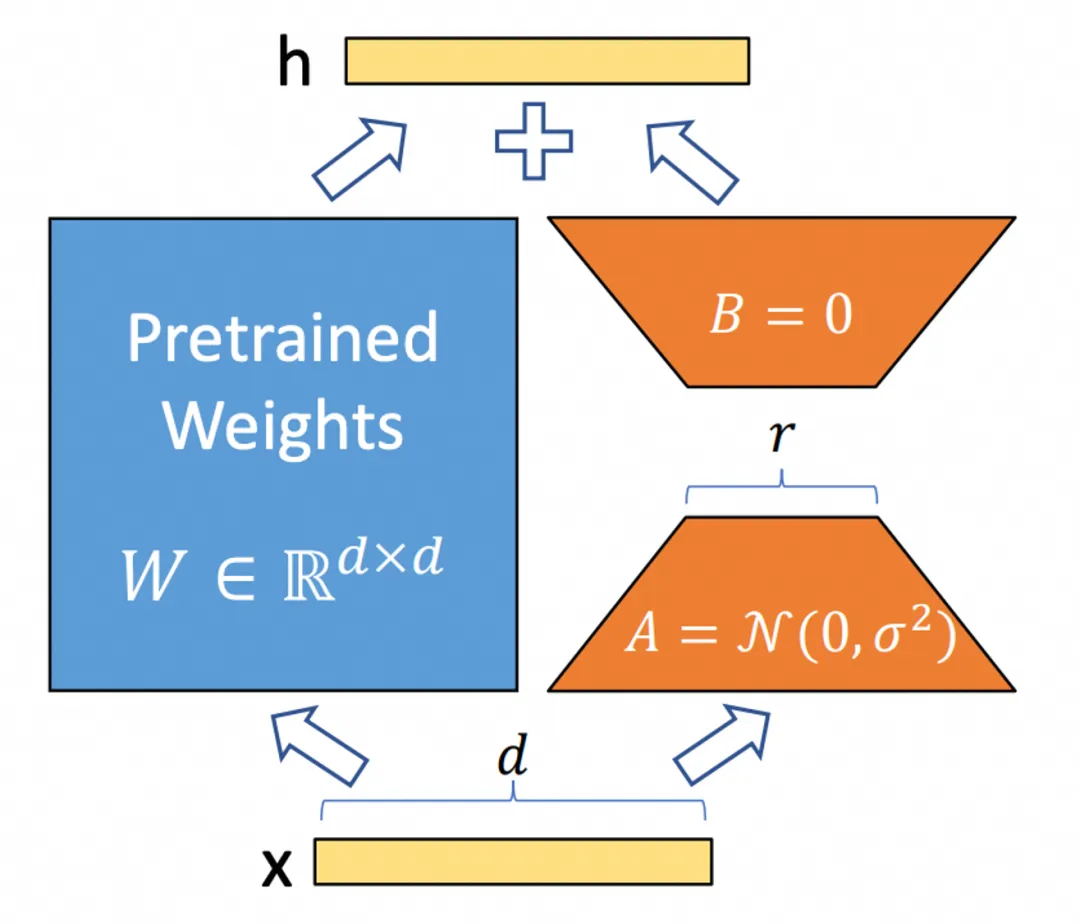
在 CogVideoX-5B 上实现扩展训练的难点在于,加长的视频数据大幅度增加了显存的需求。原本的模型支持生成 49 帧(由于模型结构限制,第一帧单独编码,因此帧数为 4 的倍数 +1)视频,把视频加长到 129 帧后,即使是 80G 显存的显卡也无法训练。DiffSynth-Studio 团队为此做了很多工程优化,包括:
-
Parameter freezing:冻结除了扩展模块以外的所有参数
-
Mixed precision:扩展模块部分以全精度维护,其他部分以 BFloat16 精度维护
-
Gradient checkpointing:在前向传播时丢弃中间变量,并反向传播时重新计算
-
Flash attention:在所有注意力机制上启用加速过的注意力实现
-
Shard optimizer states and gradients:基于 DeepSpeed 把部分参数分拆到多个 GPU 上
-
Text Encoder & VAE offload:将 Text Encoder 和 VAE 的相关计算拆分运行,训练进程仅加载 DiT
训练数据集包括 InternVid 和 Panda70M 中的数千个视频,该模型在 8*A100 上训练了数天,最终得到了大家目前看到的版本。对比一下不加 ExVideo 扩展模块的模型,原模型在生成长视频时出现了明显的细节缺失,ExVideo 扩展模块非常显著地提升了画面的细节。
不使用 ExVideo 扩展模块 使用 ExVideo 扩展模块


03
模型体验
下载并安装 DiffSynth-Studio:
运行样例脚本(模型会自动下载):
from diffsynth import ModelManager, CogVideoPipeline, save_video, download_models
import torch
download_models(["CogVideoX-5B", "ExVideo-CogVideoX-LoRA-129f-v1"])
model_manager = ModelManager(torch_dtype=torch.bfloat16)
model_manager.load_models([
"models/CogVideo/CogVideoX-5b/text_encoder",
"models/CogVideo/CogVideoX-5b/transformer",
"models/CogVideo/CogVideoX-5b/vae/diffusion_pytorch_model.safetensors",
])
model_manager.load_lora("models/lora/ExVideo-CogVideoX-LoRA-129f-v1.safetensors")
pipe = CogVideoPipeline.from_model_manager(model_manager)
torch.manual_seed(6)
video = pipe(
prompt="an astronaut riding a horse on Mars.",
height=480, width=720, num_frames=129,
cfg_scale=7.0, num_inference_steps=100,
)
save_video(video, "video_with_lora.mp4", fps=8, quality=5)
DiffSynth-Studio开源项目:
https://github.com/modelscope/DiffSynth-Studio
(点击链接👇直达,欢迎star)
https://modelscope.cn/models/ZhipuAI/CogVideoX-5b?from=csdnzishequ_text

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献449条内容
已为社区贡献449条内容

所有评论(0)