
xGPU来啦!免费GPU资源开发花样AI应用!
为了降低AI应用服务和推广的门槛,解决开发者面临的实际痛点,ModelScope社区推出 xGPU 服务,让大家能够免费使用高性能 GPU 资源,托管自己的AI应用服务。
创意无限,却被GPU的“硬核瓶颈”卡住了吗?
GPU的强大算力是AI模型和应用的心脏,但高昂的云GPU租金和个人搭建服务器的成本让许多开发者望而却步。
为了降低AI应用服务和推广的门槛,解决开发者面临的实际痛点,ModelScope社区推出 xGPU 服务,让大家能够免费使用高性能 GPU 资源,托管自己的AI应用服务。
01
创空间xGPU介绍
什么是创空间?
创空间(Studio)是魔搭社区提供的AI模型应用服务模块,支持开发者基于魔搭上LLM,多模态,音视频等各种模态的模型,通过快捷的编程、以及零代码地通过交互式配置,实现AI应用的快速搭建。应用发布后,可以通过社区专属体验页进行分享。通过对接优秀的Gradio、Streamlit等开源框架,开发者可以通过熟悉的Python语言,迅速在创空间上搭建自己的AI应用,即便没有前端等全栈开发背景,也能完整的实现应用页面的搭建。同时魔搭社区开源的ModelScope-studio等项目,提供了插件式的能力组件,能更好支持不同用用场景的搭建。
什么是xGPU?
xGPU 是魔搭在创空间上提供的免费 GPU 共享服务,旨在为开发者和研究人员提供托管AI应用服务所需计算资源支持。与传统的云上专属GPU 资源不同,xGPU 通过动态 GPU 分配技术,使多个用户能够共享 GPU 资源,从而实现 GPU 资源的高效利用。基于这样的动态分配技术,使得魔搭社区可以为开发者提供免费的GPU使用,在避免资源浪费的同时,确保更多用户能够访问。
为什么选择 xGPU?
1. 免费,免费,免费!
重要的事情说三遍!是的,xGPU 完全免费!无需任何付费与订阅,GPU 计算能力就直接摆在你面前。无论您是个人开发者,还是创业团队,xGPU 都可以帮您在AI应用开发过程中,节省大量的资源成本。同时您也可以通过魔搭创空间的展示,作为AI应用的展示流量入口。
2. 主流开发生态的无缝衔接,无需代码改动
xGPU兼容常见的各种推理引擎、Python版本。能通过最新的Gradio SDK直接无缝接入,不用担心迁移麻烦。
3. 简单易用的集成方式
想象一下,使用 GPU 不再是一件繁琐的事情。你只需要在魔搭创空间发布过程中,或者配置页面上,选择所需的xGPU 资源即可启用。起来超轻松,还不担心花费!还等什么?速度来薅~
02
xGPU创空间上手指南
是不是已经迫不及待想试试啦,简单几步,就能立刻使用 xGPU:
1.注册魔搭账户:
直达👉 https://www.modelscope.cn/
2.加入xGPU乐园组织:目前xGPU功能处于Beta测试阶段,您可以通过申请加入xGPU乐园组织(https://www.modelscope.cn/organization/xGPU-Explorers),来开启xGPU的使用体验。提交申请审批后,我们会尽快与您沟通申请结果,请及时查收站内信或邮箱。
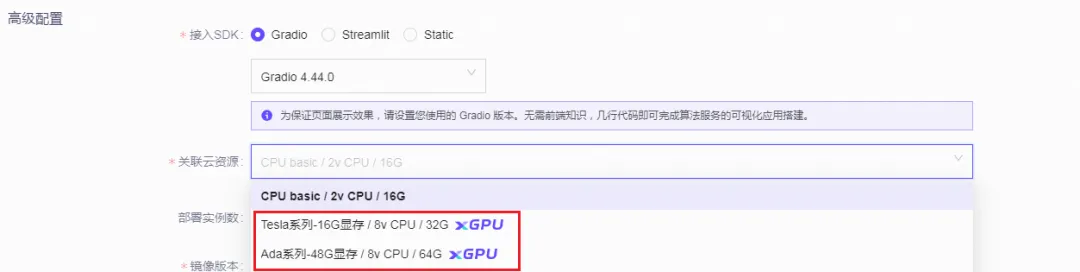
3.启用 GPU 计算:在新建创空间时,或者编辑已有创空间信息页面,通过选择“空间云资源”,来进行xGPU的资源配置。保存配置后重启即可使用xGPU。当前xGPU的免费算力包括Ada系GPU卡(48G显存)和Tesla系列(16G显存)等GPU类型,更多类型会在后续继续添加
4.发布并运行:一切准备就绪,发布项目,开始享受免费 GPU 资源吧!
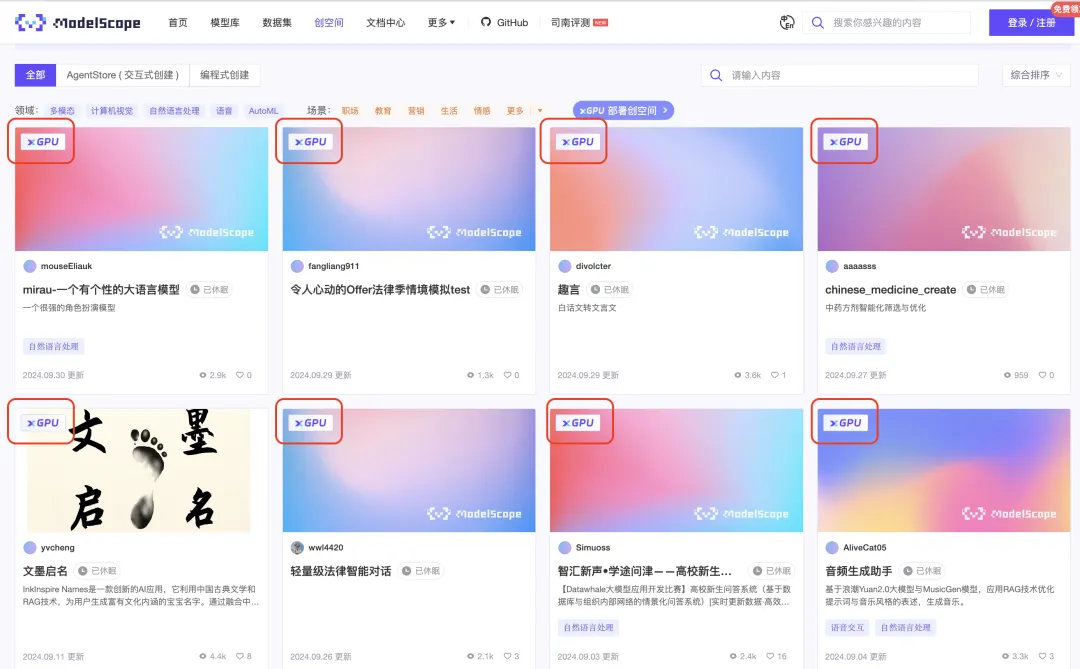
当前已经有一系列创空间先行用上了xGPU,您可以在创空间首页点击xGPU,或者直接点击下面链接,就可以查看社区当中搭建的公开xGPU创空间并进行体验。同时xGPU的创空间的空间卡片上,也会有特殊的xGPU的标记,方便您定位xGPU部署的应用。
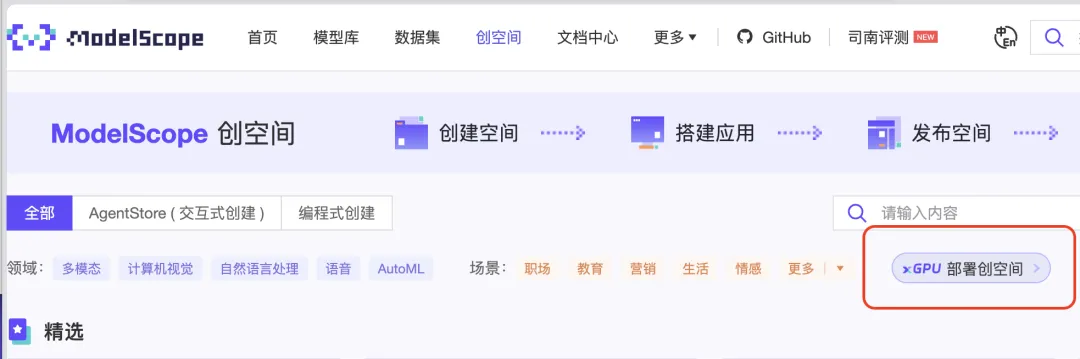
https://modelscope.cn/studios?page=1&type=interactive-programmatic&xGpu=true
03
xGPU技术实现
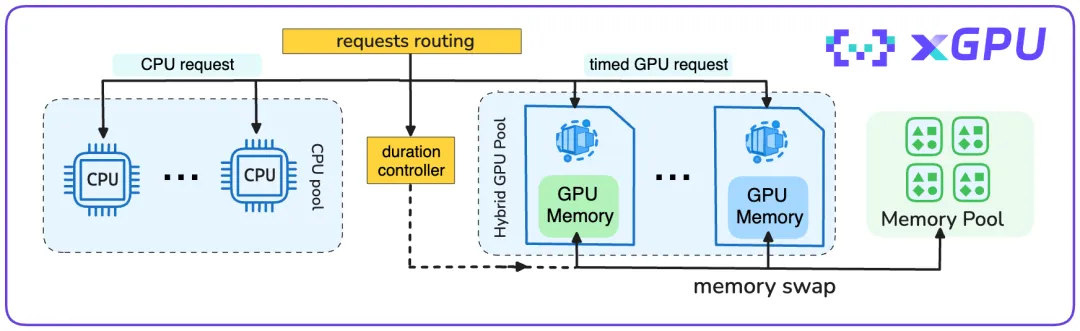
xGPU的调度基于阿里云的资源调度和虚拟化技术实现,将多个独立服务,相互隔离地运行在有多个GPU的机器上。基于云上多样化的GPU资源,xGPU提供了根据用户实时请求,进行实时GPU资源调度的能力。每个用户的请求,将会被按需调度到可用的GPU硬件上,并在必要的计算完成之后,迅速触发GPU资源的释放,来满足其他服务请求。
用户的请求进入时,创空间后台服务会针对请求的类型,进行分类的处理。对于非模型推理的请求,基于CPU计算和缓存技术将相关内容返回。模型推理类型请求则会被打上计时标签,并路由到GPU资源池,等待GPU运行后再给出结果。模型运行时可以根据不同因素(包括硬件空闲状态、预定持续时间等)在GPU显存和系统内存中进行交换。在推理类型请求结束后,模型运行时数据被移出GPU显存,将被存储在内存中用于下次GPU处理请求前的初始化,而相应的GPU可以立即被用于处理来自其他创空间的请求。通过这些灵活的自适应调度策略,xGPU能够在相对有限的GPU资源上,支持更多的创空间运行,让GPU资源惠及更多用户。
为了保障资源的高效使用和避免浪费,当前xGPU在使用上,会根据实际资源情况做一些动态限制,包括:
-
每个开发者基于xGPU能够创建的创空间有数量上限。同时高档的GPU免费使用时长和准入条件的控制,会更加严格。建议您在满足应用运行要求的情况下,基于“够用”的原则来选择xGPU的GPU卡型。
-
为保障资源使用的公平性,让更多用户来体验创空间应用,每个用户体验xGPU的时长有上限。
-
您也可以通过降低每次请求的耗时,以提高请求被调度的成功率。
-
在低频时段或较少用户访问的情况下,创空间将会自动休眠释放资源。
04
What's Next
1、扩大创空间xGPU上的开源SDK支持范围。当前xGPU率先支持了基于Gradio SDK开发的AI应用。后续将陆续引入Streamlit 等其他优秀开源生态支持。
2、引入更多优质的官方xGPU创空间,方便社区开发者交流体验.
3、增加xGPU平台资源弹性能力支持。平台将持续增强弹性资源扩展能力,提升支持的创空间规模,并进一步通过技术手段,降低用户等待时延,提升用户体验。
自从xGPU上线以来,我们已经看到第一批尝鲜使用的AI应用开发者,已经迅速达成GPU自由:
立即加入ModelScope社区的xGPU 乐园吧,让我们共同探索 AI 应用的无限可能性!未来的 AI 应用开发,你就是主角!
相关文档:
创空间概述:
https://www.modelscope.cn/docs/%E5%88%9B%E7%A9%BA%E9%97%B4%E4%BB%8B%E7%BB%8D
xGPU介绍:
https://www.modelscope.cn/docs/xGPU%E5%88%9B%E7%A9%BA%E9%97%B4%E4%BB%8B%E7%BB%8D
点击链接👇,直达更多xGPU详情
https://www.modelscope.cn/docs/xGPU%E5%88%9B%E7%A9%BA%E9%97%B4%E4%BB%8B%E7%BB%8D?from=csdnzishequ_text?from=csdnzishequ_text

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 0
0- 0



 已为社区贡献644条内容
已为社区贡献644条内容

所有评论(0)