
Qwen2.5系列大模型最新开源:兼看HyDE及MemoRAG实现思路
之前的HyDE(Hypothetical Document Embeddings,《Precise Zero-Shot Dense Retrieval without Relevance Labels》,http://arxiv.org/pdf/2212.10496),生成可用于回答用户输入问题的假设文档。这些文档来自LLM自身学习到的知识,向量化后用于从索引中检索文档。HyDE方法认为原始问题一
从HyDE说起看RAG
之前的HyDE(Hypothetical Document Embeddings,《Precise Zero-Shot Dense Retrieval without Relevance Labels》,http://arxiv.org/pdf/2212.10496),生成可用于回答用户输入问题的假设文档。这些文档来自LLM自身学习到的知识,向量化后用于从索引中检索文档。HyDE方法认为原始问题一般都比较短,而生成的假设文档可能会更好地与索引文档对齐。
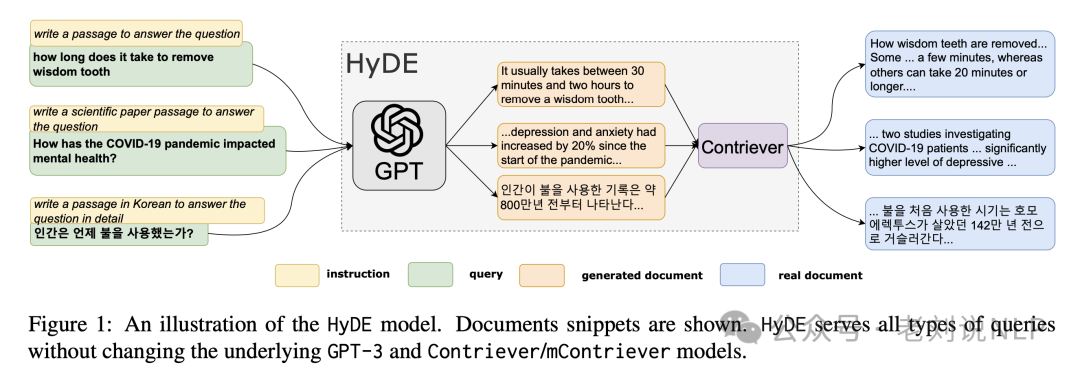
例如,langchain中其实也有对应的实现方式,可以看https://zhuanlan.zhihu.com/p/685943610:
1、HyDE document genration
from langchain.prompts import ChatPromptTemplate
# HyDE document genration
template = """Please write a scientific paper passage to answer the question
Question: {question}
Passage:"""
prompt_hyde = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
generate_docs_for_retrieval = (
prompt_hyde | ChatOpenAI(temperature=0) | StrOutputParser()
)
# Run
question = "What is task decomposition for LLM agents?"
generate_docs_for_retrieval.invoke({"question":question})
2、把LLM回答的一段话作为输入再去向量库检索。
# Retrieve
retrieval_chain = generate_docs_for_retrieval | retriever
retireved_docs = retrieval_chain.invoke({"question":question})
3、基于向量库检索得到的context回答原始问题。
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"context":retireved_docs,"question":question})
三、再看MemoRAG实现思路
关于RAG进展,《MemoRAG: Moving towards Next-Gen RAG Via Memory-Inspired Knowledge Discovery》,https://arxiv.org/pdf/2409.05591,这篇技术报告介绍了一个名为MemoRAG的新型检索增强生成系统。
其思想在于,通过长期记忆启发的知识发现来解决传统RAG系统在处理长文本和复杂任务时的局限性,底层逻辑是:从全局记忆中生成精确的线索,将原始输入与答案连接起来,并从复杂数据中解锁隐藏的洞察,这个思路其实不太新。
一句话说,就是,在接收用户查询后,MemoRAG先基于记忆生成模糊答案和答案线索,然后通过检索器补充答案细节,最终生成完整答案。
from memorag import MemoRAG
# Initialize MemoRAG pipeline
pipe = MemoRAG(
mem_model_name_or_path="TommyChien/memorag-mistral-7b-inst",
ret_model_name_or_path="BAAI/bge-m3",
gen_model_name_or_path="mistralai/Mistral-7B-Instruct-v0.2", # Optional: if not specify, use memery model as the generator
cache_dir="path_to_model_cache", # Optional: specify local model cache directory
access_token="hugging_face_access_token", # Optional: Hugging Face access token
beacon_ratio=4
)
context = open("examples/harry_potter.txt").read()
query = "How many times is the Chamber of Secrets opened in the book?"
# Memorize the context and save to cache
pipe.memorize(context, save_dir="cache/harry_potter/", print_stats=True)
# Generate response using the memorized context
res = pipe(context=context, query=query, task_type="memorag", max_new_tokens=256)
print(f"MemoRAG generated answer: \n{res}")
1、系统的对比
如下图所示,做了一个对比:
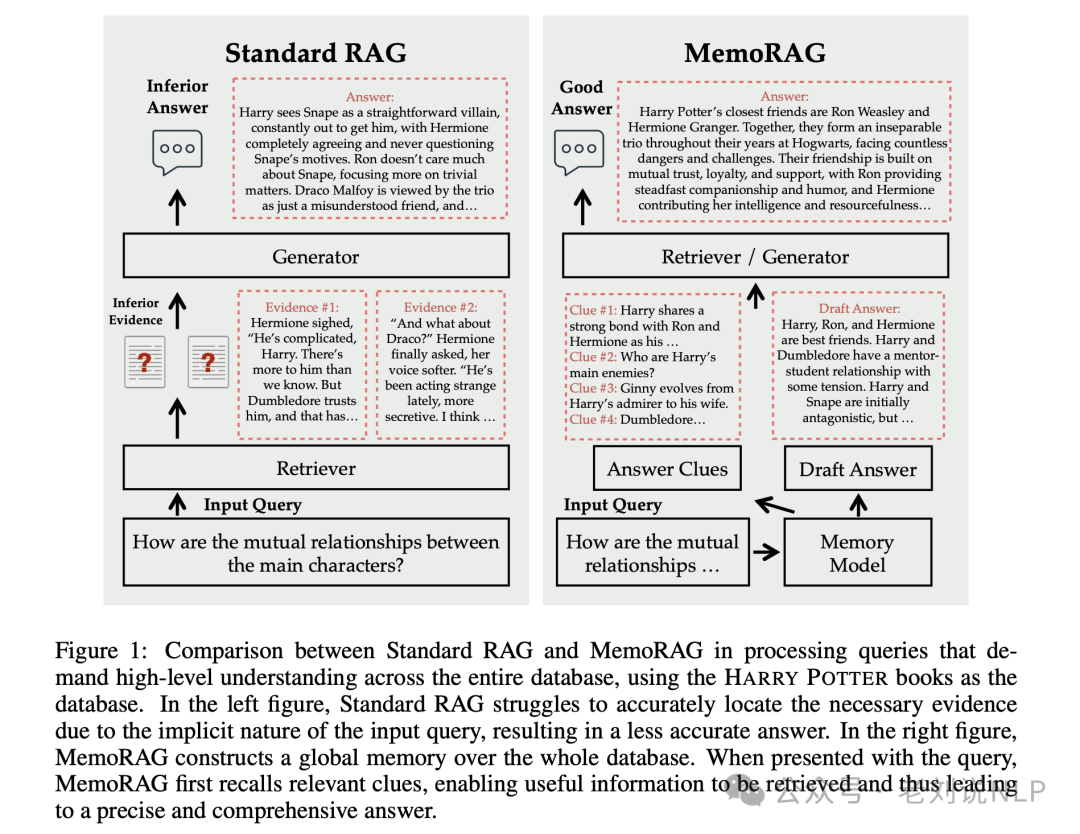
这张图展示了标准RAG(Retrieval-Augmented Generation)系统与 MemoRAG 系统在处理需要对整个数据库进行高级理解的查询时的比较。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

以《哈利·波特》系列书籍作为数据库的例子:
1)标准RAG系统
-
输入查询:询问“主要角色之间的相互关系如何?”
-
检索器:尝试根据输入查询检索相关信息。
-
生成器:基于检索到的信息生成答案。
-
答案:生成的答案可能不够准确或全面,例如“哈利将斯内普看作一个直接的反派,赫敏完全同意,从不质疑斯内普的动机。罗恩对斯内普不太关心,更关注琐碎的事情。德拉科·马尔福被三人组视为只是一个被误解的朋友。”
这种方式,存在的问题是:
-
检索到的证据:可能只关注了部分角色的表面关系,没有深入挖掘。
-
生成的答案:可能忽略了一些关键角色之间的复杂关系,如金妮从哈利的崇拜者变成了他的妻子等。
2)MemoRAG系统
-
输入查询:同样是关于《哈利·波特》主要角色之间相互关系的问题。
-
记忆模型:首先,MemoRAG构建一个全局记忆,覆盖整个数据库。
from memorag import Memory
Initialize the Memory model
memo_model = Memory( “TommyChien/memorag-qwen2-7b-inst”, cache_dir=“path_to_model_cache”, # Optional: specify local model cache directory beacon_ratio=4 # Adjust beacon ratio for handling longer contexts )
Load and memorize the context
context = open(“harry_potter.txt”).read() memo_model.memorize(context)
Save the memorized context to disk
memo_model.save(“cache/harry_potter/memory.bin”)
-
线索生成:当呈现查询时,MemoRAG利用其记忆模块生成检索线索(Answer Clues),这些线索本质上是基于数据库压缩表示的草稿答案。以图为例:
-
哈利与罗恩和赫敏有强烈的联系。
-
哈利的主要敌人是谁?
-
金妮从哈利的崇拜者变成了他的妻子。
-
邓布利多与哈利和斯内普的关系。
-
检索器/生成器:使用这些线索作为查询,MemoRAG可以有效地从数据库中检索必要的知识。
-
最终答案:基于检索到的证据文本生成最终答案,例如“哈利波特最亲密的朋友是罗恩·韦斯莱和赫敏·格兰杰。他们在整个霍格沃茨年代形成了一个不可分割的三人组,面对无数的危险和挑战。他们的友谊建立在相互信任、忠诚和支持的基础上,罗恩提供了坚定的陪伴和幽默,赫敏贡献了她的智慧和机智。”
在这种模式下,可以取得的效果是:
-
草稿答案:基于这些线索,MemoRAG 能够更全面地理解角色之间的关系,并检索到更准确的信息。
-
最终答案:提供了一个更全面、更深入的答案,涵盖了哈利与他的朋友们、敌人以及导师之间的关系。
又如:
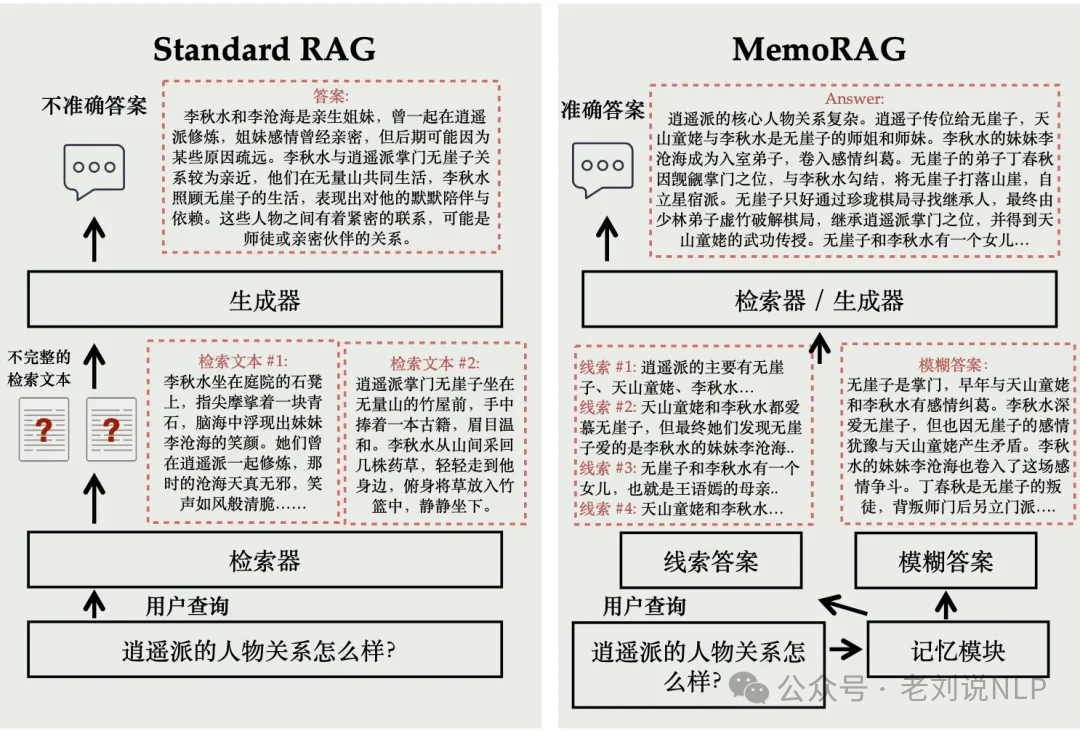
对于《天龙八部》小说中的人物关系问题,MemoRAG 会先对小说全文形成全局记忆。当接收到查询“逍遥派的人物关系怎么样?”时,MemoRAG 的记忆模块能够回忆出一个模糊答案,尽管缺乏细节,但能大致回应问题。同时,MemoRAG回忆出多个相关答案线索,并借助这些线索补充答案细节,最后基于准确的原文生成完整的回答。
2、训练细节
MemoRAG模型的训练过程主要包括两个阶段:预训练和监督微调(SFT)。
在预训练阶段,模型使用从RedPajama数据集中随机采样的长上下文进行训练。具体来说,这个阶段的目的是让MemoRAG的记忆模块学习如何从原始上下文中形成记忆。预训练过程中,模型通过处理长文本数据,学习如何将输入序列转换为紧凑的记忆表示,并在每个上下文窗口后添加记忆标记,以形成长期记忆。
在监督微调阶段,模型使用特定任务的数据进行训练,以生成任务相关的线索。这个阶段的训练目标是让模型能够基于形成的记忆生成任务特定的线索。具体来说,模型使用任务特定的SFT数据来微调新初始化的参数,使得生成的线索能够实现优化的检索质量。
记忆模块的训练目标是最大化给定前一个记忆标记的键值缓存和最近原始标记的下一个标记的生成概率。这个目标旨在通过记忆模块生成的线索,帮助系统更有效地从数据库中检索相关信息,从而提高最终答案的生成质量。
3、一个具体demo
在https://github.com/qhjqhj00/MemoRAG中的一个具体的例子,首先,需要加在对应的corpus, index以及memory,然后依次执行3个步骤:

step1:生成线索clue

step2:以线索clue作为evidence检索相应的passage

step3:根据检索到的passage,生成答案

3、模型地址
目前,MemoRAG 项目已开源了两种记忆模型,
基于Qwen2-7B-inst的模型:https://huggingface.co/TommyChien/memorag-qwen2-7b-inst
基于Mistral-7B-inst的模型:https://huggingface.co/TommyChien/memorag-mistral-7b-inst
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

{kind=link}
所有评论(0)