

前言
今天,Meta发布了 Llama 3.2,主要包括小型和中型视觉 LLM(11B 和 90B)以及适合边缘和端侧的轻量级纯文本模型(1B 和 3B),包括预训练和指令调整版本。Llama 3.2 1B 和 3B 模型支持 128K 令牌的上下文长度,在同类产品中处于较领先地位,适用于总结、指令跟踪和在边缘本地运行的重写任务等设备用例。Llama 3.2 11B 和 90B 视觉模型在图像理解任务上的表现优于封闭模型(例如 Claude 3 Haiku)。
Llama 3.2 系列 11B 和 90B 视觉LLM,支持图像理解,例如文档级理解(包括图表和图形)、图像字幕以及视觉基础任务(例如基于自然语言描述在图像中精确定位对象)。视觉LLM训练流程由多个阶段组成,从预训练的 Llama 3.1 文本模型开始。首先,添加图像适配器和编码器,然后在大规模噪声(图像、文本)对数据上进行预训练。接下来,在中等规模的高质量领域内和知识增强的(图像、文本)对数据上进行训练。在后期训练中,使用与文本模型类似的方法,在监督微调、拒绝采样和直接偏好优化方面进行多轮对齐。过程中利用 Llama 3.1 模型生成合成数据,在域内图像的基础上过滤和扩充问题和答案,并使用奖励模型对所有候选答案进行排名,以提供高质量的微调数据。
轻量级 1B 和 3B 模型具有较强的多语言文本生成和工具调用功能。可以轻松部署到端侧如手机或者PC,具有很强的隐私性,数据不会离开设备。1B 和 3B 模型上使用了两种方法(剪枝和蒸馏),使其成为能够高效适应设备的高性能轻量级 Llama 模型。剪枝能够缩小 Llama 群中现有模型的大小,同时尽可能多地恢复知识和性能。1B 和 3B 模型采用了从 Llama 3.1 8B 中一次性使用结构化修剪的方法。这涉及系统地移除网络的某些部分并调整权重和梯度的大小,以创建一个更小、更高效的模型,同时保留原始网络的性能。知识蒸馏使用较大的网络将知识传授给较小的网络,其理念是较小的模型使用教师可以获得比从头开始更好的性能。剪枝后使用知识蒸馏来恢复性能。
模型评估
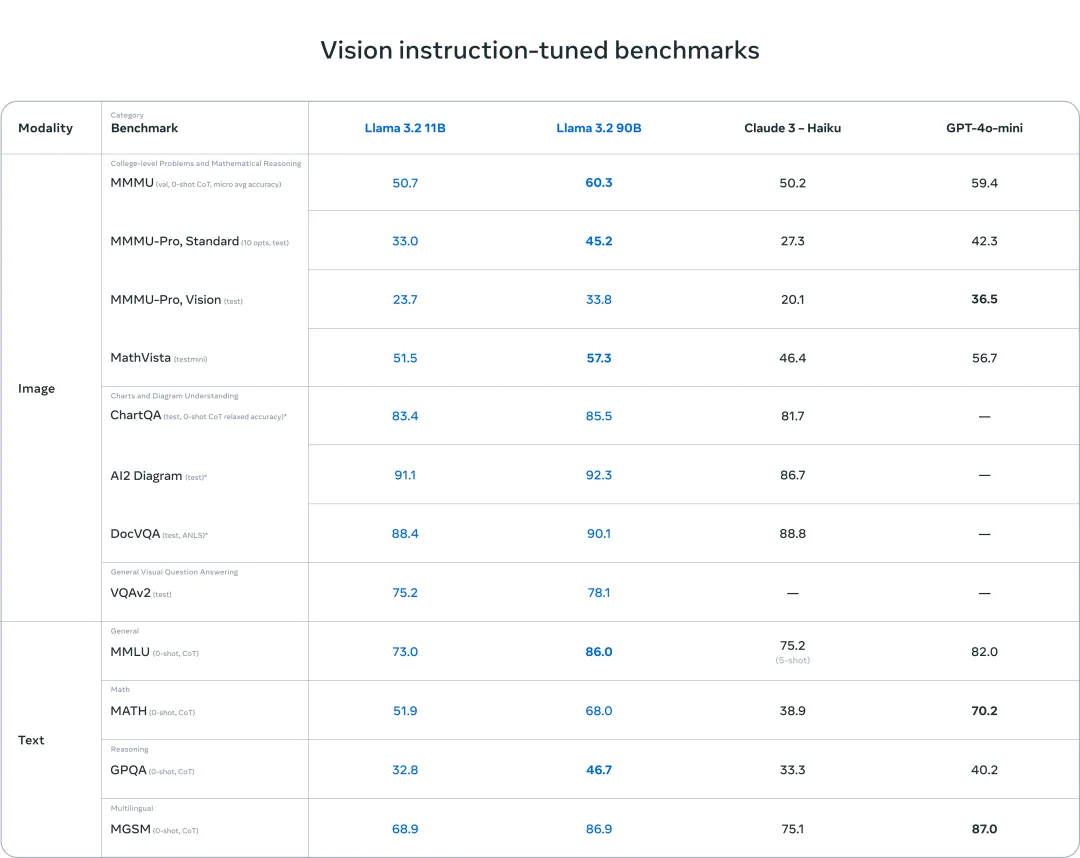
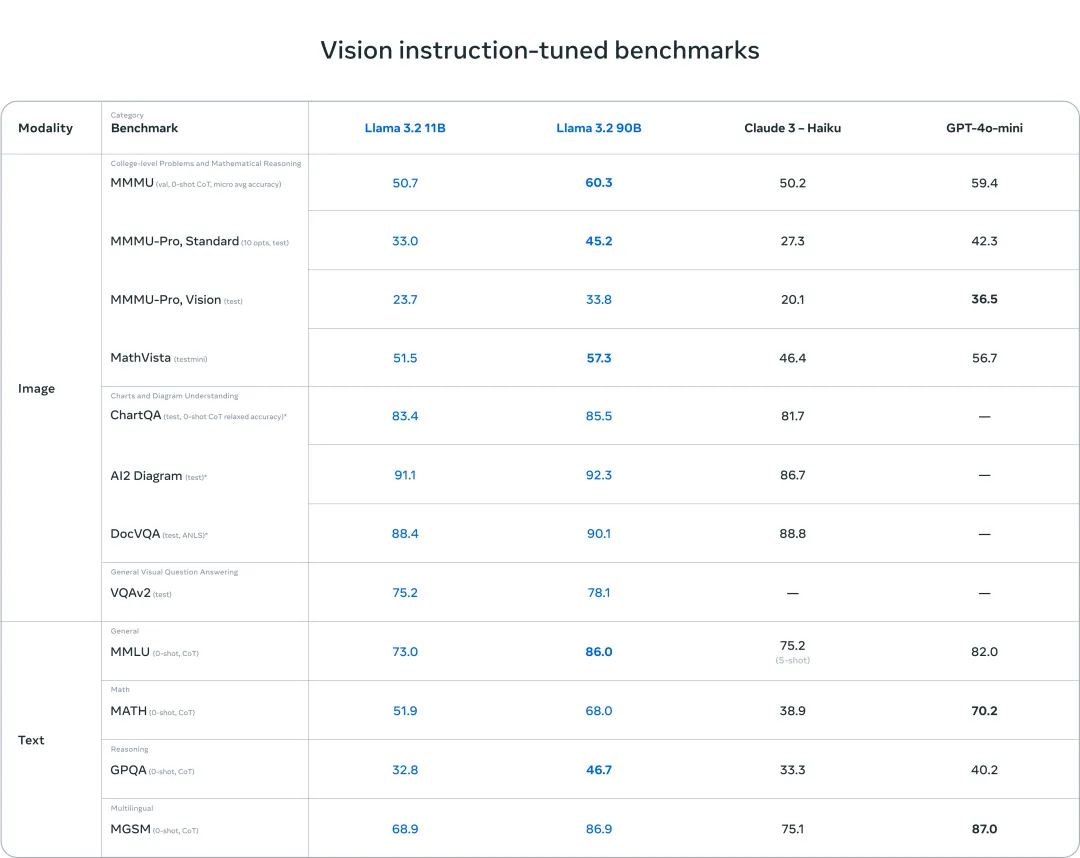
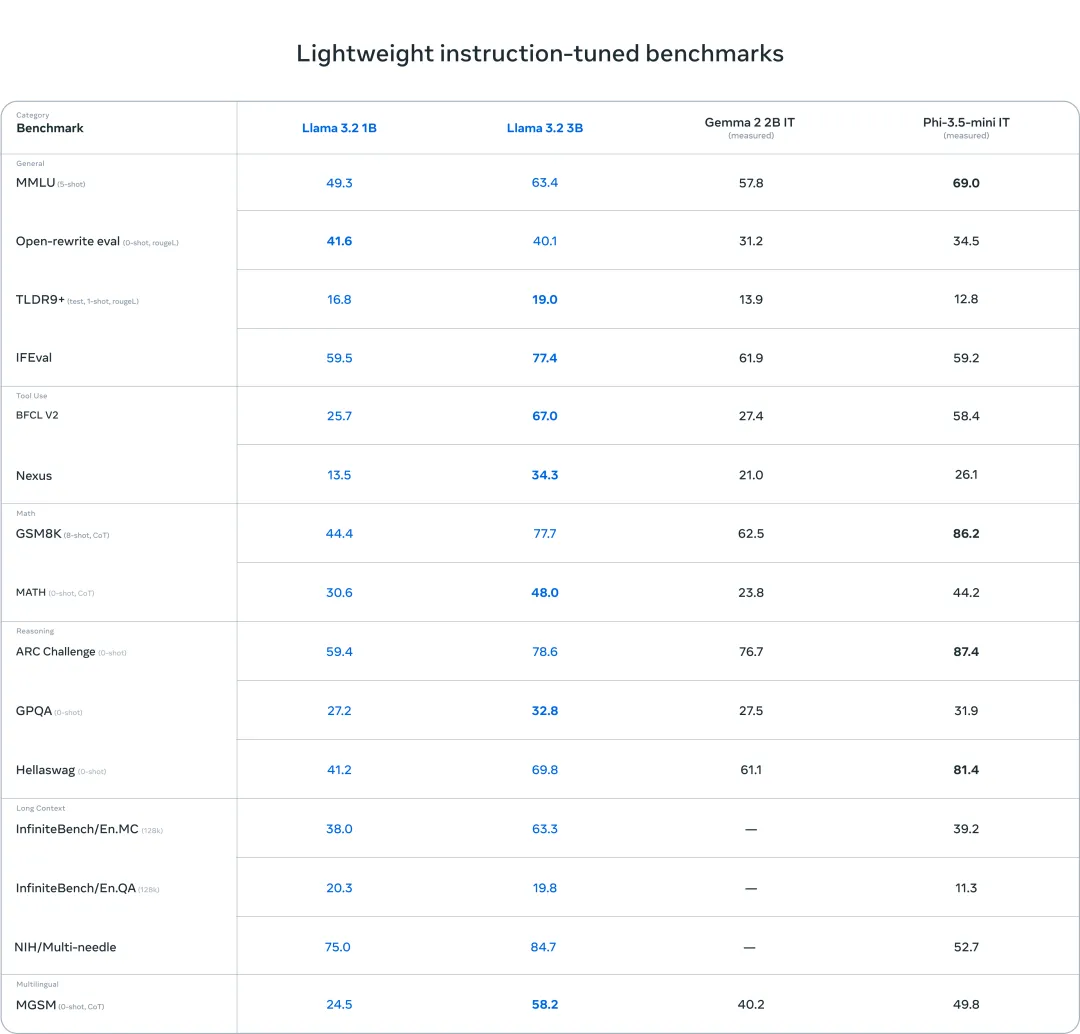
Llama 3.2 视觉模型在图像识别和一系列视觉理解任务上与领先的基础模型 Claude 3 Haiku 和 GPT4o-mini 相媲美。3B 模型在遵循指令、总结、快速重写和工具使用等任务上的表现优于 Gemma 2 2.6B 和 Phi 3.5-mini 模型,而 1B 模型与 Gemma 相媲美。
模型推理
Llama-3.2-3B-Instruct:
import torch
from transformers import pipeline
from modelscope import snapshot_download
model_dir = snapshot_download('LLM-Research/Llama-3.2-3B-Instruct')
pipe = pipeline(
"text-generation",
model=model_dir,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
Llama-3.2-11B-Vision-Instruct:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
from modelscope import snapshot_download
model_id = "LLM-Research/Llama-3.2-11B-Vision-Instruct"
model_dir = snapshot_download(model_id, ignore_file_pattern=['*.pth'])
model = MllamaForConditionalGeneration.from_pretrained(
model_dir,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_dir)
url = "https://www.modelscope.cn/models/LLM-Research/Llama-3.2-11B-Vision/resolve/master/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=30)
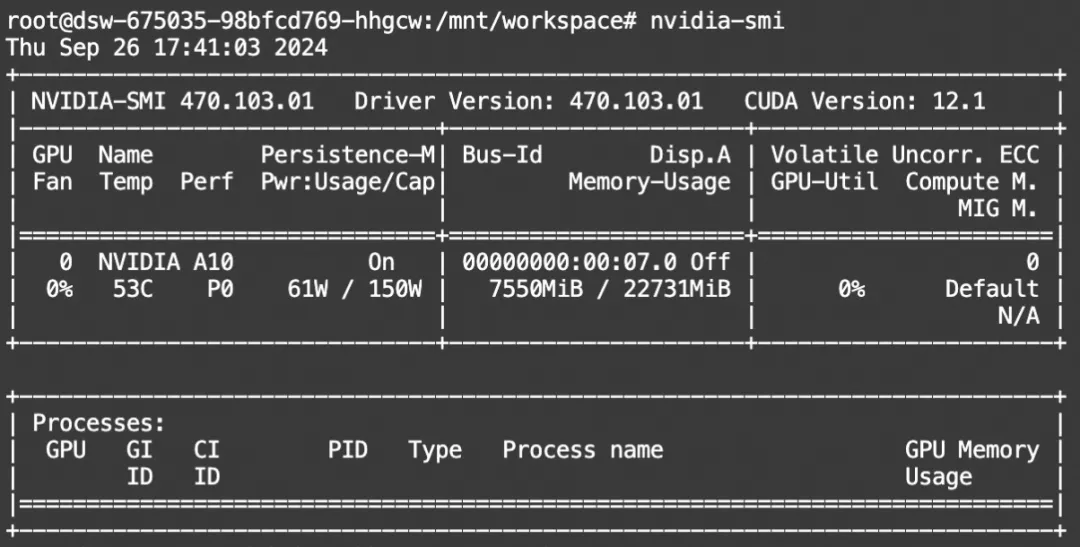
print(processor.decode(output[0]))显存占用:
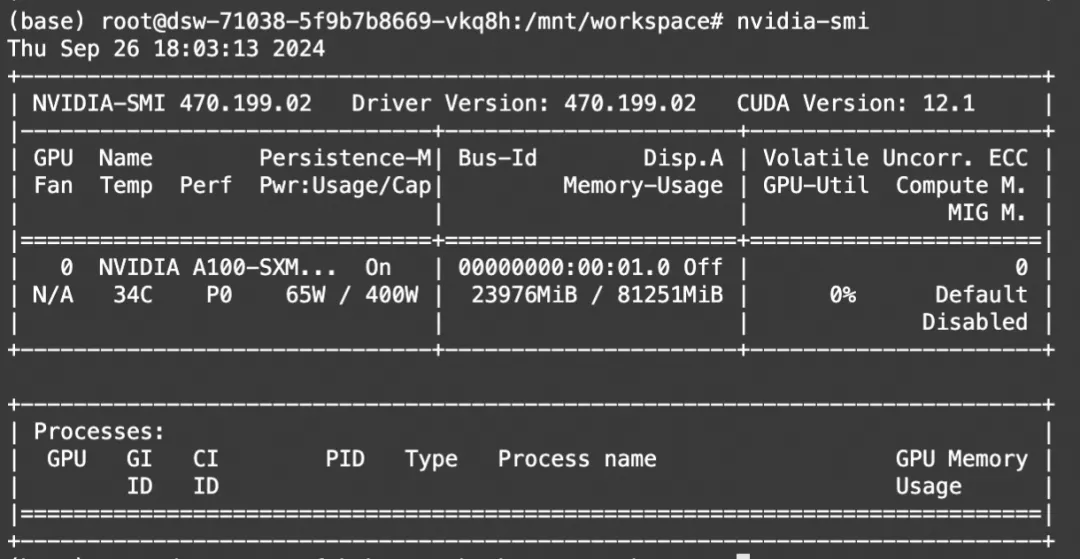
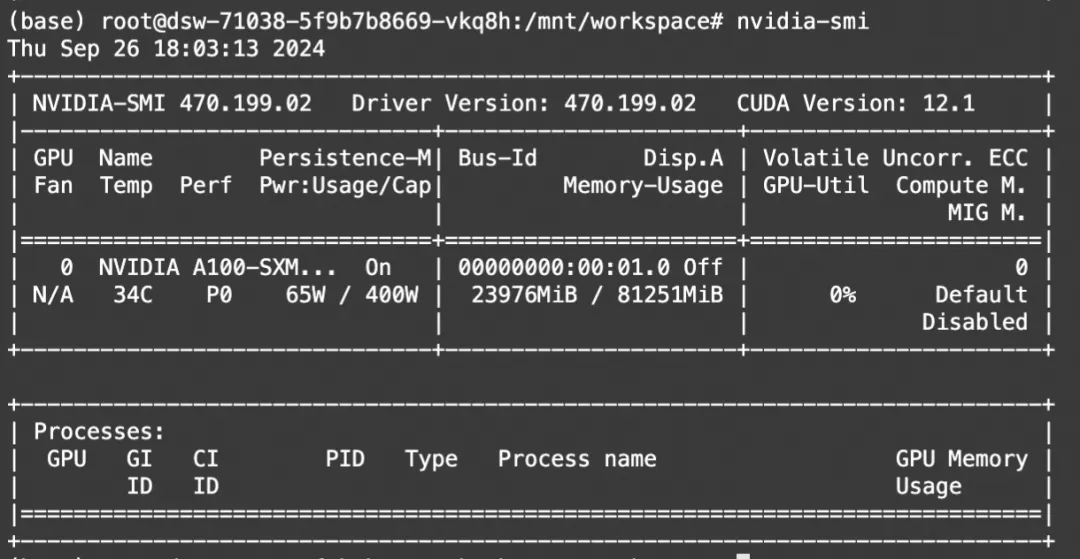
Ollama模型部署
单模型GGUF文件下载
使用ModelScope命令行工具下载单个模型,本文使用Llama-3.2-3B-Instruct的GGUF格式:
modelscope download --model QuantFactory/Llama-3.2-3B-Instruct-GGUF Llama-3.2-3B-Instruct.Q5_K_M.gguf --local_dir ./Linux环境使用
Liunx用户可使用魔搭镜像环境安装【推荐】:
https://www.modelscope.cn/models/modelscope/ollama-linux, 使用最新发布的Ollama 0.3.12版本
modelscope download --model=modelscope/ollama-linux --local_dir ./ollama-linux --revision v0.3.12
cd ollama-linux
sudo chmod 777 ./ollama-modelscope-install.sh
./ollama-modelscope-install.sh启动Ollama服务
ollama serve创建ModelFile
复制模型路径,创建名为“Modelfile”的meta文件,其中设置template,使之支持function call,内容如下,其中FROM后面接的是上面下载的GGUF文件的路径
FROM ./Llama-3.2-3B.Q5_K_M.gguf
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
TEMPLATE """<|start_header_id|>system<|end_header_id|>
Cutting Knowledge Date: December 2023
{{ if .System }}{{ .System }}
{{- end }}
{{- if .Tools }}When you receive a tool call response, use the output to format an answer to the orginal user question.
You are a helpful assistant with tool calling capabilities.
{{- end }}<|eot_id|>
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 }}
{{- if eq .Role "user" }}<|start_header_id|>user<|end_header_id|>
{{- if and $.Tools $last }}
Given the following functions, please respond with a JSON for a function call with its proper arguments that best answers the given prompt.
Respond in the format {"name": function name, "parameters": dictionary of argument name and its value}. Do not use variables.
{{ range $.Tools }}
{{- . }}
{{ end }}
{{ .Content }}<|eot_id|>
{{- else }}
{{ .Content }}<|eot_id|>
{{- end }}{{ if $last }}<|start_header_id|>assistant<|end_header_id|>
{{ end }}
{{- else if eq .Role "assistant" }}<|start_header_id|>assistant<|end_header_id|>
{{- if .ToolCalls }}
{{ range .ToolCalls }}
{"name": "{{ .Function.Name }}", "parameters": {{ .Function.Arguments }}}{{ end }}
{{- else }}
{{ .Content }}
{{- end }}{{ if not $last }}<|eot_id|>{{ end }}
{{- else if eq .Role "tool" }}<|start_header_id|>ipython<|end_header_id|>
{{ .Content }}<|eot_id|>{{ if $last }}<|start_header_id|>assistant<|end_header_id|>
{{ end }}
{{- end }}
{{- end }}"""创建自定义模型
使用ollama create命令创建自定义模型
ollama create myllama3.2-3b --file ./Modelfile运行模型:
ollama run myllama3.2-3b进行对话:
>>> hello, what can you can me about yourself?
I'll do my best to give you an overview of who I am and what I can do.
**About My Capabilities:**
1. **Language Understanding:** I can comprehend natural language inputs, including grammar, syntax, and context.
2. **Knowledge Base:** I have been trained on a vast amount of text data from various sources, which enables me to provide
accurate and informative responses.
3. **Text Generation:** I can generate human-like text based on the input I receive, whether it's a question, prompt, or
topic.
**About My Limits:**
1. **Knowledge Limitations:** While I have been trained on a massive dataset, there may be topics or areas of knowledge where
my understanding is limited or outdated.
2. **Creative Thinking:** I can generate text and responses, but I'm not as good at creative thinking or original ideas like
humans are.
3. **Emotional Intelligence:** I don't possess emotions or empathy in the way humans do, which can limit my ability to
understand complex emotional situations.
**About My Purpose:**
1. **Assisting Humans:** My primary purpose is to assist and provide value to users by answering questions, generating text,
and completing tasks.
2. **Learning and Improvement:** Through interactions with users like you, I learn and improve my abilities to better serve
future users.
3. **Entertainment:** I can also be used for entertainment purposes, such as generating stories, poems, or even chatbot-style
conversations!
**About My Personality:**
1. **Neutral Tone:** I strive to maintain a neutral tone and avoid taking a biased stance on any topic.
2. **Professional Language:** I aim to communicate in a professional and respectful manner, avoiding sarcasm or humor that
might be misinterpreted.
3. **Helpful and Patient:** My goal is to provide helpful responses and answer questions to the best of my ability, without
getting frustrated or impatient.
That's me in a nutshell! What would you like to know more about?模型微调
我们使用ms-swift对llama3.2和llama3.2-vision进行微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型微调推理框架。
ms-swift开源地址:
https://github.com/modelscope/ms-swift
这里展示可运行的demo,自定义数据集可以查看这里:
https://swift.readthedocs.io/zh-cn/latest/Instruction/%E8%87%AA%E5%AE%9A%E4%B9%89%E4%B8%8E%E6%8B%93%E5%B1%95.html
在开始微调之前,请确保您的环境已准备妥当。
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .[llm]Llama3.2
微调脚本:
# 单卡A10/3090可运行
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type llama3_2-1b-instruct \
--model_id_or_path LLM-Research/Llama-3.2-1B-Instruct \
--dataset jd-sentiment-zh \
--learning_rate 1e-4 \
--output_dir output \
--lora_target_modules ALL \
# Deepspeed-ZeRO2
NPROC_PER_NODE=4 CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model_type llama3_2-1b-instruct \
--model_id_or_path LLM-Research/Llama-3.2-1B-Instruct \
--dataset jd-sentiment-zh \
--learning_rate 1e-4 \
--output_dir output \
--lora_target_modules ALL \
--deepspeed default-zero2
微调后推理脚本如下,这里的ckpt_dir需要修改为训练生成的last_checkpoint文件夹。
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/llama3_2-1b-instruct/vx-xxx/checkpoint-xxx \
--load_dataset_config true --show_dataset_sample 10 \
--do_sample false
# merge-lora并使用推理
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/llama3_2-1b-instruct/vx-xxx/checkpoint-xxx \
--load_dataset_config true --show_dataset_sample 10 \
--merge_lora true --do-sample falseLlama3.2-Vision
我们使用Latex-OCR数据集:
https://modelscope.cn/datasets/AI-ModelScope/LaTeX_OCR 进行微调。
微调脚本:
# 默认:微调 LLM & projector, 冻结 vision encoder
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type llama3_2-11b-vision-instruct \
--model_id_or_path LLM-Research/Llama-3.2-11B-Vision-Instruct \
--sft_type lora \
--dataset latex-ocr-print#5000
# Deepspeed ZeRO2
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 swift sft \
--model_type llama3_2-11b-vision-instruct \
--model_id_or_path LLM-Research/Llama-3.2-11B-Vision-Instruct \
--sft_type lora \
--dataset latex-ocr-print#5000 \
--deepspeed default-zero2训练显存占用:
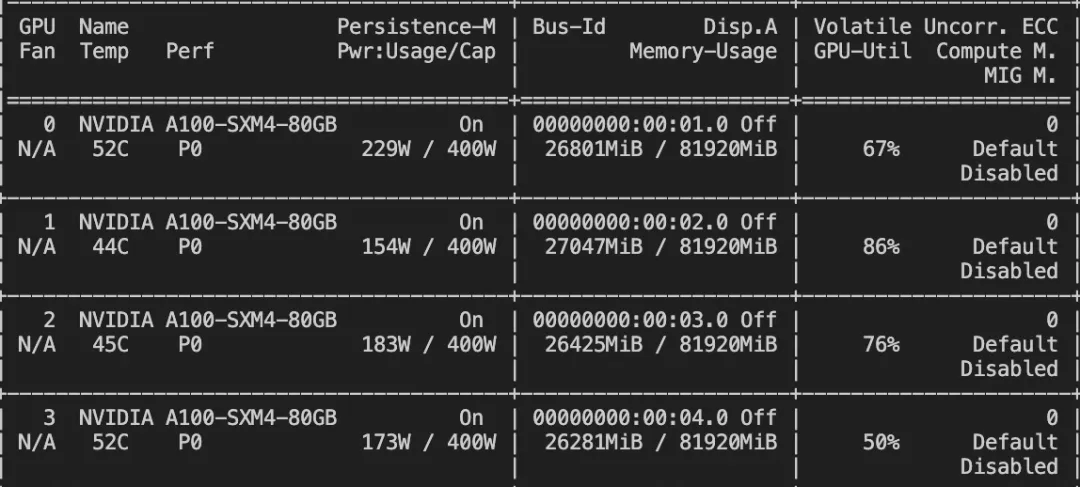
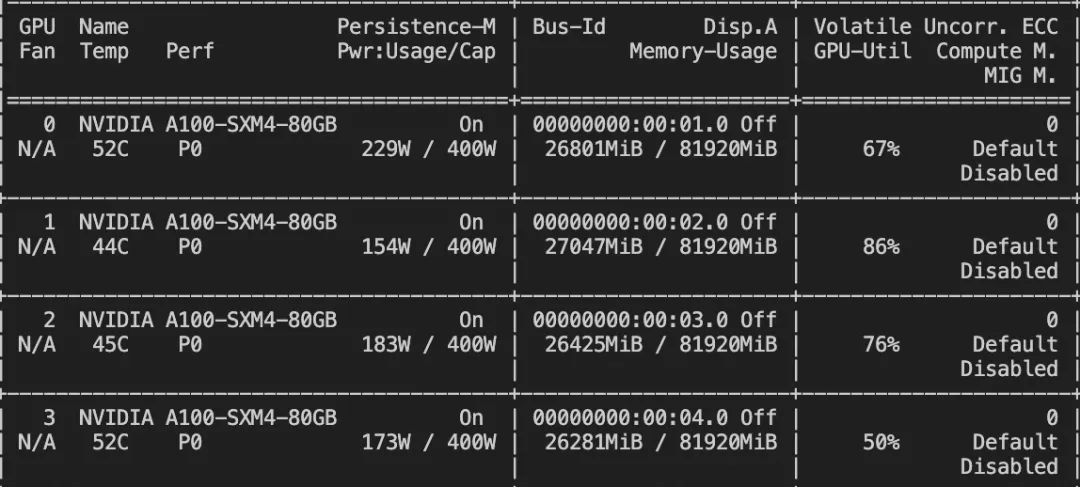
如果要使用自定义数据集,只需按以下方式进行指定:
# val_dataset可选,如果不指定,则会从dataset中切出一部分数据集作为验证集
--dataset train.jsonl \
--val_dataset val.jsonl \{"query": "<image>55555", "response": "66666", "images": ["image_path"]}
{"query": "<image><image>eeeee", "response": "fffff", "history": [], "images": ["image_path1", "image_path2"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["query1", "response1"], ["query2", "response2"]]}训练loss图:
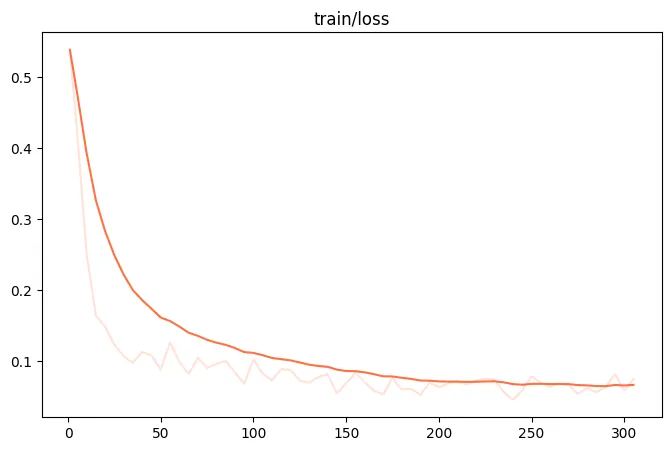
微调后推理脚本如下,这里的ckpt_dir需要修改为训练生成的last_checkpoint文件夹。
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/llama3_2-11b-vision-instruct/vx-xxx/checkpoint-xxx \
--load_dataset_config true
# or merge-lora & infer
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/llama3_2-11b-vision-instruct/vx-xxx/checkpoint-xxx \
--load_dataset_config true --merge_lora true微调后模型对验证集进行推理的结果:
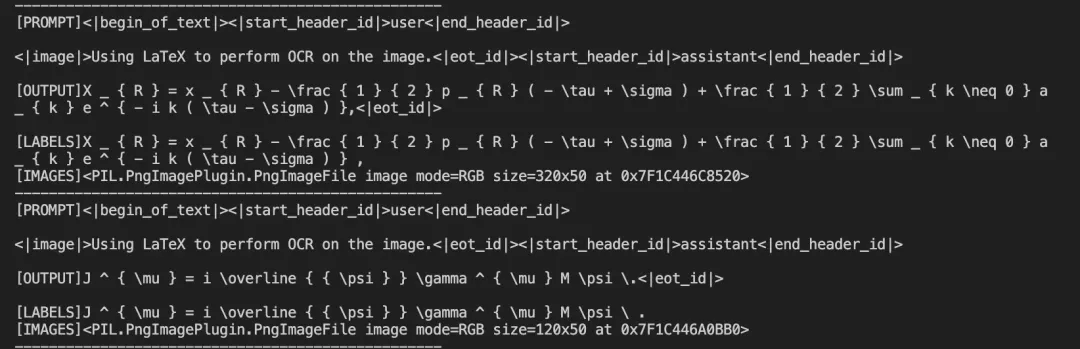
点击链接👇,跳转模型合集链接~
https://modelscope.cn/models?name=Llama%203.2&page=1?from=csdnzishequ_text?from=csdnzishequ_text








 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)