

旗舰端侧模型面壁「小钢炮」系列进化为全新 MiniCPM 3.0 基座模型,再次以小博大,以 4B 参数,带来超越 GPT-3.5 的性能。并且,量化后仅 2GB 内存,端侧友好。
小编敲黑板,本次发布重点:
-
无限长文本,榜单性能强,超长文本也不崩;
-
性能比肩 GPT-4o 的端侧强大 Function Calling;
-
超强 RAG 三件套,中文检索超强、生成超 Llama3-8B。
MiniCPM 3.0 开源地址:
代码链接:https://github.com/OpenBMB/MiniCPM
模型链接:
-
MiniCPM3-4B:
https://modelscope.cn/models/OpenBMB/MiniCPM3-4B
-
MiniCPM3-4B-GPTQ-Int4:https://modelscope.cn/models/OpenBMB/MiniCPM3-4B-GPTQ-Int4
-
MiniCPM3-RAG-LoRA:https://modelscope.cn/models/OpenBMB/MiniCPM3-RAG-LoRA
-
MiniCPM-Reranker:https://modelscope.cn/models/OpenBMB/MiniCPM-Reranker
-
MiniCPM-Embedding:https://modelscope.cn/models/OpenBMB/MiniCPM-Embedding
MiniCPM 3.0 模型性能:
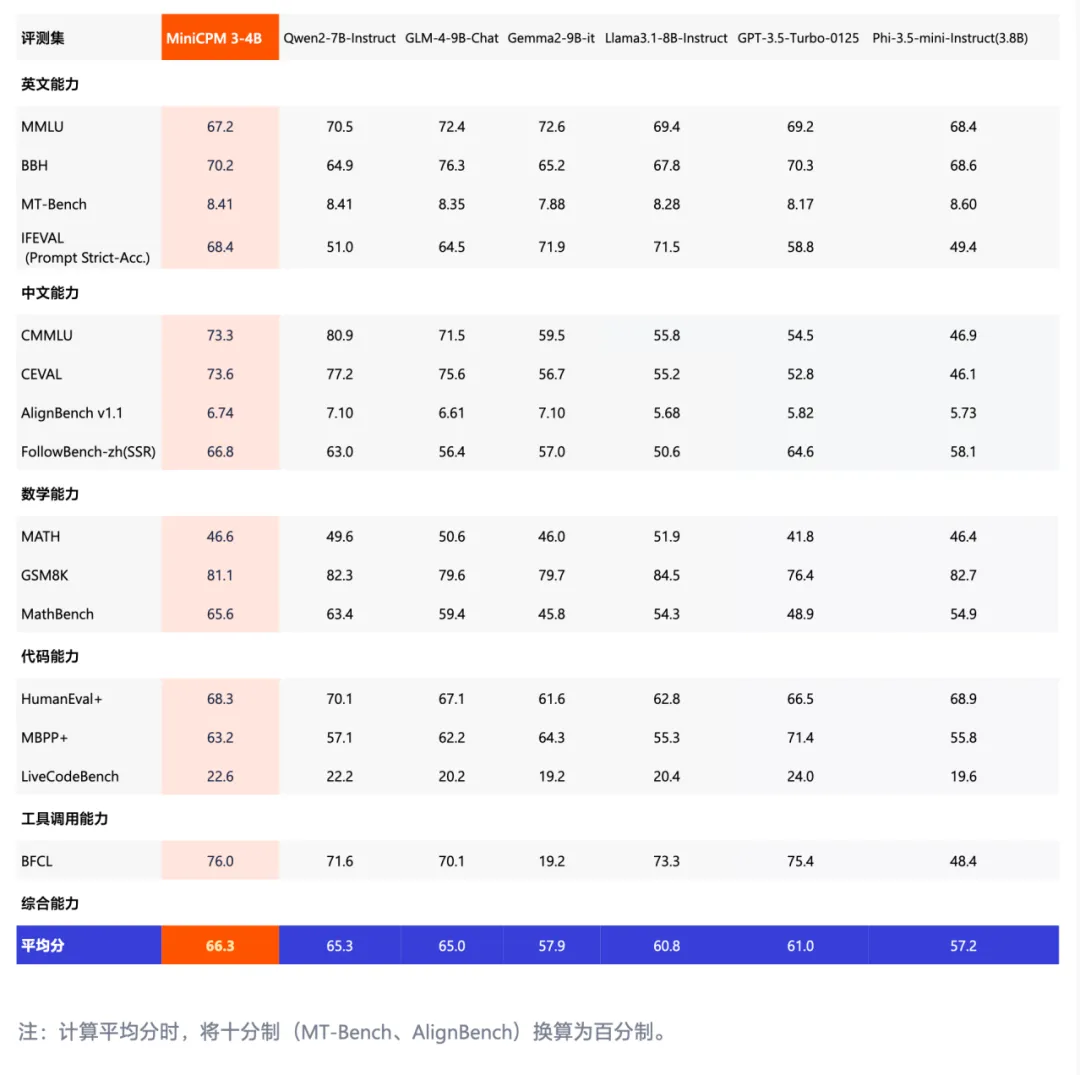
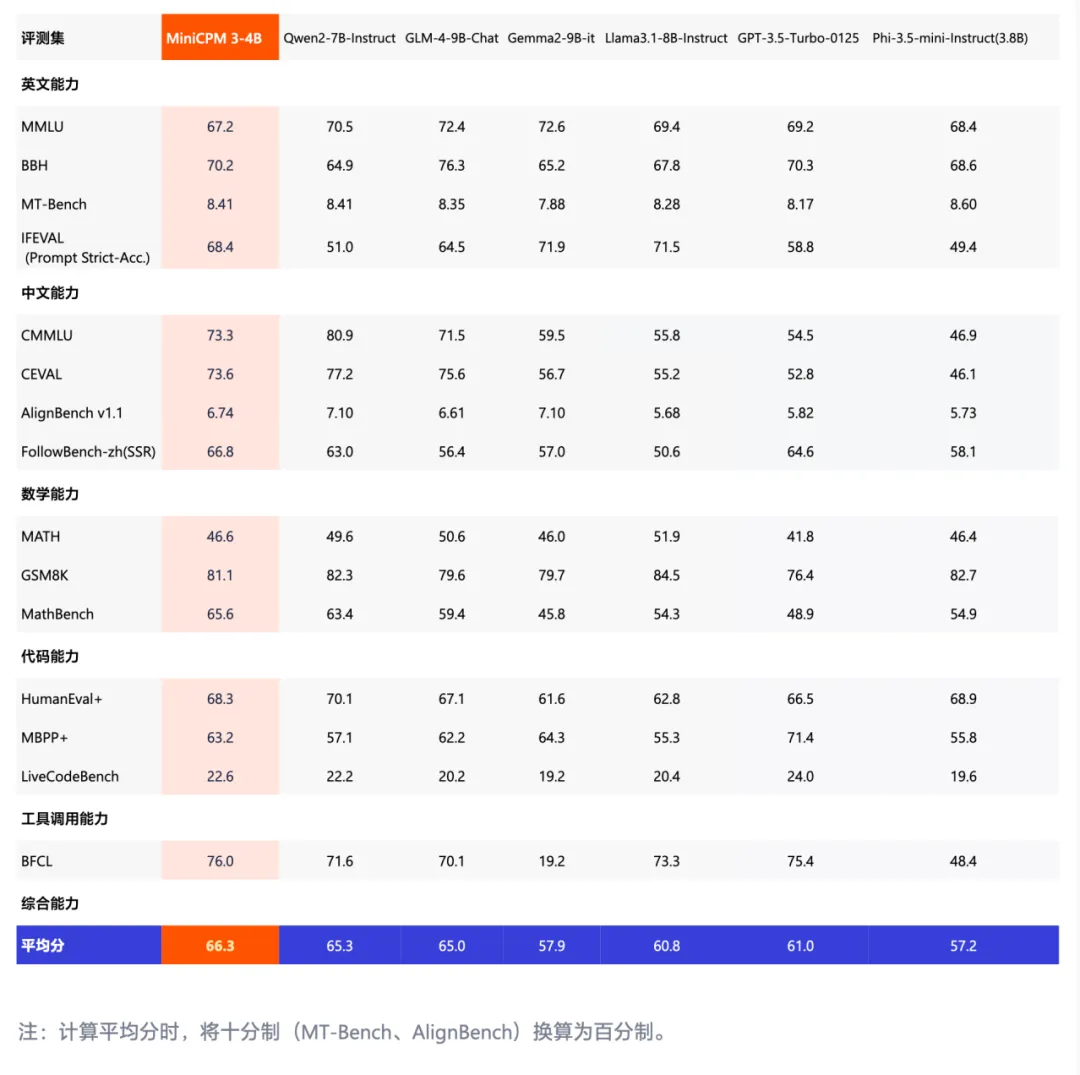
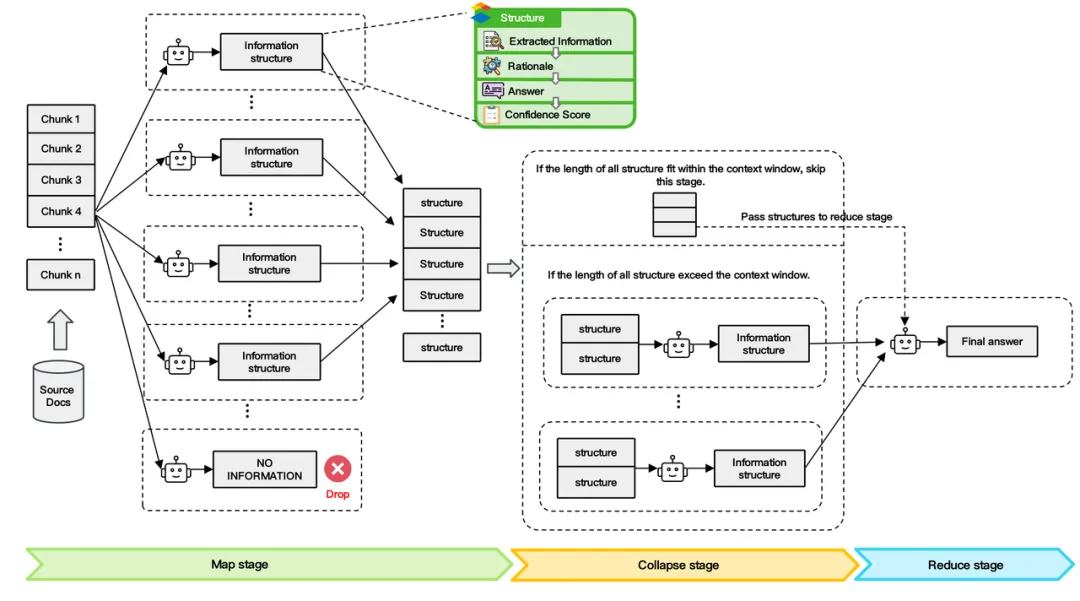
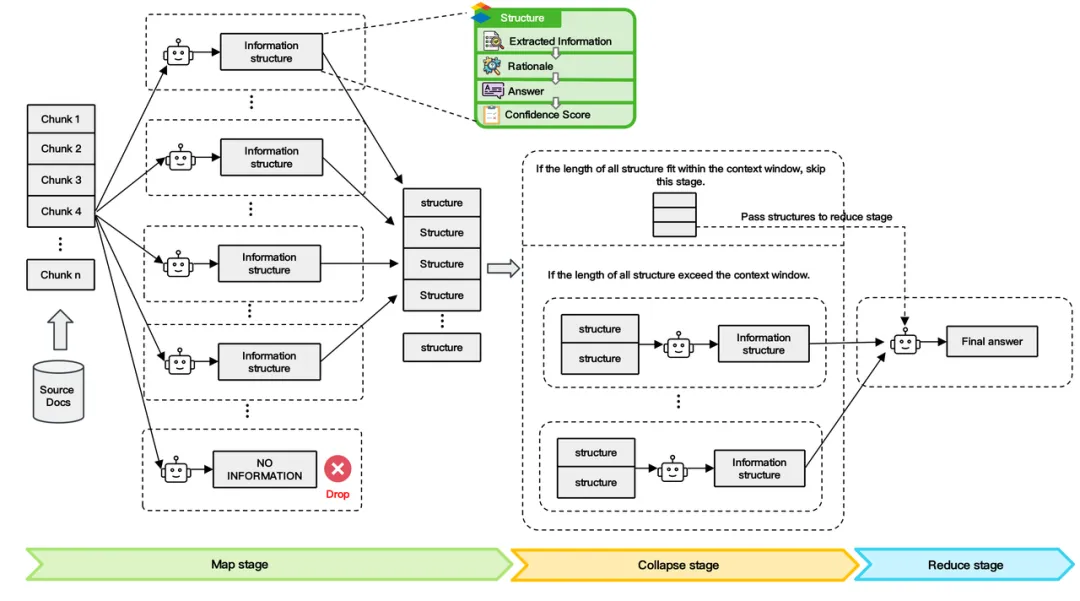
模型亮点
面壁「无限」长文本
面壁提出 LLMxMapReduce长本文分帧处理技术 ,一举实现「无限」长文本!32, 128, 256, 512K…MiniCPM 3.0 打破大模型记忆限制,可以将上下文长度无限稳定拓展,想多长就多长!
Function calling ,助力终端Agent应用
MiniCPM 3.0 拥有端侧超强 Function calling 性能 ,在权威评测榜单 Berkeley Function-Calling Leaderboard 上,其性能接近 GPT-4o。
RAG 三件套,生成超 Llama3-8B
MiniCPM 3.0一口气带来超强 RAG 外挂三件套:MiniCPM-Embedding(检索模型)、MiniCPM-Reranker(重排序模型)和面向 RAG 场景的 LoRA 插件(生成模型),款款优秀:
-
MiniCPM-Embedding(检索模型)中英跨语言检索取得 SOTA 性能,在评估模型文本嵌入能力的权威评测集 MTEB 的检索榜单上中文第一、英文第十三 ;
-
MiniCPM-Reranker(重排序模型)在中文、英文、中英跨语言测试上取得 SOTA 性能 ;
-
经过针对 RAG 场景的 LoRA 训练后,MiniCPM 3.0-RAG-LoRA 在开放域问答(NQ、TQA、MARCO)、多跳问答(HotpotQA)、对话(WoW)、事实核查(FEVER)和信息填充(T-REx)等多项任务上的性能表现,超越 Llama3-8B 和 Baichuan2-13B 等业内优秀模型。
魔搭社区最佳实践
模型下载
-
模型repo下载:
modelscope download --model=OpenBMB/MiniCPM3-4B --local_dir ./MiniCPM3-4B模型推理
-
MiniCPM3-4B推理:
from modelscope import AutoModelForCausalLM, AutoTokenizer
import torch
path = "OpenBMB/MiniCPM3-4B"
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True)
messages = [
{"role": "user", "content": "推荐5个北京的景点。"},
]
model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(device)
model_outputs = model.generate(
model_inputs,
max_new_tokens=1024,
top_p=0.7,
temperature=0.7,
repetition_penalty=1.02
)
output_token_ids = [
model_outputs[i][len(model_inputs[i]):] for i in range(len(model_inputs))
]
responses = tokenizer.batch_decode(output_token_ids, skip_special_tokens=True)[0]
print(responses)-
MiniCPM3-RAG-LoRA推理
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from modelscope import snapshot_download
base_model_dir = snapshot_download("OpenBMB/MiniCPM3-4B")
lora_model_dir = snapshot_download("OpenBMB/MiniCPM3-RAG-LoRA")
model = AutoModelForCausalLM.from_pretrained(base_model_dir, device_map="auto",torch_dtype=torch.bfloat16).eval()
tokenizer = AutoTokenizer.from_pretrained(lora_model_dir)
model = PeftModel.from_pretrained(model, lora_model_dir)
passages_list = ["In the novel 'The Silent Watcher,' the lead character is named Alex Carter. Alex is a private detective who uncovers a series of mysterious events in a small town.",
"Set in a quiet town, 'The Silent Watcher' follows Alex Carter, a former police officer turned private investigator, as he unravels the town's dark secrets.",
"'The Silent Watcher' revolves around Alex Carter's journey as he confronts his past while solving complex cases in his hometown."]
instruction = "Q: What is the name of the lead character in the novel 'The Silent Watcher'?\nA:"
passages = '\n'.join(passages_list)
input_text = 'Background:\n' + passages + '\n\n' + instruction
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": input_text},
]
prompt = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
outputs = model.chat(tokenizer, prompt, temperature=0.8, top_p=0.8)
print(outputs[0]) # The lead character in the novel 'The Silent Watcher' is named Alex Carter.-
MiniCPM-Embedding推理
from modelscope import AutoModel, AutoTokenizer
import torch
import torch.nn.functional as F
model_name = "OpenBMB/MiniCPM-Embedding"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name, trust_remote_code=True, attn_implementation="flash_attention_2", torch_dtype=torch.float16).to("cuda")
model.eval()
def weighted_mean_pooling(hidden, attention_mask):
attention_mask_ = attention_mask * attention_mask.cumsum(dim=1)
s = torch.sum(hidden * attention_mask_.unsqueeze(-1).float(), dim=1)
d = attention_mask_.sum(dim=1, keepdim=True).float()
reps = s / d
return reps
@torch.no_grad()
def encode(input_texts):
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt', return_attention_mask=True).to("cuda")
outputs = model(**batch_dict)
attention_mask = batch_dict["attention_mask"]
hidden = outputs.last_hidden_state
reps = weighted_mean_pooling(hidden, attention_mask)
embeddings = F.normalize(reps, p=2, dim=1).detach().cpu().numpy()
return embeddings
queries = ["中国的首都是哪里?"]
passages = ["beijing", "shanghai"]
INSTRUCTION = "Query: "
queries = [INSTRUCTION + query for query in queries]
embeddings_query = encode(queries)
embeddings_doc = encode(passages)
scores = (embeddings_query @ embeddings_doc.T)
print(scores.tolist()) # [[0.3535913825035095, 0.18596848845481873]]-
MiniCPM-Reranker推理
from transformers import AutoModel, AutoTokenizer, AutoModelForSequenceClassification
import torch
import numpy as np
#模型下载
from modelscope import snapshot_download
model_name = snapshot_download('OpenBMB/MiniCPM-Reranker')
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.padding_side = "right"
model = AutoModelForSequenceClassification.from_pretrained(model_name, trust_remote_code=True,attn_implementation="flash_attention_2", torch_dtype=torch.float16).to("cuda")
model.eval()
max_len_q, max_len_d = 512, 512
def tokenize_our(query,doc):
input_id_query = tokenizer.encode(query, add_special_tokens=False, max_length=max_len_q, truncation=True)
input_id_doc = tokenizer.encode(doc, add_special_tokens=False, max_length=max_len_d, truncation=True)
pad_input = {"input_ids": [tokenizer.bos_token_id] + input_id_query + [tokenizer.eos_token_id] + input_id_doc}
return tokenizer.pad(
pad_input,
padding="max_length",
max_length=max_len_q + max_len_d + 2,
return_tensors="pt",
)
@torch.no_grad()
def rerank(input_query, input_docs):
tokenized_inputs = [tokenize_our(input_query, input_doc).to("cuda") for input_doc in input_docs]
input_ids = {
"input_ids": [tokenized_input["input_ids"] for tokenized_input in tokenized_inputs],
"attention_mask": [tokenized_input["attention_mask"] for tokenized_input in tokenized_inputs]
}
for k in input_ids:
input_ids[k] = torch.stack(input_ids[k]).to("cuda")
outputs = model(**input_ids)
score = outputs.logits
return score.float().detach().cpu().numpy()
queries = ["中国的首都是哪里?"]
passages = [["beijing", "shanghai"]]
INSTRUCTION = "Query: "
queries = [INSTRUCTION + query for query in queries]
scores = []
for i in range(len(queries)):
print(queries[i])
scores.append(rerank(queries[i],passages[i]))
print(np.array(scores)) # [[[-4.7421875][-8.8515625]]]模型微调
我们介绍使用ms-swift对minicpm3-4b进行分类任务微调,并对微调后模型进行推理。swift是魔搭社区官方提供的LLM工具箱,支持300+大语言模型和80+多模态大模型的微调到部署。swift开源地址:https://github.com/modelscope/ms-swift
通常,大模型微调通常使用自定义数据集进行微调。在这里,我们将展示可直接运行的demo。我们使用 jd-sentiment-zh 情感分类数据集进行古文翻译腔微调,您可以在 modelscope 上找到该数据集:
https://modelscope.cn/datasets/DAMO_NLP/jd
在开始微调之前,请确保您的环境已正确安装
# 安装ms-swift
git clone https://github.com/modelscope/ms-swift.git
cd swift
pip install -e .[llm]微调脚本:
# 单卡A10/3090可运行
# 13GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type minicpm3-4b \
--model_id_or_path OpenBMB/MiniCPM3-4B \
--dataset jd-sentiment-zh \
--learning_rate 1e-4 \
--output_dir output \
--lora_target_modules ALL \
# 4 * 13GB GPU memory
# Deepspeed-ZeRO2
NPROC_PER_NODE=4 CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model_type minicpm3-4b \
--model_id_or_path OpenBMB/MiniCPM3-4B \
--dataset jd-sentiment-zh \
--learning_rate 1e-4 \
--output_dir output \
--lora_target_modules ALL \
--deepspeed default-zero2微调显存消耗:
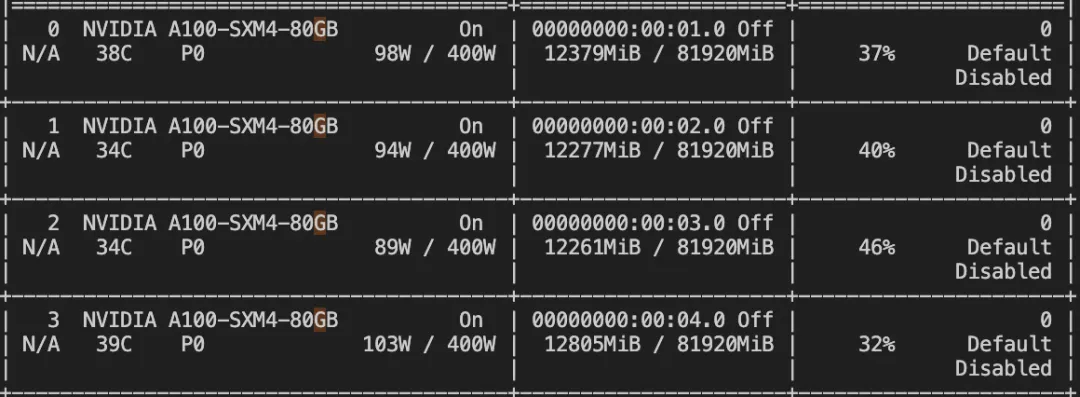
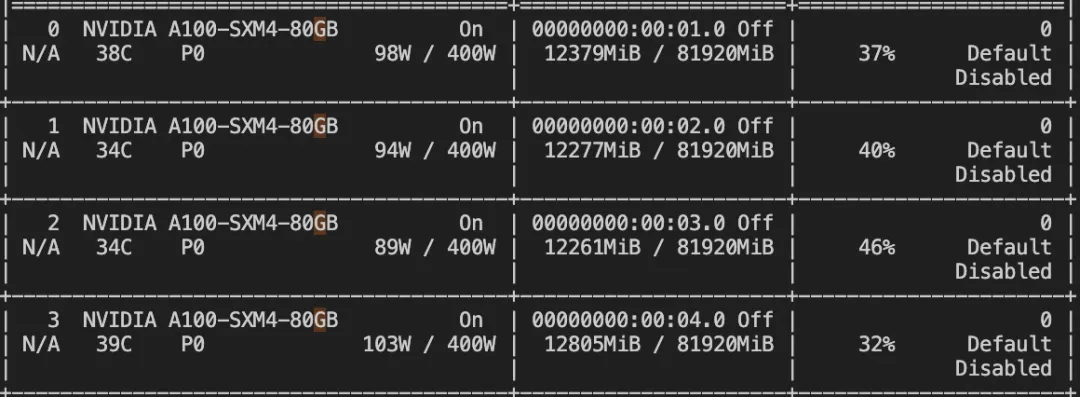
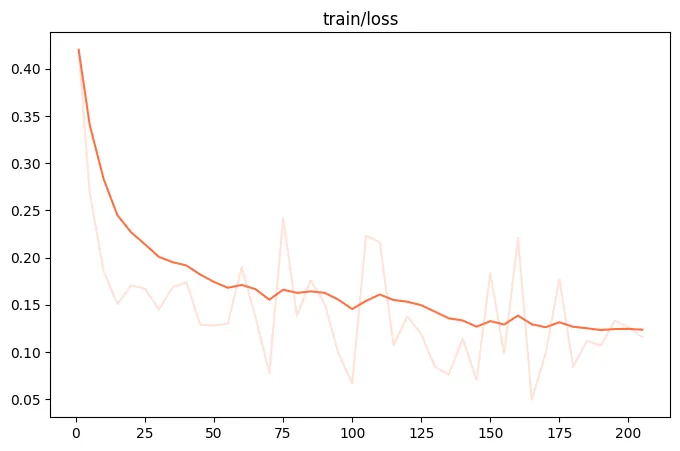
微调过程的loss可视化:(这里只微调了200个steps)

微调后推理脚本如下,这里的ckpt_dir需要修改为训练生成的last checkpoint文件夹。
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/minicpm3-4b/vx-xxx/checkpoint-xxx \
--load_dataset_config true --show_dataset_sample 10 \
--do_sample false
# merge-lora并推理
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/minicpm3-4b/vx-xxx/checkpoint-xxx \
--load_dataset_config true --show_dataset_sample 10 \
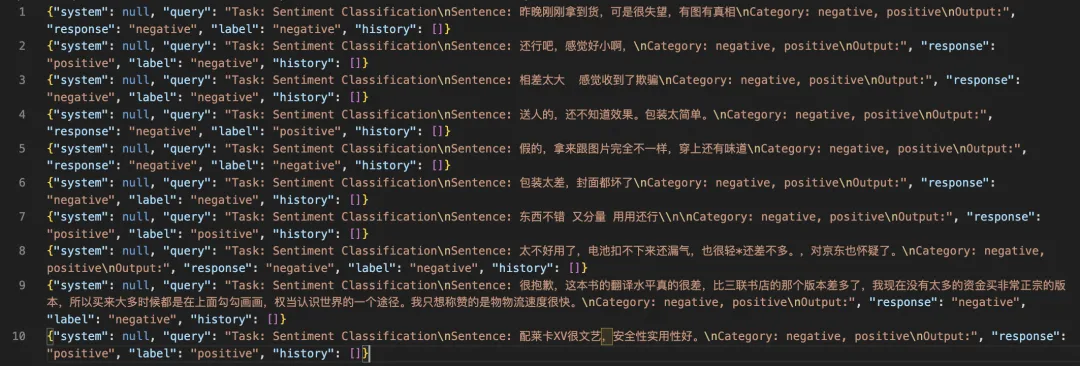
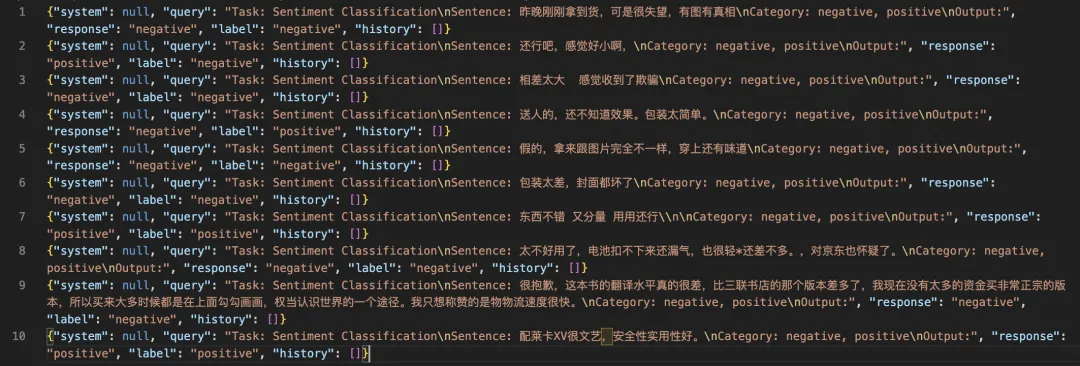
--merge_lora true --do-sample false微调后模型对验证集进行推理:








 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)