
# pip install accelerate
from modelscope import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("AI-ModelScope/gemma-2-2b")
model = AutoModelForCausalLM.from_pretrained(
"AI-ModelScope/gemma-2-2b",
device_map="auto",
torch_dtype=torch.bfloat16
)
input_text = "who are you."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))魔搭社区每周速递(7.27-8.3)
155个模型、123个数据集、68个创新应用、5篇应用文章
·

🙋魔搭ModelScope本期社区进展:
📟155个模型:FLUX.1系列、Gemma-2-2b、Kolors-Inpainting、stella_en_400M_v5等;
📁123个数据集:FineTome-100k、Open-Critic-GPT、Alpaca-CoT等;
🎨68个创新应用:DiffSynth 画板、FLUX文生图模型体验空间 等;
📄5篇文章:
-
消费级显卡,17G显存,玩转图像生成模型FLUX.1!
-
Modelscope Agent实操(六):添加涂鸦作画能力到Modelscope-Agent中
-
影视与游戏行业AI视频制作的第3步:为角色生成说话视频
-
解锁开源模型高性能服务:SGLang Runtime 应用场景与实践
-
GraphRAG+Ollama,构建本地精准全局问答系统!
精选模型推荐
FLUX.1系列
由Stable Diffusion核心成员创立的Black Forest Labs推出的FLUX.1,是12B规格的全新文生图系列模型,能生成高分辨率的高质量图片。从模型架构上看,FLUX.1和SD3有很多相似之处,都是基于FlowingMatching调度的模型,都通过引入T5来增强prompt的依从性。而比较显著的区别在于:FLUX.1模型引入了一种叫DoubleStreamBlock的结构,具体来说在前几层layer中,采用了txt和img embedding独立过各自的transformer块,然后再拼到一起过统一的transformer块。
FLUX.1包括3个变体模型:FLUX.1-pro、FLUX.1-dev、FLUX.1-schnell,其中dev、schnell均开源。
模型链接:
FLUX.1-dev
https://modelscope.cn/models/AI-ModelScope/FLUX.1-dev
FLUX.1-schnell
https://modelscope.cn/models/AI-ModelScope/FLUX.1-schnell
fp8模型版本(社区开发者提供)
https://modelscope.cn/models/AI-ModelScope/flux-fp8
应用示例:
使用ComfyUI,在魔搭社区提供的免费GPU Notebook上,体验FLUX模型,详见教程文章
Gemma-2-2b
Gemma 2 2B是 Google DeepMind推出的Gemma 2系列最新成员。这款轻量级模型通过蒸馏学习大型模型,实现了以小博大的卓越效果。Gemma 2 2B在Chatbot Arena的表现超越了所有GPT-3.5系列的模型,彰显了其在对话式人工智能领域的非凡能力。
模型链接:
gemma-2-2b
https://www.modelscope.cn/models/AI-ModelScope/gemma-2-2b
gemma-2-2b-it
https://www.modelscope.cn/models/LLM-Research/gemma-2-2b-it
示例代码:
数据集推荐
FineTome-100k
FineTome 数据集是 arcee-ai/The-Tome 的子集(没有 arcee-ai/qwen2-72b-magpie-en),使用 HuggingFaceFW/fineweb-edu-classifier 重新过滤。
数据集链接:
https://www.modelscope.cn/datasets/AI-ModelScope/FineTome-100k
Open-Critic-GPT
Open-Critic-GPT 数据集是一个合成数据集,用于训练模型识别和修复代码中的错误。该数据集是使用独特的合成数据管道生成的,该管道涉及:
-
提示使用现有代码示例创建本地模型。
-
在代码中引入 bug。在拥有模型的同时,从第一人称视角,找到错误并解释它们。
-
通过在损坏的代码和工作代码的位置移动来操作数据,并从代码中删除 # bug// 和 # error// 注释。
数据集链接:
https://www.modelscope.cn/datasets/AI-ModelScope/Open-Critic-GPT
Alpaca-CoT
该存储库将持续收集各种指令调优数据集。我们将不同的数据集标准化为相同的格式,可以直接通过Alpaca模型的代码进行加载。
数据集链接:
https://www.modelscope.cn/datasets/swift/Alpaca-CoT
精选应用推荐
DiffSynth 画板
DiffSynth 画板提供了 Prompt 分区控制技术,可以通过创建图层精细地控制画面的每一部分,实现了“Prompt 即画笔”。
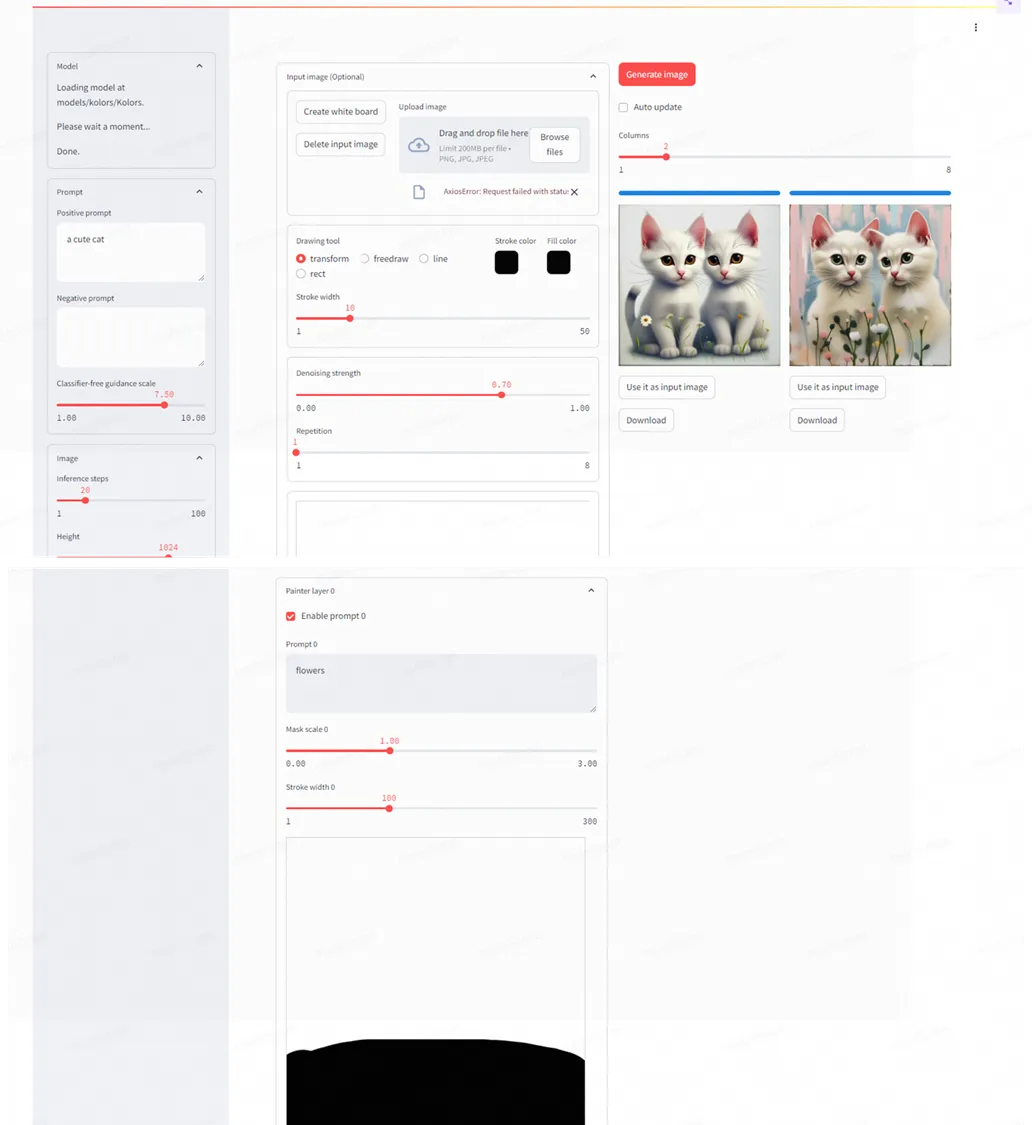
体验直达:
https://www.modelscope.cn/studios/AI-ModelScope/DiffSynth-Kolors-Painter
FLUX文生图模型体验空间
目前最强的开源文生图模型之一,在文字生成、复杂指令遵循和人手生成上具备优势。
体验直达:
https://www.modelscope.cn/studios/muse/flux_dev
社区精选文章

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献659条内容
已为社区贡献659条内容

所有评论(0)