
pip install transformers==4.41.*
#pip uninstall pytorchvideo
pip install git+https://github.com/facebookresearch/pytorchvideo.git
pip install decord理解时间戳的视频理解大模型CogVLM2开源!视频生成、视频摘要等任务有力工具!
随着大型语言模型和多模态对齐技术的发展,视频理解模型在通用开放领域也取得了长足的进步。
·
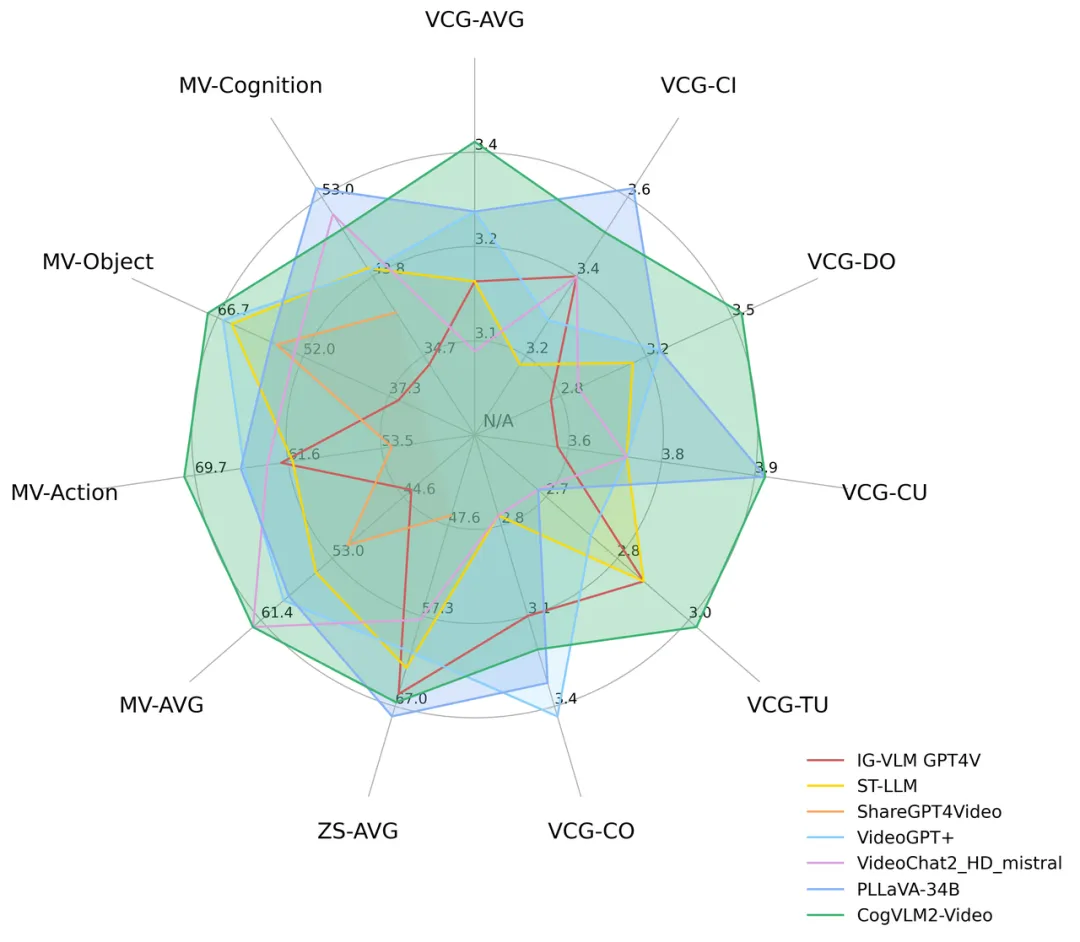
随着大型语言模型和多模态对齐技术的发展,视频理解模型在通用开放领域也取得了长足的进步。然而,目前大多数视频理解模型采用帧平均和视频 token 压缩的方法,导致时间信息丢失,无法准确回答时间相关的问题。另一方面,一些专注于时间问答数据集的模型过度局限于特定的格式和适用领域,导致模型丧失了更通用的问答能力。CogVLM团队引入多帧视频图像和时间戳作为编码器输入,训练了一个新的视频理解模型 — CogVLM2-Video。CogVLM2-Video 不仅在公开的视频理解基准上取得了最佳表现,而且在视频字幕和时间基础方面也表现出色,为后续的视频生成、视频摘要等任务提供了有力的工具。
模型效果:
模型架构
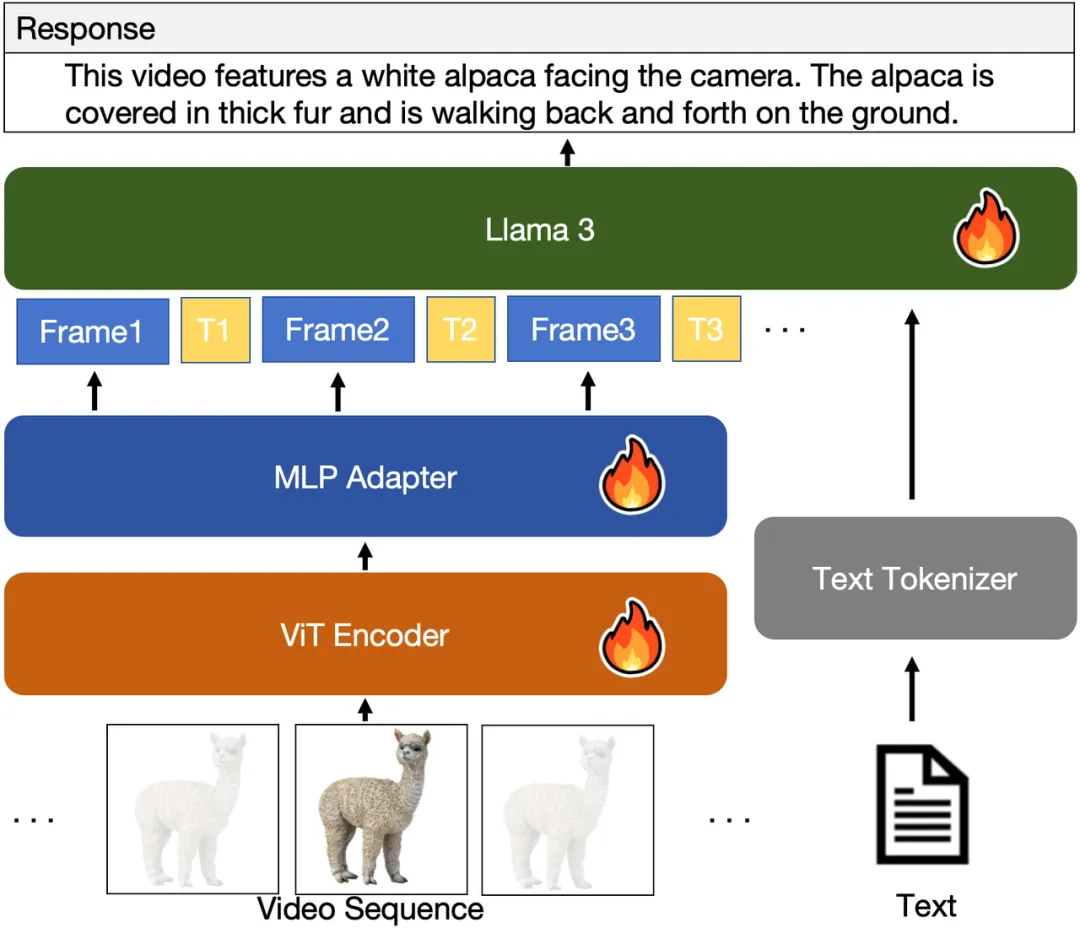
目前视频理解的主流思路是利用图像编码器从视频中提取帧,对其进行编码,然后设计编码压缩模块(如时间池化或Q-Former模块)对视频编码信息进行压缩,再输入大型语言模型(LLM)与文本输入进行联合理解。虽然这种方法可以有效压缩视频信息,但是却导致模型丧失时间感知能力,无法将视频帧与精确的时间戳准确关联,从而导致模型缺乏时间定位、时间戳检测和关键时刻总结能力。此外,利用现有的时间基础标注数据训练的视频理解模型受限于数据范围和固定的问答格式,缺乏开放域问答和处理能力。
针对这些问题,研究团队提出了基于CogVLM2图像理解模型的扩展视频模型CogVLM2-Video。这个模型不仅在开放域问答中取得了很好的表现,而且还能感知视频中的时间戳信息,从而实现时间定位和相关的问答。具体来说,CogVLM2-Video从输入的视频片段中提取帧,并用时间戳信息进行注释,从而使后续的语言模型能够准确地知道原始视频中每一帧对应的确切时间。下图显示了CogVLM2-Video的整体架构:
代码链接:
https://github.com/THUDM/CogVLM2
模型链接:
https://modelscope.cn/models/ZhipuAI/cogvlm2-video-llama3-chat
模型体验
创空间链接:https://modelscope.cn/studios/ZhipuAI/Cogvlm2-Video-Llama3-Chat-Demo

模型推理
环境安装
运行代码
git clone https://github.com/THUDM/CogVLM2.git
cd CogVLM2/video_demo
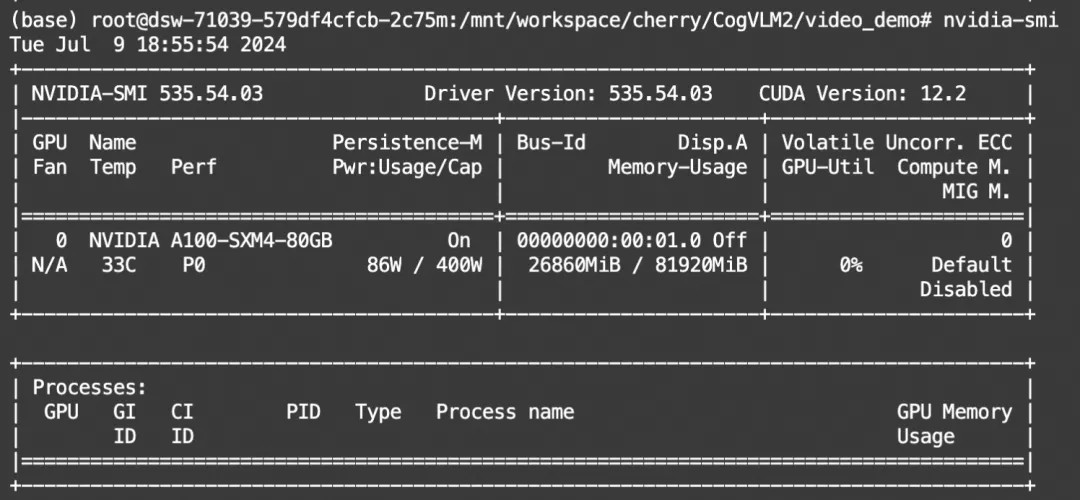
python cli_video_demo.py显存占用:
模型微调
我们使用ms-swift对CogVLM2-Video-Llama-Chat进行微调。swift是魔搭社区官方提供的LLM工具箱,支持300+大语言模型和50+多模态大模型的微调、推理、量化、评估和部署。
ms-swift对CogVLM2-Video-Llama-Chat推理与微调的最佳实践可以查看:https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/cogvlm2-video%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5.md
通常,多模态大模型微调会使用自定义数据集进行微调。在这里,我们将展示可直接运行的demo。我们使用 video-chatgpt 数据集进行微调,该数据集的任务是对图片内容进行描述。您可以在 modelscope 上找到该数据集:https://modelscope.cn/datasets/huangjintao/VideoChatGPT
在开始微调之前,请确保您的环境已正确安装:
# 安装ms-swift
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e .[llm]
pip install "transformers==4.41.*"
# https://github.com/facebookresearch/pytorchvideo/issues/258
# https://github.com/dmlc/decord/issues/177
pip install decord pytorchvideoLoRA微调脚本如下所示。该脚本默认只对LLM的qkv进行lora微调,如果你想对所有linear层都进行微调,可以指定--lora_target_modules ALL。
# Experimental environment: A100
# 40GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type cogvlm2-video-13b-chat \
--model_id_or_path ZhipuAI/cogvlm2-video-llama3-chat \
--dataset video-chatgpt \
--num_train_epochs 3
# ZeRO2
# Experimental environment: 4 * A100
# 4 * 40GB GPU memory
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 swift sft \
--model_type cogvlm2-video-13b-chat \
--model_id_or_path ZhipuAI/cogvlm2-video-llama3-chat \
--dataset video-chatgpt \
--num_train_epochs 3 \
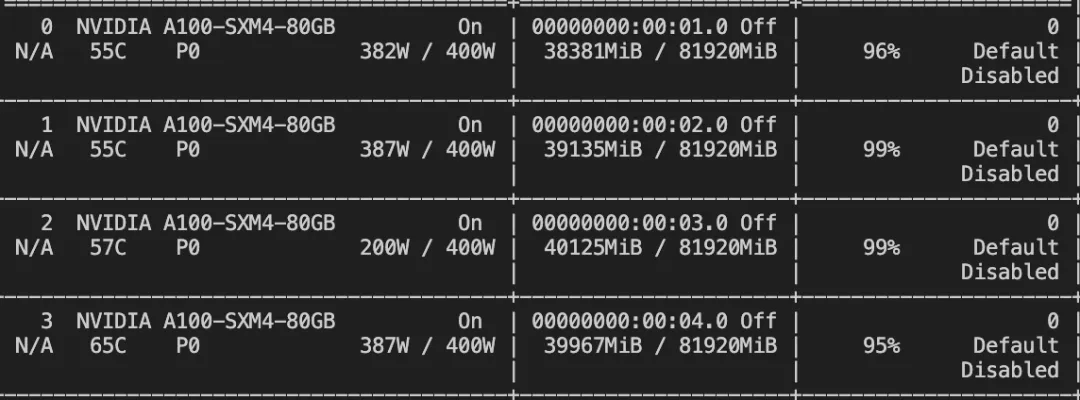
--deepspeed default-zero2微调显存消耗:
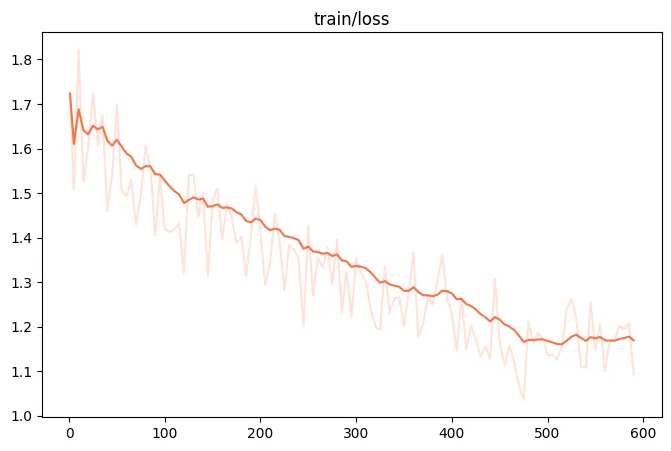
微调过程的loss可视化:
如果要使用自定义数据集,只需按以下方式进行指定:
# val_dataset可选,如果不指定,则会从dataset中切出一部分数据集作为验证集
--dataset train.jsonl \
--val_dataset val.jsonl \自定义数据集支持json和jsonl样式。CogVLM2-Video-Llama-Chat支持多轮对话,但总的对话轮次中需包含一张图片, 支持传入本地路径或URL。以下是自定义数据集的示例:
{"query": "55555", "response": "66666", "videos": ["video_path"]}
{"query": "eeeee", "response": "fffff", "history": [], "videos": ["video_path"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["AAAAA", "BBBBB"], ["CCCCC", "DDDDD"]], "videos": ["video_path"]}微调后推理脚本如下,这里的ckpt_dir需要修改为训练生成的checkpoint文件夹:
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/cogvlm2-video-13b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \你也可以选择merge lora并进行推理:
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/cogvlm2-video-13b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/cogvlm2-video-13b-chat/vx-xxx/checkpoint-xxx-merged \
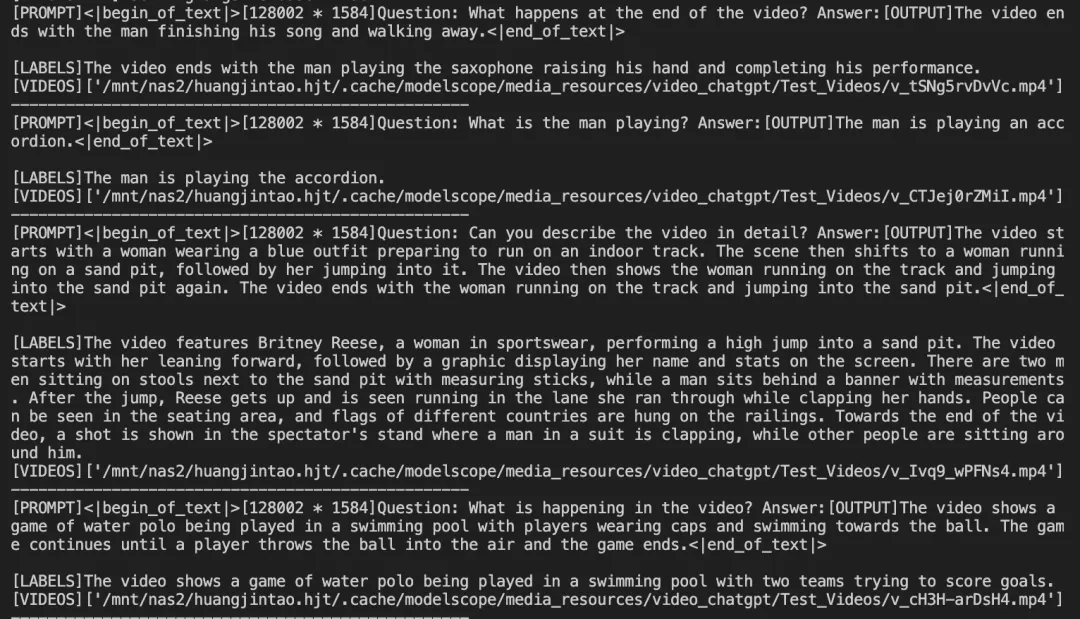
--load_dataset_config true微调后模型对验证集进行推理的示例:

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)