

引言
微软视觉基础模型Florence-2开源了!
Florence-2是一种新颖的视觉基础模型,具有统一的、基于提示的表示,可用于各种计算机视觉和视觉语言任务。虽然现有的VLM在迁移学习方面表现出色,但它们难以用简单的指令执行各种任务,这种能力意味着处理各种空间层次和语义粒度的复杂性。Florence-2 旨在将文本提示作为任务指令,并以文本形式生成理想的结果,无论是字幕、对象检测、基础还是分割。
但是,在各行各业的各种垂直领域任务,Florence-2可能不支持,或者针对某项任务的输出不符合预期。我们可以通过微调来优化和改善Florence-2在垂直领域任务的效果。
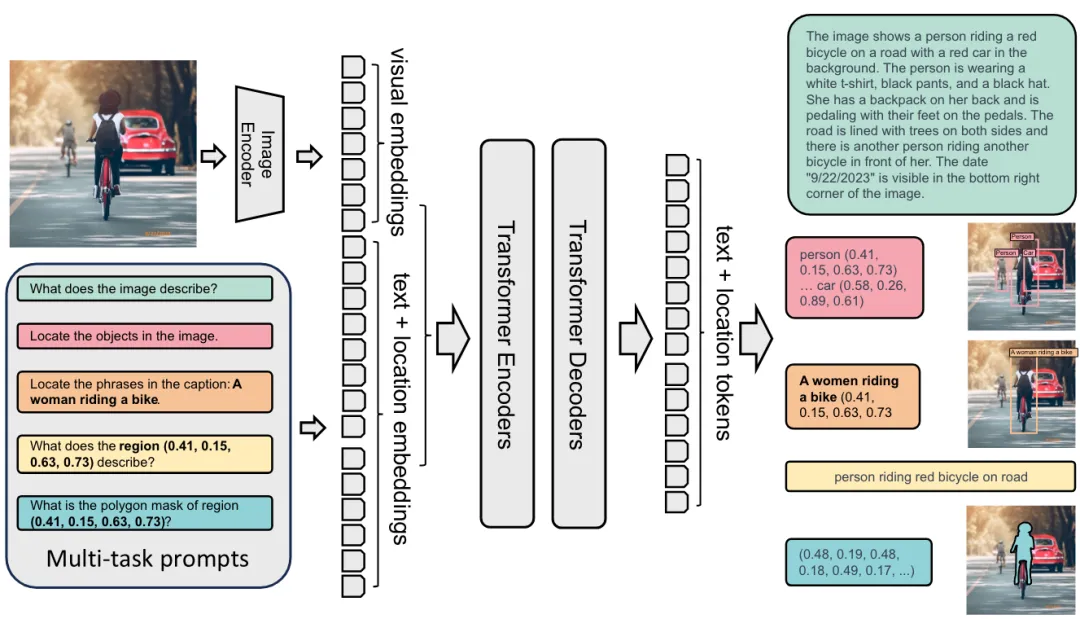
Florence-2是一个sequence to sequence模型,使用 DaViT 视觉编码器将图像转换为视觉Embedding,并使用 BERT 将prompt转换为文本和位置Embedding。Florence-2主要优势在数据上,多任务学习设置需要大规模、高质量的注释数据。为此,Florence-2团队开发了 FLD-5B,它包含 1.26 亿张图像上的 54 亿条综合视觉注释,使用自动图像注释和模型细化的迭代策略。
模型推理
模型链接:
|
模型名称 |
模型链接 |
|
Florence-2-base |
https://www.modelscope.cn/models/AI-ModelScope/Florence-2-base |
|
Florence-2-base-ft |
https://modelscope.cn/models/AI-ModelScope/Florence-2-base-ft |
|
Florence-2-large |
https://modelscope.cn/models/AI-ModelScope/Florence-2-large |
|
Florence-2-large-ft |
https://modelscope.cn/models/AI-ModelScope/Florence-2-large-ft |
模型推理:
import requests
from PIL import Image
from transformers import AutoProcessor, AutoModelForCausalLM
from modelscope import snapshot_download
model_dir = snapshot_download("AI-ModelScope/Florence-2-base")
model = AutoModelForCausalLM.from_pretrained(model_dir, trust_remote_code=True)
processor = AutoProcessor.from_pretrained(model_dir, trust_remote_code=True)
prompt = "<OD>"
url = "http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=prompt, images=image, return_tensors="pt")
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=1024,
do_sample=False,
num_beams=3,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
parsed_answer = processor.post_process_generation(generated_text, task="<OD>", image_size=(image.width, image.height))
print(parsed_answer)模型微调
我们介绍使用ms-swift对Florence-2-large-ft进行目标检测任务的训练, ms-swift是魔搭社区官方提供的LLM工具箱,支持250+大语言模型和35+多模态大模型的微调、推理、量化、评估和部署,包括:Qwen、Llama、GLM、Internlm、Yi、Baichuan、DeepSeek、Llava等系列模型。代码开源地址:https://github.com/modelscope/swift
环境准备
# 设置pip全局镜像 (加速下载)
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 安装ms-swift
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'ms-swift已接入Florence-2系列模型,包括:Florence-2-base, Florence-2-base-ft, Florence-2-large, Florence-2-large-ft。这里我们以refcoco数据集为例, 训练模型的目标检测能力
数据集链接如下:
https://www.modelscope.cn/datasets/swift/refcoco/dataPeview
数据集处理逻辑
以给定目标输出bounding box的目标检测任务为例
Florence-2系列模型输出的Bounding box 的格式为 <loc_{x1}><loc_{y1}><loc_{x2}><loc_{y2}>,其中 (x1, y1) 和 (x2, y2) 分别表示 bounding box 的左下角和右上角的坐标。这些坐标是相对于图像尺寸进行归一化的位置,每个方向被划分为1000等分。
为了更好地持续学习, 我们在微调Florence时保留原模型的输出格式, 具体表现为
-
对数据集中的boundingbox做了相应的转换, 转换逻辑可以用以下方法表示
def process_boundingbox(image, bbox):
"""
Process bounding box coordinates relative to the image dimensions.
Args:
image (PIL.Image): Image object.
bbox (list): List of length four [x1, y1, x2, y2], representing the coordinates of the bounding box's bottom-left (x1, y1) and top-right (x2, y2) corners in pixel coordinates.
Returns:
list: A list containing a formatted string representing the processed bounding box. The string format is '<loc_x1><loc_y1><loc_x2><loc_y2>'.
"""
width = image.width
height = image.height
x1, y1, x2, y2 = [
int(coord / dim * 999) for coord, dim in zip(bbox, [width, height, width, height])
]
return [f'<loc_{x1}><loc_{y1}><loc_{x2}><loc_{y2}>']-
保留Florence-2模型针对特定任务的提示(prompt),例如输出给定目标的bounding box任务,使用原模型的<OPEN_VOCABULARY_DETECTION>提示。将数据集中的模型输入提示转换为原模型支持的提示,转换逻辑可以用以下方法表示:
def process_query(object):
"""
Process the query for the model to search for the target.
Args:
object (str): The target to be searched by the model.
Returns:
str: The model's input prompt formatted as "<OPEN_VOCABULARY_DETECTION>{object}".
"""
return f"<OPEN_VOCABULARY_DETECTION>{object}"-
保留Florence-2模型的输出格式, 例如输出给定目标的bounding box任务, Florence模型以<目标><bbox>的格式输出, 在处理数据集的过程中可以同样保留这样的格式
def process_response(object, processed_bbox):
"""
Combine the object and processed bounding box into a unified response.
Args:
object (str): The object or target related to the response.
processed_bbox (str): The processed bounding box information.
Returns:
str: A unified response string combining the object and processed bounding box.
"""
return object + processed_bbox完整的数据集处理逻辑如下
from PIL import Image
image_path = "/coco2014/train2014/COCO_train2014_000000009231.jpg"
object = "top left suitcase"
bbox = [3,8,380,284]
image = Image.open(image_path)
processed_bbox = process_boundingbox(image, bbox)
query = process_query(object) # <OPEN_VOCABULARY_DETECTION>top left suitcase
response = process_response(object, processed_bbox) # top left suitcase<loc_4><loc_18><loc_593>,<loc_666>ms-swift内置了数据集处理逻辑, 对于给定目标输出bounding box的目标检测任务, 你可以使用内置的refcoco-unofficial-grounding数据集。对于给定boundingbox输出目标的目标检测任务, 数据集处理逻辑类似。你可以使用内置的refcoco-unofficial-caption数据集。
你也可以使用自定义的本地数据集来训练目标检测任务, 格式如下
1. 对于给定bounding box询问目标的任务, 在query中指定`<bbox>`, 在response中指定`<ref-object>`, 在`objects`提供目标和bounding box具体信息
2. 对于给定目标询问bounding box的任务,在query中指定`<ref-object>`, 在response中指定`<bbox>`, 在`objects`提供目标和bounding box具体信息
```jsonl
{"query": "Find <bbox>", "response": "<ref-object>", "images": ["/coco2014/train2014/COCO_train2014_000000001507.jpg"], "objects": "[[\"bottom right sandwich\", [331, 266, 612, 530]]]" }
{"query": "Find <ref-object>", "response": "<bbox>", "images": ["/coco2014/train2014/COCO_train2014_000000001507.jpg"], "objects": "[[\"bottom right sandwich\", [331, 266, 612, 530]]]" }
```训练时使用参数--dataset /path/to/local_dataset
目标检测任务微调
以训练2000份refcoco数据为例, 训练Florence-2-large-ft模型的目标检测能力
这里使用--lora_target_modules ALL来训练整体模型的所有线性层, 你也可以通过指定--lora_target_modules Default来只训练模型的qkv层减少显存占用
# Experimental environment: 4090
# 7GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type florence-2-large-ft \
--dataset refcoco-unofficial-grounding#2000 \
--lora_target_modules ALL
# 2.3GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type florence-2-large-ft \
--dataset refcoco-unofficial-grounding#2000 \
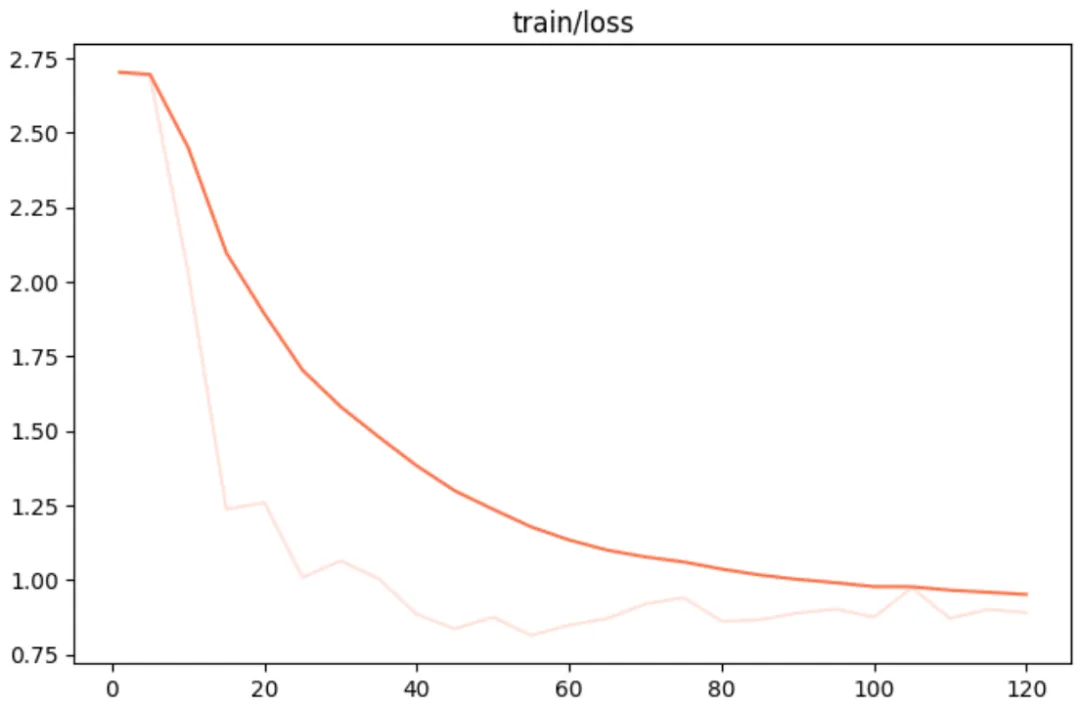
--lora_target_modules DEFAULT训练损失可视化:
资源占用:


微调后模型的推理:
命令行推理
# Experimental environment: 4090
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/florence-2-large-ft/vx-xxx/checkpoint-xxx \
--stream false \
--max_new_tokens 1024推理结果
<<< <OPEN_VOCABULARY_DETECTION>cat
Input a media path or URL <<< /coco2014/train2014/COCO_train2014_000000009231.jpg
{'Locate cat in the image.': 'cat<loc_643><loc_290><loc_998><loc_773>'}
--------------------------------------------------
<<< <OPEN_VOCABULARY_DETECTION>dog laying closest to laptop
Input a media path or URL <<< /coco2014/train2014/COCO_train2014_000000171435.jpg
{'Locate dog laying closest to laptop in the image.': 'dog laying closest to laptop<loc_106><loc_449><loc_660>,<loc_627>'}推理可视化
我们可以对模型输出的 bounding box 进行可视化, 参考代码如下
from PIL import Image, ImageDraw
import re
def visualize_bounding_box(img, bbox):
img_width, img_height = img.size
numbers = re.findall(r'\d+', bbox)
x1, y1, x2, y2 = [int(num) for num in numbers]
x1 = int((x1 / 999) * img_width)
y1 = int((y1 / 999) * img_height)
x2 = int((x2 / 999) * img_width)
y2 = int((y2 / 999) * img_height)
draw = ImageDraw.Draw(img)
# 绘制bounding box
draw.rectangle([x1, y1, x2, y2], outline="red", width=2)
img.show()
# img.save("output_image.jpg")
img_path = "/coco2014/train2014/COCO_train2014_000000171435.jpg"
img = Image.open(img_path)
bbox = '<loc_643><loc_290><loc_998><loc_773>'
visualize_bounding_box(img, bbox)
可视化结果
{'Locate cat in the image.': 'cat<loc_643><loc_290><loc_998><loc_773>'}

{'Locate dog laying closest to laptop in the image.': 'dog laying closest to laptop<loc_106><loc_449><loc_660>,<loc_627>'}


点击链接👇直达原文
https://modelscope.cn/models?name=Florence-2&page=1?from=csdnzishequ_text?from=csdnzishequ_text








 已为社区贡献665条内容
已为社区贡献665条内容

所有评论(0)