
ChatTTS:专为对话场景设计的文本转语音模型,底模开源!
最近,开源社区杀出一匹文本转语音领域的黑马——ChatTTS,在Github上仅4天斩获11.2k star。
引 言
最近,开源社区杀出一匹文本转语音领域的黑马——ChatTTS,在Github上仅4天斩获11.2k star。
https://github.com/2noise/ChatTTS
ChatTTS是一个专门为对话场景设计的文本转语音模型,例如众所周知的GPT-4o这样的LLM助手对话任务。ChatTTS支持英文和中文两种语言,最大的模型使用了10万小时以上的中英文数据进行训练。在HuggingFace中开源的版本为4万小时训练且未SFT的版本。
模型亮点:
-
对话式 TTS: ChatTTS针对对话式任务进行了优化,实现了自然流畅的语音合成,同时支持多说话人。
-
细粒度控制: 该模型能够预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等。
-
更好的韵律: ChatTTS在韵律方面超越了大部分开源TTS模型。同时提供预训练模型,支持进一步的研究。
目前模型也开源至ModelScope魔搭社区,社区免费算力即可玩转,感谢社区开发者pzc-163,社区开发者还搭建了创空间可直接体验👇
模型下载
在魔搭社区可下载ChatTTS模型
模型链接:https://modelscope.cn/models/pzc163/chatTTS
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('pzc163/chatTTS')模型推理
使用魔搭社区免费算力,完成模型推理
# pip install -r requirement.txt
# pip install Ipython
# pip install soundfile
from ChatTTS import Chat
from IPython.display import Audio
#下载模型
from modelscope import snapshot_download
model_dir = snapshot_download('pzc163/chatTTS')
chat = Chat()
chat.load_models(source='local', local_path=model_dir)
texts = ["你好,我是ChatTTS,很高兴认识大家",]
wavs = chat.infer(texts, use_decoder=True)
Audio(wavs[0], rate=24_000, autoplay=True)
# save audio
import soundfile as sf
audio_data = wavs[0]
if len(audio_data.shape) > 1:
audio_data = audio_data.flatten()
output_file = './output_audio2.wav'
sf.write(output_file, audio_data, 24000)
print(f"Audio saved to {output_file}")搭建Web-UI体验
体验地址:
https://modelscope.cn/studios/AI-ModelScope/ChatTTS-demo/summary
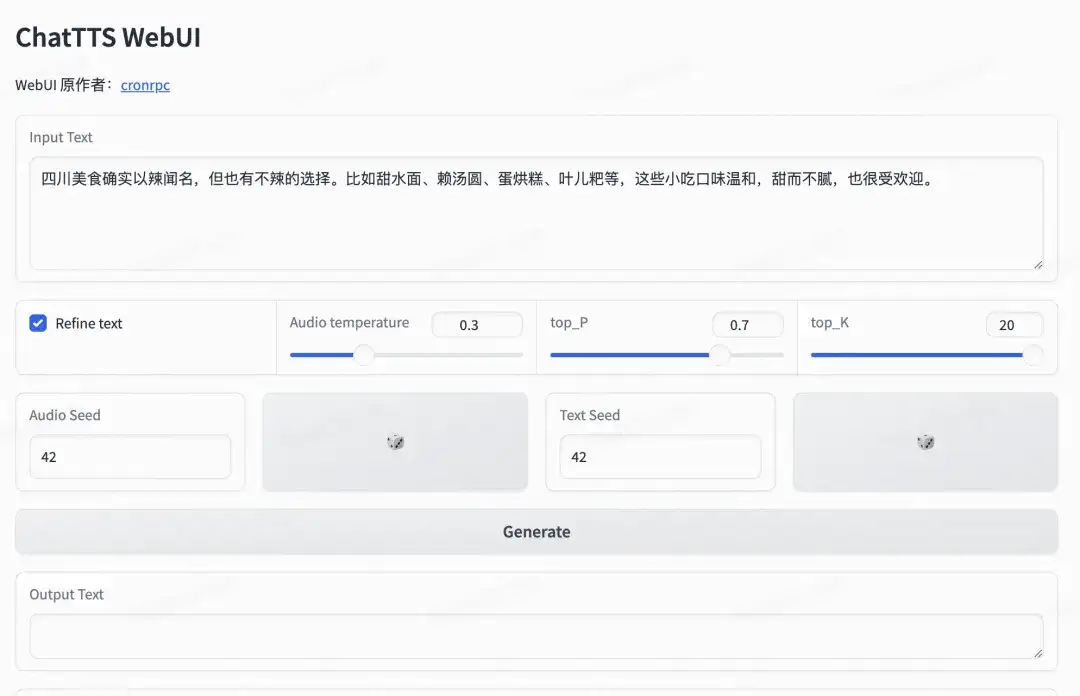
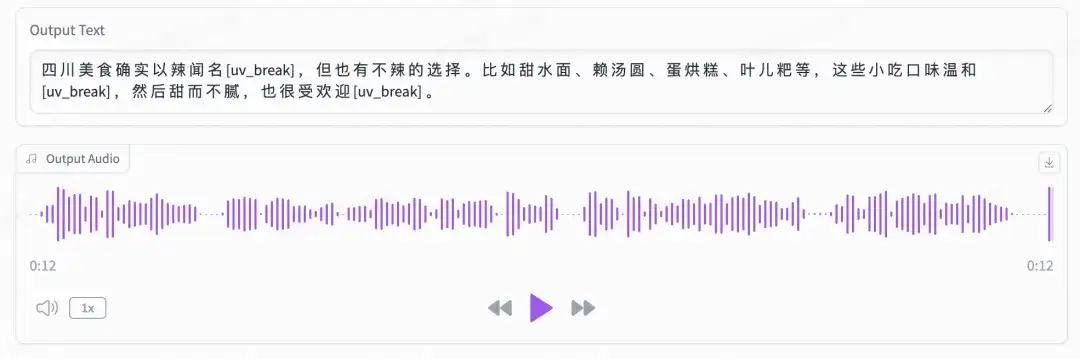
同时也可以使用如下命令👇,将该创空间clone下来,运行如下代码,就可以拥有自己专属的ChatTTS WebUI啦!
git clone https://www.modelscope.cn/studios/AI-ModelScope/ChatTTS-demo.git
cd ChatTTS
pip install -r requirements.txt
python app.py点击链接👇直达体验~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 1
1- 0



 已为社区贡献665条内容
已为社区贡献665条内容

所有评论(0)