
千亿大模型来了!通义千问110B模型开源,魔搭社区推理、微调最佳实践
近期开源社区陆续出现了千亿参数规模以上的大模型,这些模型都在各项评测中取得杰出的成绩。今天,通义千问团队开源1100亿参数的Qwen1.5系列首个千亿参数模型Qwen1.5-110B,该模型在基础能力评估中与Meta-Llama3-70B相媲美,在Chat评估中表现出色,包括MT-Bench和AlpacaEval 2.0。
Qwen1.5-110B与其他Qwen1.5模型相似,采用了相同的Transformer解码器架构。它包含了分组查询注意力(GQA),在模型推理时更加高效。该模型支持32K tokens的上下文长度,同时它仍然是多语言的,支持英、中、法、西、德、俄、日、韩、越、阿等多种语言。
下图为基础语言模型效果评估,并与最近的SOTA语言模型Meta-Llama3-70B以及Mixtral-8x22B进行了比较。
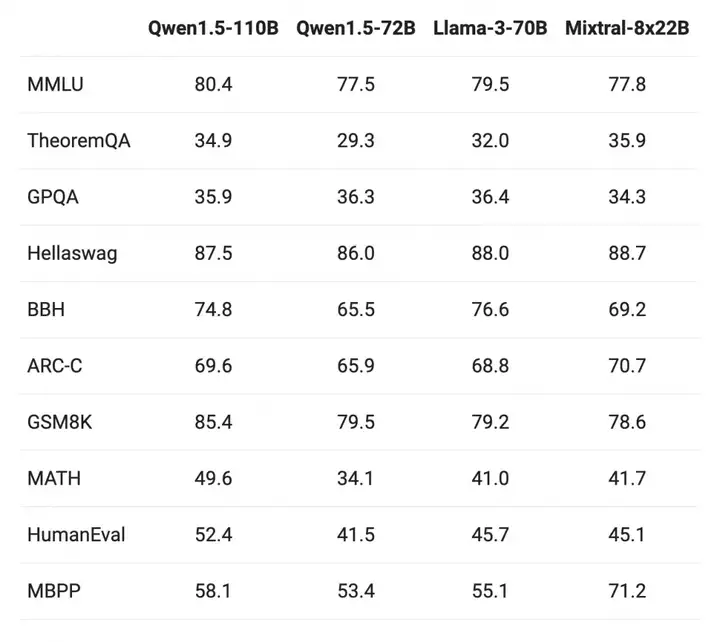
上述结果显示,千问110B模型在基础能力方面至少与Llama-3-70B模型相媲美。在这个模型中,没有对预训练的方法进行大幅改变,因此110B模型和72B相比的性能提升主要来自于增加模型规模。
在MT-Bench和AlpacaEval 2.0上进行了Chat评估,结果如下:
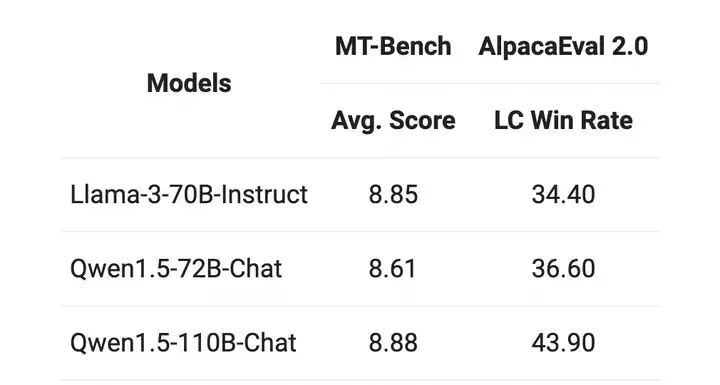
与之前发布的Qwen1.5-72B模型相比,在两个Chat模型的基准评估中,110B表现显著更好。评估结果的持续改善表明,即使在没有大幅改变后训练方法的情况下,更强大、更大规模的基础语言模型也可以带来更好的Chat模型。
Qwen1.5-110B是Qwen1.5系列中规模最大的模型,也是该系列中首个拥有超过1000亿参数的模型。它在与最近发布的SOTA模型Llama-3-70B的性能上表现出色,并且明显优于72B模型。这告诉我们,在模型大小扩展方面仍有很大的提升空间。虽然Llama-3的发布表明预训练数据规模具有重要意义,但我们相信通过在未来的发布中同时扩展数据和模型大小,我们可以同时获得两者的优势。敬请期待Qwen2!
小编划重点:
- 首个千亿级模型来袭,Qwen1.5-110B,今天发布了base和chat模型,量化模型和GGUF模型也将会发布。
- Qwen1.5-110B相比72B效果有很大的提升,该提升主要来自模型规模的提升。
- Qwen1.5-110B和最近发布的SOTA模型Llama-3-70B的性能上相比不分伯仲,未来通义千问团队将会探索模型规模提升和扩展预训练数据规模两种方法同时带来的优势,请大家期待Qwen2!
魔搭社区最佳实践
模型体验:
体验链接:
https://modelscope.cn/studios/qwen/Qwen1.5-110B-Chat-demo
为了便于大家比较,社区搭建了Llama3-70B-Instruct和Qwen1.5-110B-Chat的对比环境,体验链接:
https://www.modelscope.cn/studios/LLM-Research/Llama3-Qwen1.5-Arena
例如,多语言能力:

小学数学so easy:
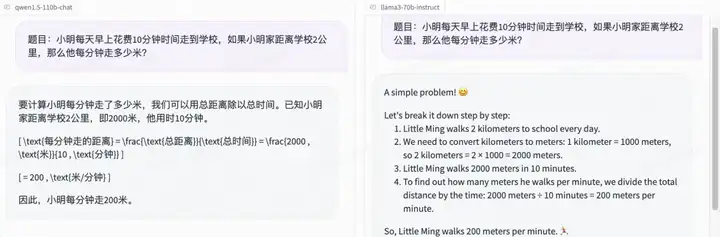
再难一点也不在话下:

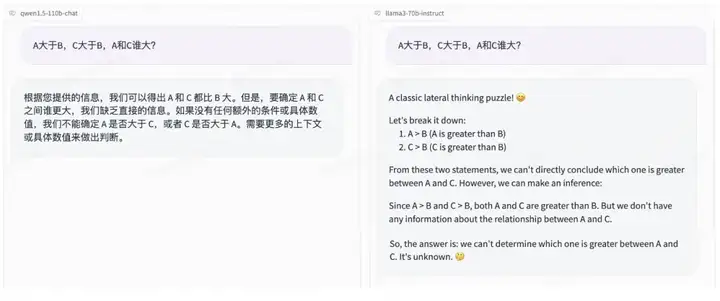
逻辑能力:
模型下载
模型链接:
Qwen1.5-110B-Chat:
https://www.modelscope.cn/models/qwen/Qwen1.5-110B-Chat
Qwen1.5-110B:
https://www.modelscope.cn/models/qwen/Qwen1.5-110B
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen1.5-110B-Chat')模型推理
推理代码:
from modelscope import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"qwen/Qwen1.5-110B-Chat",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen1.5-110B-Chat")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
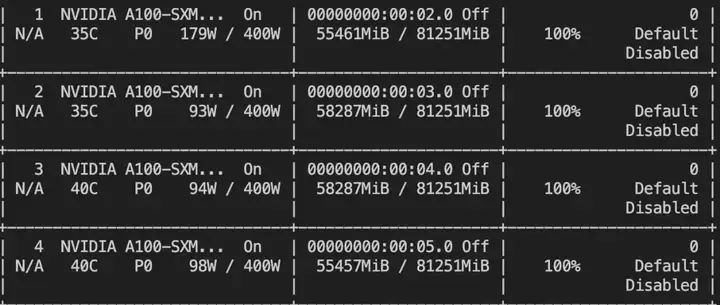
显存要求(4卡A100,230G显存):
模型训练
魔搭社区的微调框架SWIFT已经支持了Qwen1.5全系列模型的微调和推理。
下面我们以自我认知任务为例针对千问1.5-110b-chat模型为例给出训练参数配置:
nproc_per_node=4
CUDA_VISIBLE_DEVICES=0,1,2,3 \
NPROC_PER_NODE=$nproc_per_node \
swift sft \
--model_type qwen1half-110b-chat \
--sft_type lora \
--tuner_backend peft \
--dtype AUTO \
--output_dir output \
--ddp_backend nccl \
--num_train_epochs 2 \
--max_length 2048 \
--check_dataset_strategy warning \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.05 \
--lora_target_modules ALL \
--gradient_checkpointing true \
--batch_size 1 \
--weight_decay 0.1 \
--learning_rate 1e-4 \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10 \
--use_flash_attn true \
--deepspeed default-zero3 \
--self_cognition_sample 2000 \
--model_name 小白 'Xiao Bai' \
--model_author 魔搭 ModelScope \
训练loss:
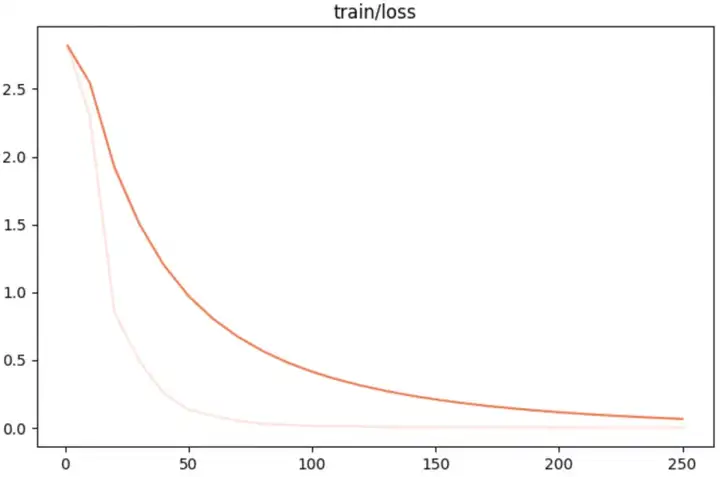
可以看到其收敛非常平滑。
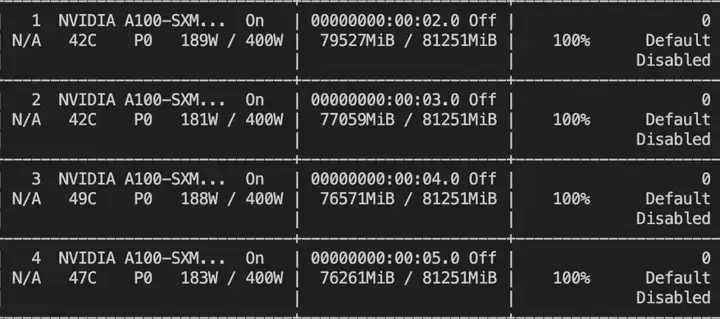
训练的显存使用情况:
训练后推理可以使用如下脚本(注意将--ckpt_dir替换为训练log输出的weights路径):
# Experimental environment: 4*A100
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift infer \
--ckpt_dir "/output/qwen1half-110b-chat/vx-xxx/checkpoint-xx" \
--load_dataset_config true \
--max_length 2048 \
--eval_human true \
--use_flash_attn false \
--max_new_tokens 2048 \
--temperature 0.1 \
--top_p 0.7 \
--repetition_penalty 1. \
--do_sample true \
--merge_lora_and_save false \自我认知对话测试:

通用对话测试:


ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)