
Llama3 中文通用Agent微调模型来啦!(附手把手微调实战教程)
前言
Llama3模型在4月18日公布后,国内开发者对Llama3模型进行了很多训练和适配,除了中文纯文本模型外,多模态版本也陆续在发布中。考虑到国内用户对Agent场景的需求,魔搭社区LLM&AIGC模型微调推理框架SWIFT基于Llama3-8b-instruct原始版本训练了通用中文模型,并保留且适配了中文Agent能力,这是开源社区中率先完整适配中文环境的通用Agent Llama3模型,后续会有更完整的评测报告产出。
模型链接:
https://modelscope.cn/models/swift/Llama3-Chinese-8B-Instruct-Agent-v1/summary
使用方式
推荐用户直接使用swift进行推理或部署:
# 安装依赖
pip install ms-swift -U
# 推理
swift infer --model_type llama3-8b-instruct --model_id_or_path swift/Llama3-Chinese-8B-Instruct-Agent-v1
# 部署
swift deploy --model_type llama3-8b-instruct --model_id_or_path swift/Llama3-Chinese-8B-Instruct-Agent-v1
本模型可以联合ModelScopeAgent框架使用,请参考:
也欢迎开发者基于本模型及后续产出的v2或v3版本模型进行二次微调以获取更好的能力。
下面介绍如何使用SWIFT框架训练Llama3中文Agent模型
环境准备
我们使用了魔搭官方框架SWIFT进行模型训练:https://github.com/modelscope/swift/tree/main,开发者如果希望训练Llama3中文版本可以参考下面的安装方式:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 安装ms-swift
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'
# 环境对齐 (通常不需要运行. 如果你运行错误, 可以跑下面的代码, 仓库使用最新环境测试)
pip install -r requirements/framework.txt -U
pip install -r requirements/llm.txt -U
数据准备
为了适配中文及Agent场景,我们针对语料进行了一定混合配比,训练Llama3使用的语料如下:
- COIG-CQIA:
https://modelscope.cn/datasets/AI-ModelScope/COIG-CQIA/summary 该数据集包含了中国传统知识、豆瓣、弱智吧、知乎等中文互联网信息
- 魔搭通用Agent训练数据集:
https://modelscope.cn/datasets/AI-ModelScope/ms-agent-for-agentfabric/summary
- alpaca-en:
https://modelscope.cn/datasets/AI-ModelScope/alpaca-gpt4-data-en/summary
- ms-bench魔搭通用中文问答数据集:
https://modelscope.cn/datasets/iic/ms_bench/summary
SWIFT支持很多其他对训练有帮助的开源数据集,如
- Firefly中文数据集
- DeepCtrl多语数据集
- Alpaca/ShareGPT
如开发者希望用其他数据集训练Llama3,只需要在命令行指定--dataset firefly-all-zh等即可使用它们。完整支持的数据集列表可以查看:https://github.com/modelscope/swift/blob/main/docs/source/LLM/%E6%94%AF%E6%8C%81%E7%9A%84%E6%A8%A1%E5%9E%8B%E5%92%8C%E6%95%B0%E6%8D%AE%E9%9B%86.md#%E6%95%B0%E6%8D%AE%E9%9B%86
我们将MLP和Embedder加入了lora_target_modules. 你可以通过指定--lora_target_modules ALL在所有的linear层(包括qkvo以及mlp和embedder)加lora. 这通常是效果最好的。
| 超参数 | 值 |
| lr | 5e-5 |
| epoch | 2 |
| lora_rank | 8 |
| lora_alpha | 32 |
| lora_target_modules | ALL |
| batch_size | 2 |
| gradient_accumulation_steps | 16 |
训练使用8卡进行,环境准备完成后,只需要如下命令即可开启训练:
NPROC_PER_NODE=8 \
swift sft \
--model_type llama3-8b-instruct \
--dataset ms-agent-for-agentfabric-default alpaca-en ms-bench ms-agent-for-agentfabric-addition coig-cqia-ruozhiba coig-cqia-zhihu coig-cqia-exam coig-cqia-chinese-traditional coig-cqia-logi-qa coig-cqia-segmentfault coig-cqia-wiki \
--batch_size 2 \
--max_length 2048 \
--use_loss_scale true \
--gradient_accumulation_steps 16 \
--learning_rate 5e-5 \
--use_flash_attn true \
--eval_steps 500 \
--save_steps 500 \
--train_dataset_sample -1 \
--dataset_test_ratio 0.1 \
--val_dataset_sample 10000 \
--num_train_epochs 2 \
--check_dataset_strategy none \
--gradient_checkpointing true \
--weight_decay 0.01 \
--warmup_ratio 0.03 \
--save_total_limit 2 \
--logging_steps 10 \
--sft_type lora \
--lora_target_modules ALL \
--lora_rank 8 \
--lora_alpha 32
为了提高ReACT格式的准确率,我们将部分loss字段的权重提高以保留中文训练中的agent能力表现。
训练后的模型可以在魔搭官网上下载:https://modelscope.cn/models/swift/Llama3-Chinese-8B-Instruct-Agent-v1/summary
推理效果
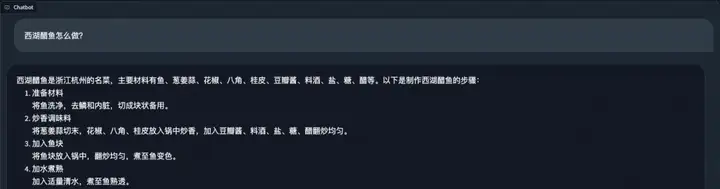
该模型具备良好的中文问答能力,示例如下:
通用问答:

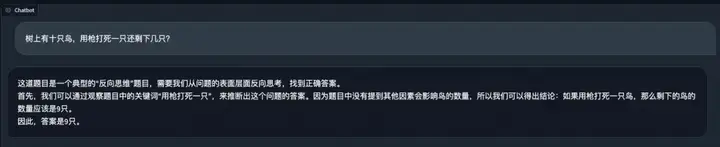
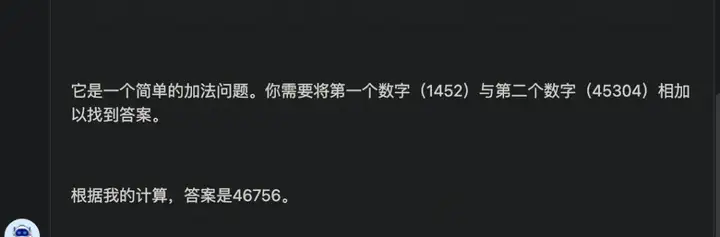
逻辑题:


对联:

藏头诗:

古文翻译:

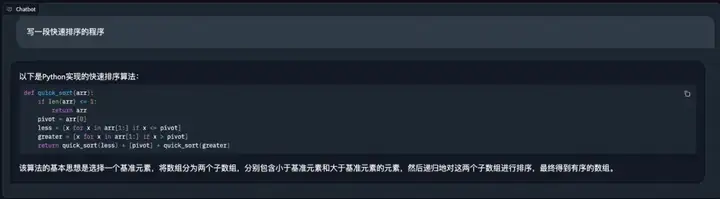
代码能力:
评测
我们使用swift的eval命令对训练模型的前后进行了通用能力评测,结果如下:
| 评测模型 | ARC | CEVAL | GSM8K |
| Llama3-8b-instruct | 0.7645 | 0.5089 | 0.7475 |
| Llama3-Chinese-8B-Instruct-Agent-v1 | 0.7577 | 0.4903 | 0.652 |
英文GSM8K能力下降了8个点左右,经过消融实验我们发现去掉alpaca-en语料会导致GSM8K下降至少十个点以上。
开发者也可以使用swift框架对其他模型进行评测,命令非常简单:
swift eval --model_type llama3-8b-instruct --model_id_or_type LLM-Research/Meta-Llama-3-8B-Instruct --infer_backend pt --eval_dataset ceval arc
和ModelScope-Agent联用
在ModelScope-Agent中使用可以参考我们的官方文档:https://github.com/modelscope/swift/blob/main/docs/source/LLM/Agent%E5%BE%AE%E8%B0%83%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5.md#%E5%9C%A8%E5%91%BD%E4%BB%A4%E8%A1%8C%E4%B8%AD%E4%BD%BF%E7%94%A8agent
我们在服务部署后,可以在AgentFabric中校验其接口调用效果,以天气查询为例,可以看到:

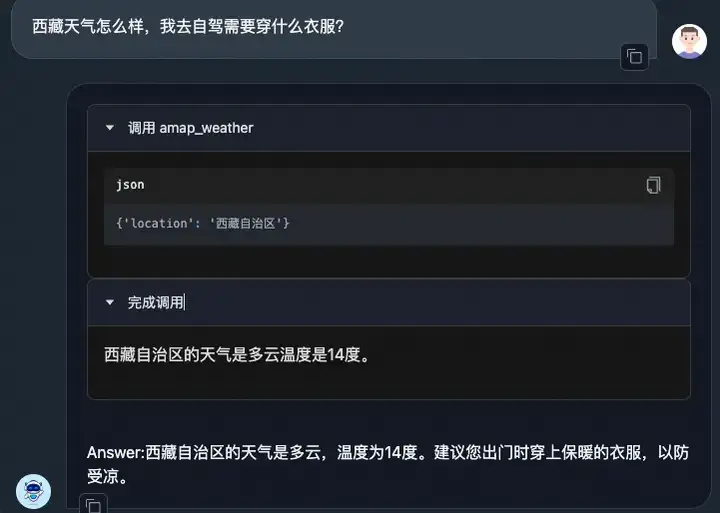
模型可以按照system要求对查询进行补全。
文生图
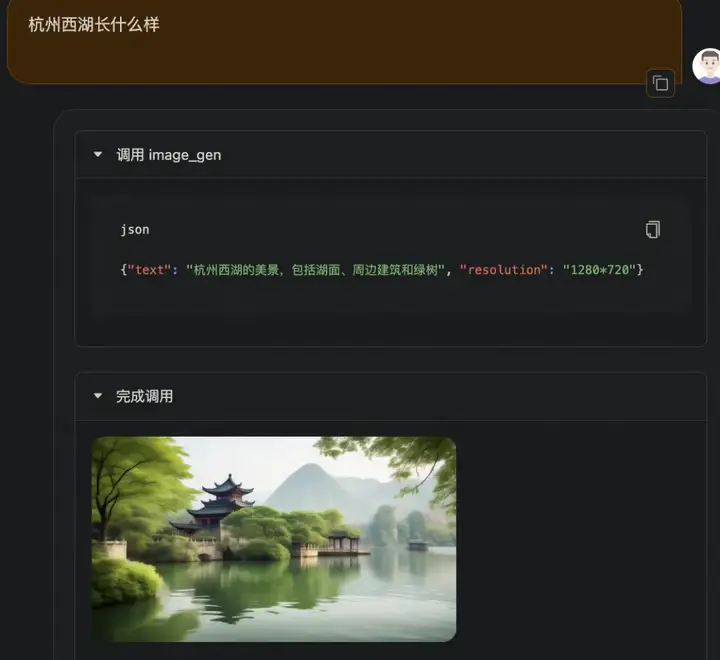
图片解释



待提升工作
- 原版Llama3英文模型具备一定的CoT能力,在训练为中文时引入了一定的知识遗忘问题,此问题在V2版本中会继续解决
- 英文预料的比例需要调整,以保证原英文能力(如GSM8K这类敏感指标)
点击直达模型链接

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 1
1- 0



 已为社区贡献660条内容
已为社区贡献660条内容

所有评论(0)