
社区供稿 | 一张照片跳舞的AnimateAnyone社区开发者复刻版,开源!
引言
日前,兵马俑跳科目三、奶牛猫跳洗澡舞等趣味和魔性的短视频在社交媒体上出圈,背后“一张照片来跳舞”的技术来自阿里通义实验室在可控动画生成领域的一项研究工作——AnimateAnyone。
AnimateAnyone是一种能够将角色图像转换为所需姿势序列控制的动画视频的方法,继承了diffusion模型的网络设计和预训练权重,并修改了UNet以适应多帧输入。为了解决保持外观一致性的挑战,引入了referenceNet,专门设计为UNet结构来捕获参考图像的空间细节。
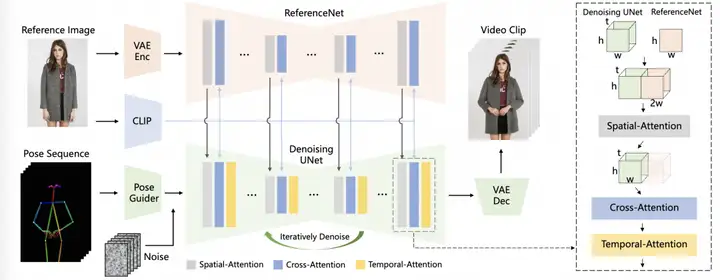
pose sequence使用pose guide进行编码,并与多帧噪声融合,然后由去噪UNet进行去噪处理来生成视频,去噪的UNet模块中计算block由空间attention,cross-attention,以及时间attention组成,如右侧的虚线框。首先通过ReferenceNet提取细节特征并用于空间注意力,再通过CLIP图像编码器提取语义特征用于cross-attention,时间attention在时间维度上运作。最后通过VAE解码器解码为视频片段。
论文地址:
https://arxiv.org/pdf/2311.17117.pdf
社区复现和使用方式
社区开发者使用SVD复刻了AnimateAnyone,基于SVD的pipeline,同时使用simswap提高面部质量和时间一致性,并发布了V1版本的推理代码和模型,模型checkpoint可以在魔搭社区下载。
开源代码:
https://github.com/bendanzzc/AnimateAnyone-reproduction
开源模型:
https://modelscope.cn/models/lightnessly/animate-anyone-v1/summary
1.下载AnimateAnyone-reproduction代码
# 使用modelscope官方镜像环境
git clone https://github.com/bendanzzc/AnimateAnyone-reproduction.git2.下载相关模型
2.1 下载SVD/svd_14模型
git clone https://www.modelscope.cn/AI-ModelScope/stable-video-diffusion-img2vid-xt.git
2.2 下载AnimateAnyone复现相关模型
git clone https://www.modelscope.cn/lightnessly/animate-anyone-v1.git3.替换相关文件
下载AnimateAnyone复现相关模型和SVD/svd_14模型后,将stable-video-diffusion-img2vid-xt/unet下的文件删除,替换为animate-anyone-v1/unet路径下的文件
4.替换推理代码相关参数
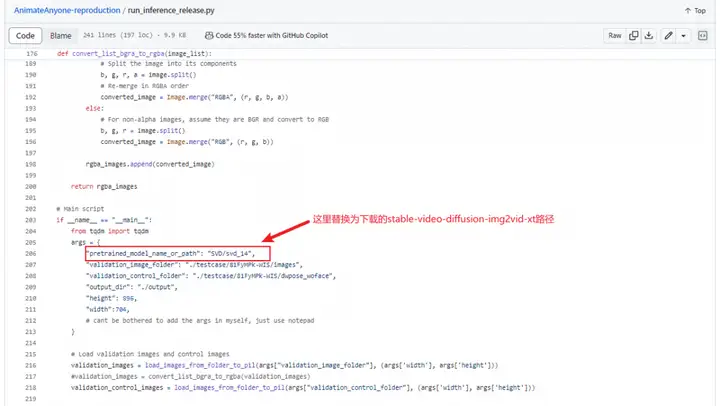
4.1 替换SVD为本地下载的模型路径
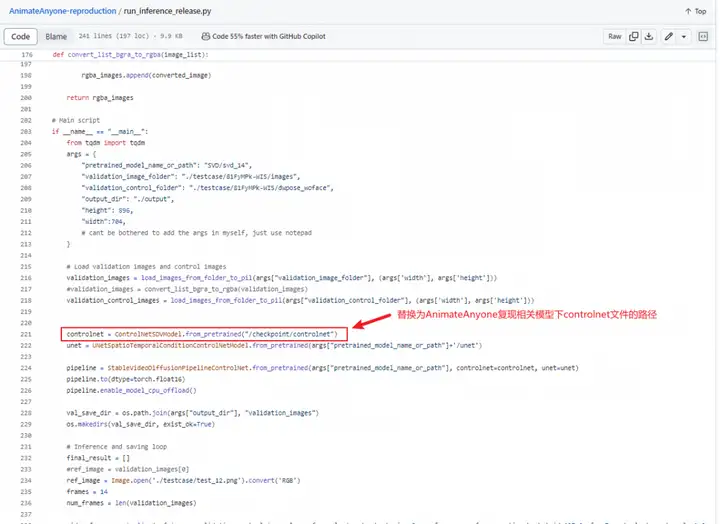
4.2 将controlnet的路径替换为AnimateAnyone复现相关模型下controlnet文件的路径,通常为animate-anyone-v1/controlnet
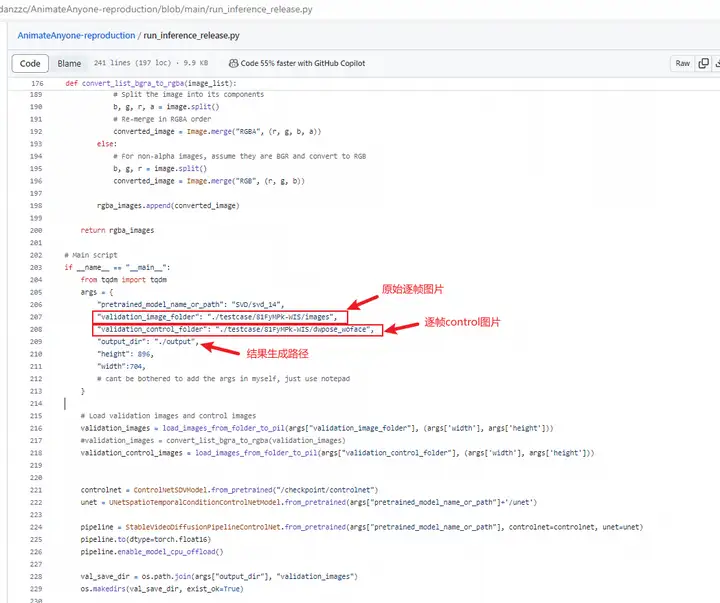
5.其他参数
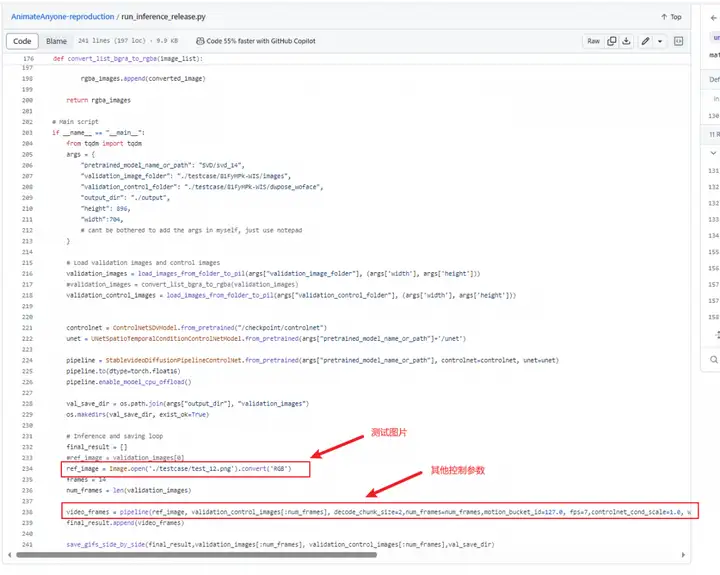
6.执行推理
运行AnimateAnyone-reproduction代码中的run_inference_release.py
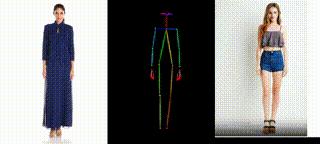
测试效果演示:
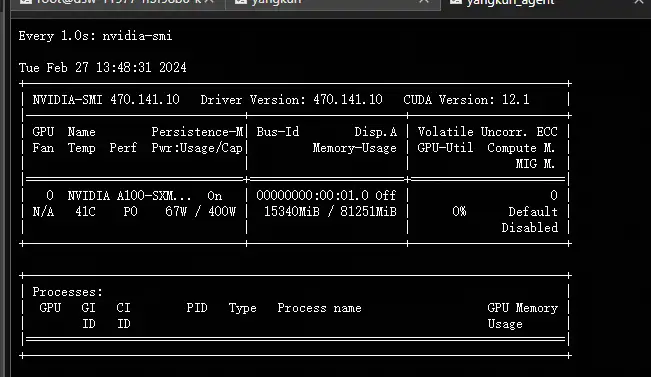
显存要求:
如果想体验原版AnimateAnyone,可下载通义千问app,输入“全民舞王” ,产品端提供了更丰富的预设舞蹈模板、更长时长的生成效果。
魔搭社区积极鼓励开发者参照相关论文进行实践复现,并乐于分享他们的checkpoint文件与源代码,以更有力地推动人工智能技术的持续发展与进步。
投稿邮箱:
modelscopesubmit@list.alibaba-inc.com

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献665条内容
已为社区贡献665条内容

所有评论(0)