
Jina AI 发布中英和英德双语 8K 向量模型,魔搭社区开源最佳实践!
引 言
作为多模态人工智能技术领域的翘楚,Jina AI 的使命是通过创新的向量大模型和提示词技术,铺平通往多模态 AI 的未来之路。我们正在积极扩展多语言产品线,以满足更广泛的客户需求。
在 Jina Embeddings 英语向量模型突破百万下载后,今天,Jina AI正式开源了两款双语向量模型:中英双语(Chinese-English)和英德双语(English-German)向量模型,这也是全球首次推出支持 8K 双语文本的开源向量模型。
技术亮点
8K 输入:长文本处理更得心应手
在 RAG 应用里,文本就像被切成了多个块,通过 Embedding 模型变成向量,然后存进数据库。当你搜索时,系统会把这些文本块的向量和你的搜索词比对,找到最匹配的文本。
传统模型最多只能处理 512 Token 的文本,面对更长文本时,就力不从心,尤其是预测的时候。
但 Jina Embeddings v2 能处理高达 8k 的输入,能够实现从实体、句子、段落到整个篇章的多粒度向量表示。实际应用的时候,可以将这些不同层次的向量结合起来,实现更为精准的匹配。此外,也支持按语义切割,获得更佳的搜索效果。
8K token,也就是说一整版人民日报的内容可以压缩成一个向量!
技术创新:JinaBert 架构
Jina Embeddings 系列模型均基于 Jina AI 自研的 JinaBert 架构,这是首次将 ALiBi 应用到编码器上,该架构专为长文本任务优化,直接在 Attention 层处理位置信息,让模型更准确地捕捉词语间的关系。就算是超长文本,也能轻松应对。
这一技术创新让我们的模型在处理长文本时更加强大,也为 RAG 应用带来了更多可能性。无论是解读法律文件、研究医学文献、还是文学分析,Jina Embeddings 系列模型都表现出色,任务的准确率和效率都大大提升。
双语支持:无缝跨语言交互
我们的双语模型能把中文(或德文)和英文映射到同一个向量空间。即使是不同语言,只要含义相近,它们在向量空间里就很接近。
尽管很多模型也声称支持多种语言,但由于英语在互联网上的主导地位,以及训练阶段大量使用机器翻译文本,这些模型往往对某些人群、主题或话题存在偏见,其影响会在下游任务中进一步放大。Jina AI 则专注于优化 2 种语言的向量表征,严格把关训练数据,力求把偏见降到最低,并确保性能超越那些支持多语言的大型模型。
用 Jina Embeddings,不管是在 RAG 聊天机器人里,还是给文本分类、做摘要、分析情感,都能把不同语言的文本当作同一种语言来处理,让多语言应用的构建变得无比丝滑。用中文搜中文资料,或者中文搜英文、英文搜中文,都能得到又准又顺的结果。Jina Embeddings 助力您打造和全球用户无障碍沟通的新时代!
MTEB 排行榜:性能领先
Jina Embeddings v2 系列模型在 MTEB 排行榜上,在文本分类、检索、重排、摘要等任务上均有优势。并且输出结构和 OpenAI 完全一致,是 OpenAI ada 002 模型的理想替代开源解决方案。
jina-embeddings-v2 的双语模型以 322MB 的轻巧体积(包含 1.61 亿参数),输出维度为 768,能够在普通计算机硬件上高效运行,无需依赖 GPU,极大地提升了其实用性和便捷性。
最近,在 Standford HAI 发布的 LoCo 性能测试中,Jina Embeddings 同样名列前茅。

为了在命中率和 MRR 方面实现最佳性能,OpenAI、Jina Embeddings 与 CohereRerank/bge-reranker-large reranker 的组合脱颖而出。-- LlamaIndex
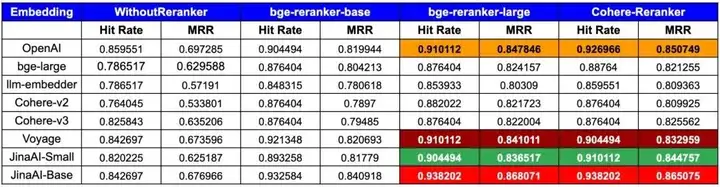
魔搭社区最佳实践
模型链接
Jina AI文本向量模型v2-base-中英双语
https://modelscope.cn/models/jinaai/jina-embeddings-v2-base-zh/summary
Jina AI文本向量模型v2-base-德英双语
https://modelscope.cn/models/jinaai/jina-embeddings-v2-base-de/summary
模型推理
Jina AI文本向量模型v2-base-中英双语
!pip install modelscope
from modelscope import AutoModel
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True) # trust_remote_code is needed to use the encode method
embeddings = model.encode(['How is the weather today?', '今天天气怎么样?'])
print(cos_sim(embeddings[0], embeddings[1]))
同时也可以使用Jina的官方API。
API 集成
使用 Jina Embeddings 的最简单方法是直接使用 Jina AI 的 Embedding API。
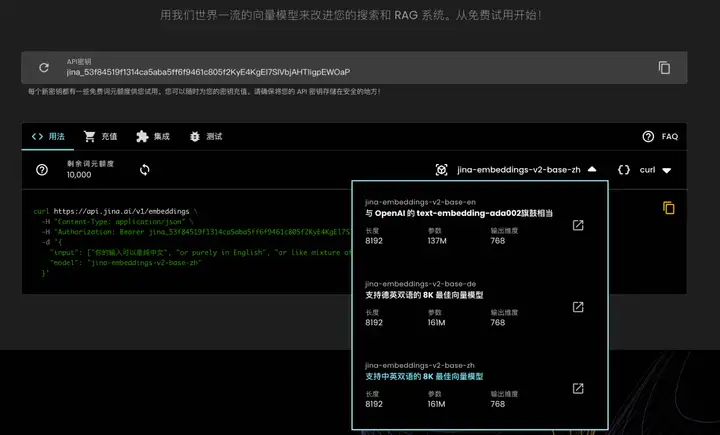
通过Jina的官网 jina.ai/embeddings,您还可以体验文本相似度测试。
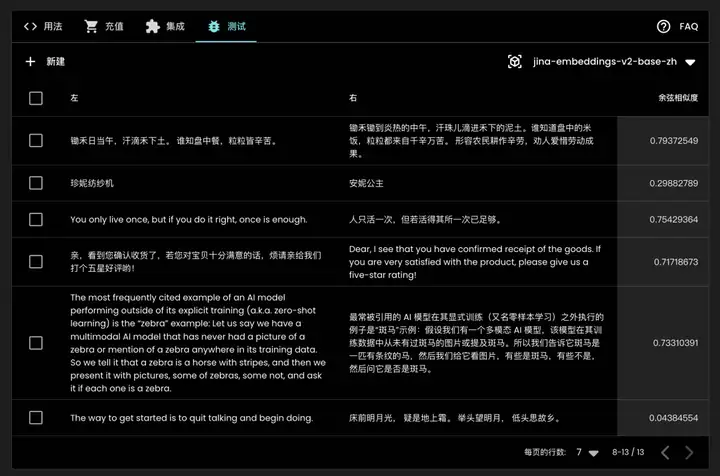
此外,Jina Embeddings 的 API 与 OpenAI 的 API 完全兼容,因此您可以轻松地将 Jina Embeddings 与现有应用集成。
Jina Embeddings 已经与十多个向量数据库和 RAG 系统集成,您可以根据自己的需求进行选择。
私有化部署
通过应用市场一键部署到您的企业云上,包括阿里云、AWS Sagemaker、Google Cloud Platform 等。
未来展望
Jina AI 将持续扩展我们的多语言 8k 向量模型家族,支持更多语言。同时,我们正推进这些模型与更多合作平台的集成,助力开发者们丝滑使用 Jina Embeddings,实现更丰富的应用场景。我们也将继续在多模态 AI 领域深耕细作,构建出更为强大、灵活的 AI 解决方案。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献662条内容
已为社区贡献662条内容

所有评论(0)