
InstantID:一张照片,无需训练,秒级个人写真生成
引言
InstantID 是由InstantX项目组推出的一种SOTA的tuning-free方法,只需单个图像即可实现 ID 保留生成,并支持各种下游任务。

在InstantID这样的技术之前,结合 Textual Inversion、DreamBooth 和 LoRA 等方法,个性化图像合成取得了重大进展。过去的方案,通常需要结合微调,需要较多的样本图片,较高的显存要求,以及较长的训练时间,导致了成本较高。
为了解决如上的这些要求,InstantID的即插即用模块仅使用单个面部图像就能熟练地处理各种风格的图像个性化,同时确保高保真度。InstantID设计了一种新颖的 IdentityNet,通过强加语义和弱空间条件,将面部和地标图像与文本提示相结合来引导图像生成。InstantID与流行的预训练文本到图像扩散模型(如 SD1.5 和 SDXL)无缝集成,作为一个适应性强的插件。
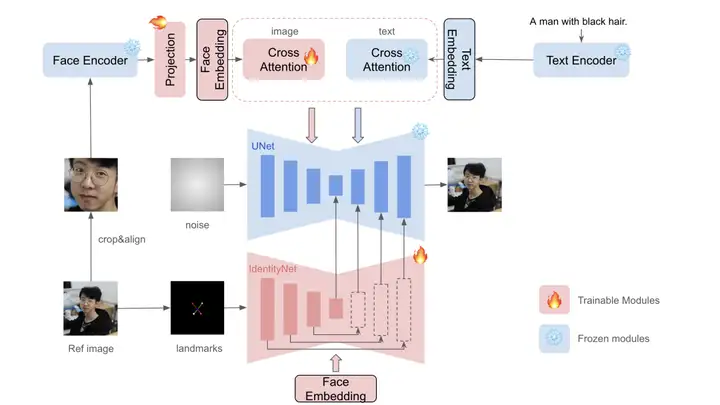
InstantID 的整体流程由三部分组成,以保持高面部保真度。
首先,InstantID采用Face Encoder而不是 CLIP 来提取语义人脸特征,并使用可训练的投影层将它们投影到文本特征空间。 我们将投影的特征作为Face Embedding。
然后,引入具有解耦Cross Attention的轻量级自适应模块来支持图像作为提示。
最后,InstantID提出 IdentityNet 通过额外的弱空间控制对参考面部图像中的复杂特征进行编码。
在 IdentityNet 中,生成过程完全由Face embedding引导,无需任何文本信息。 仅更新新添加的模块,而预先训练的文本到图像模型保持冻结以确保灵活性。无需额外的训练,用户可以生成任何风格的高保真ID保留图像。
InstantID的优势有如下三个方面:
1)可插拔性和兼容性:InstantID专注于训练轻量级适配器而不是UNet的完整参数,使InstantID的模块可插拔并与预训练模型兼容;
2)tuning-free:InstantID只需要一次前向传播进行推理,无需微调。 这一特性使得 InstantID 对于实际应用来说非常经济实用;
3)卓越的性能:只需一张参考图像,InstantID 即可实现最先进的结果,展现出高保真度和灵活性。
InstantID还支持多重参考,允许使用多张参考图像来生成一个新图像,从而增强生成图像的丰富性和多样性。
论文标题:InstantID: Zero-shot Identity-Preserving Generation in Seconds
论文地址:https://arxiv.org/abs/2401.07519
代码地址:https://github.com/InstantID/InstantID
项目地址:https://instantid.github.io
魔搭社区体验
魔搭社区体验地址:https://modelscope.cn/studios/instantx/InstantID
仅上传一张照片,选择风格,即可生成个性化写真
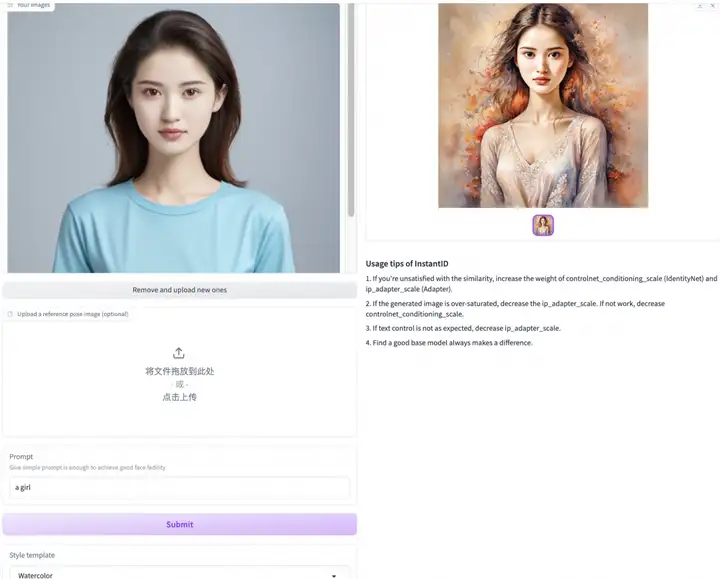
我们尝试给我们的AI模特变换了各种风格,效果非常好

AI模特

使用InstantID生成的各种风格写真
未来可见InstantID在电商广告,AI头像,虚拟试衣等场景上有广泛的应用潜力。
模型下载和推理
模型链接:
https://modelscope.cn/models/instantx/InstantID
模型下载代码:
from modelscope.hub.file_download import model_file_download
model_config=model_file_download(model_id="InstantX/InstantID", file_path="ControlNetModel/config.json", cache_dir="./checkpoints")
model_control=model_file_download(model_id="InstantX/InstantID", file_path="ControlNetModel/diffusion_pytorch_model.safetensors", cache_dir="./checkpoints")
model_ip=model_file_download(model_id="InstantX/InstantID", file_path="ip-adapter.bin", cache_dir="./checkpoints")
本地启动web-ui:
!git clone https://www.modelscope.cn/studios/instantx/InstantID.git
%cd InstantID
!pip install -r requirements.txt
!pip install gradio
!python app.py
模型推理代码:
# !pip install opencv-python transformers accelerate insightface
!git clone https://www.modelscope.cn/studios/instantx/InstantID.git
%cd InstantID
import diffusers
from diffusers.utils import load_image
from diffusers.models import ControlNetModel
from modelscope import snapshot_download
import cv2
import torch
import numpy as np
from PIL import Image
from insightface.app import FaceAnalysis
from pipeline_stable_diffusion_xl_instantid import StableDiffusionXLInstantIDPipeline, draw_kps
# prepare 'antelopev2' under ./models
app = FaceAnalysis(name='antelopev2', root='./', providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640))
# prepare models under ./checkpoints
face_adapter = f'../checkpoints/InstantX/InstantID/ip-adapter.bin'
controlnet_path = f'../checkpoints/InstantX/InstantID/ControlNetModel/'
# load IdentityNet
controlnet = ControlNetModel.from_pretrained(controlnet_path, torch_dtype=torch.float16)
sd_path = snapshot_download("AI-ModelScope/stable-diffusion-xl-base-1.0")
pipe = StableDiffusionXLInstantIDPipeline.from_pretrained(sd_path, controlnet=controlnet, torch_dtype=torch.float16)
pipe.cuda()
# load adapter
pipe.load_ip_adapter_instantid(face_adapter)
然后可以使用照片来生成不同的个人写真。
# load an image
face_image = load_image("your-example.jpg")
# prepare face emb
face_info = app.get(cv2.cvtColor(np.array(face_image), cv2.COLOR_RGB2BGR))
face_info = sorted(face_info, key=lambda x:(x['bbox'][2]-x['bbox'][0])*x['bbox'][3]-x['bbox'][1])[-1] # only use the maximum face
face_emb = face_info['embedding']
face_kps = draw_kps(face_image, face_info['kps'])
pipe.set_ip_adapter_scale(0.8)
prompt = "analog film photo of a man. faded film, desaturated, 35mm photo, grainy, vignette, vintage, Kodachrome, Lomography, stained, highly detailed, found footage, masterpiece, best quality"
negative_prompt = "(lowres, low quality, worst quality:1.2), (text:1.2), watermark, painting, drawing, illustration, glitch, deformed, mutated, cross-eyed, ugly, disfigured (lowres, low quality, worst quality:1.2), (text:1.2), watermark, painting, drawing, illustration, glitch,deformed, mutated, cross-eyed, ugly, disfigured"
# generate image
image = pipe(prompt, image_embeds=face_emb, image=face_kps, controlnet_conditioning_scale=0.8).images[0]
点击直达创空间体验

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献660条内容
已为社区贡献660条内容

所有评论(0)