Embedding模型背景介绍
文本表示是自然语言处理(NLP)领域的核心问题, 其在很多NLP、信息检索的下游任务中发挥着非常重要的作用。常见的文本向量化方法有以下几种:
- 词袋模型(Bag-of-Words): 将文本中的每个词都看作一个独立的特征,构造一个词汇表,统计每个词在文本中出现的频次或者计算TF-IDF等指标。最终得到一个向量形式的文本表示,向量的每个维度对应一个词,值表示该词在文本中的重要性或者频次。
- Word2Vec:随着机器学习和深度学习的发展,有方法尝试通过神经网络模型,将词语表示为固定长度的向量。Word2Vec模型可以学习到词语之间的语义关系,将语义相似的词语映射到相近的向量空间中。
- 基于预训练模型的文本表示: Word2Vec这样的静态向量虽然有一定的语义表示能力,但是不能直接建模上下文之间的关系。相比之下,以BERT为代表的预训练语言模型能够更好地捕捉上下文信息。通过将预训练语言模型与大规模标注数据训练结合训练文本表示模型,可以极大地提升下游任务的效果。

图1 Embedding Model表示转换示意图
文本表示模型的典型应用场景包括:
- 检索(Information Retrieval):在信息检索中,文本表示模型可以将查询转化为向量表示,并与向量数据库中的文档进行相似度计算,从而找到与查询最相关的文档。
- 聚类(Clustering):文本表示模型可以将文本转化为向量表示,并通过计算文本之间的相似度将相似的文本聚类在一起。聚类可以帮助发现文本集合中的隐藏模式和主题,从而实现文本归类、主题提取等应用。
- 分类(Classification):文本表示模型可以将文本和标签转化为向量表示,通过计算文本和标签的相似性来执行分类任务。这可以用于情感分析、文本分类等应用。
RAG范式下的Embedding Model
大模型的出现激发出大量类似Langchain的开发工具,同步引爆了Embedding模型和向量数据库的热潮。大模型驱动的RAG(Retrieval-Augmented Generation)开发范式在问答系统、文本生成、摘要生成等任务中取得了显著的效果提升。RAG将大型语言模型与检索模型相结合。RAG首先利用检索模型从大量的文档中检索出相关的信息,然后将这些信息作为上下文输入到语言生成模型中,生成更加准确和有逻辑性的文本。
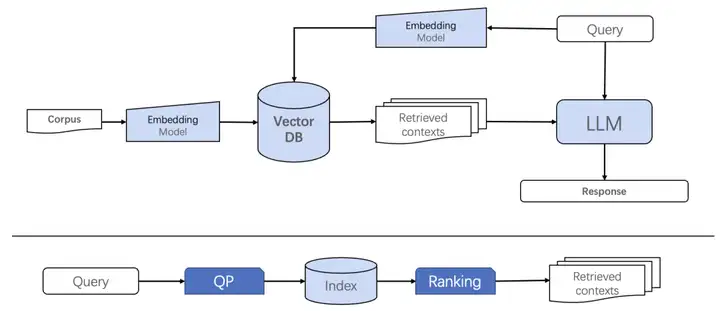
图2 RAG流程 VS 搜索排序流程
现有的RAG系统在获取相关结果方面严重依赖于Embedding模型的召回准确性。然而,在传统的检索系统中,用户的查询会经过更精细的查询理解、召回和排序流程,最终给出与查询相关性最高的结果。在传统的检索流程中,Embedding模型只是作为召回的一部分。现有的RAG模型范式在依赖Embedidng模型进行召回和深度排序的同时,对Embedding模型在除召回能力之外的召准能力提出了更高的要求。此外,在典型的问答场景中,复杂的查询也给嵌入模型带来了新的挑战,包括领域泛化性、长短文本统一处理、复杂query和doc理解等方面。这些问题在图3中展示了部分典型示例。

图3 RAG范式向量召回典型问题
GTE统一文本表示
基于预训练的文本表示模型的性能主要由三个方面的影响: 预训练底座模型、训练数据的质量和丰富度、训练策略。GTE系列模型采用双塔结构(Dual Encoder)训练。如下图所示。在Dual Encoder框架中, Query 和 Document文本通过预训练语言模型编码后, 通常采用预训练语言模型[CLS]位置的向量作为最终的文本向量表示。基于标注数据的标签, 通过计算query-document之间的cosine距离度量两者之间的相关性。
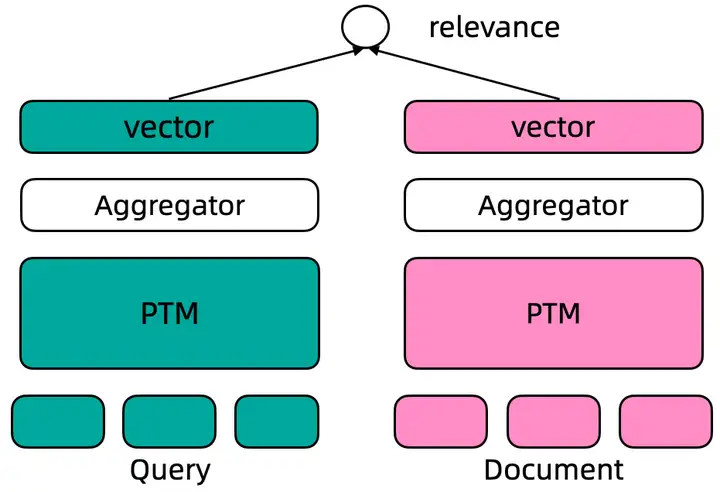
图4 双塔模型结构
GTE模型采用多阶段的训练策略:
- 表示特性预训练: 类似BERT的预训练语言模型采用MLM的训练目标跟文本表示的目标是有差距的,文本表示模型一般采用[CLS]位置的向量表示作为输入的最终表示。表示特性预训练主要通过MAE的训练方法增强[CLS]的表示能力。
- 弱监督对比学习预训练: 充分利用大规模弱监督预训练数据、提升模型的文本表示能力和领域泛化能力。
- 监督训练: 利用高质量精标文本对数据以及挖掘的难负样本数据训练模型,确保训练模型的稳定性和鲁棒性。为了保障训练的模型能满足不同场景的向量检索需求,尤其是RAG场景下的复杂query的召回需求。在监督训练过程中,训练数据除了能收集到的高质量标注数据以外,可以使用大型模型加上提示(prompts)的方式生成更大规模的数据满足不同场景的需求。

图5 多阶段训练示意图
GTE文本向量模型上线魔搭社区
GTE模型目前提供的中、英文双语不同Size的模型,魔搭社区开源链接:
https://www.modelscope.cn/models/damo/nlp_gte_sentence-embedding_chinese-base/summary
https://www.modelscope.cn/models/damo/nlp_gte_sentence-embedding_english-base/summary
https://www.modelscope.cn/models/damo/nlp_gte_sentence-embedding_chinese-small/summary
https://www.modelscope.cn/models/damo/nlp_gte_sentence-embedding_english-small/summary
https://www.modelscope.cn/models/damo/nlp_gte_sentence-embedding_chinese-large/summary
https://www.modelscope.cn/models/damo/nlp_gte_sentence-embedding_english-large/summary
以GTE文本向量-中文-通用领域-base模型为例,提供魔搭社区推理训练教程:
使用方式:
- 直接推理, 对给定文本计算其对应的文本向量表示,向量维度768
使用范围:
- 本模型可以使用在通用领域的文本向量表示及其下游应用场景, 包括双句文本相似度计算、query&多doc候选的相似度排序
模型推理
在ModelScope框架上,提供输入文本(默认最长文本长度为128,可以通过修改参数指定文本长度),即可以通过简单的Pipeline调用来使用GTE文本向量表示模型。ModelScope封装了统一的接口对外提供单句向量表示、双句文本相似度、多候选相似度计算功能
代码示例
from modelscope.models import Model
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
model_id = "damo/nlp_gte_sentence-embedding_chinese-base"
pipeline_se = pipeline(Tasks.sentence_embedding,
model=model_id,
sequence_length=512
) # sequence_length 代表最大文本长度,默认值为128
# 当输入包含“soure_sentence”与“sentences_to_compare”时,会输出source_sentence中首个句子与sentences_to_compare中每个句子的向量表示,以及source_sentence中首个句子与sentences_to_compare中每个句子的相似度。
inputs = {
"source_sentence": ["吃完海鲜可以喝牛奶吗?"],
"sentences_to_compare": [
"不可以,早晨喝牛奶不科学",
"吃了海鲜后是不能再喝牛奶的,因为牛奶中含得有维生素C,如果海鲜喝牛奶一起服用会对人体造成一定的伤害",
"吃海鲜是不能同时喝牛奶吃水果,这个至少间隔6小时以上才可以。",
"吃海鲜是不可以吃柠檬的因为其中的维生素C会和海鲜中的矿物质形成砷"
]
}
result = pipeline_se(input=inputs)
print (result)
'''
{'text_embedding': array([[ 1.6415151e-04, 2.2334497e-02, -2.4202393e-02, ...,
2.7710509e-02, 2.5980933e-02, -3.1285528e-02],
[-9.9107623e-03, 1.3627578e-03, -2.1072682e-02, ...,
2.6786461e-02, 3.5029035e-03, -1.5877936e-02],
[ 1.9877627e-03, 2.2191243e-02, -2.7656069e-02, ...,
2.2540951e-02, 2.1780970e-02, -3.0861111e-02],
[ 3.8688166e-05, 1.3409532e-02, -2.9691193e-02, ...,
2.9900728e-02, 2.1570563e-02, -2.0719109e-02],
[ 1.4484422e-03, 8.5943500e-03, -1.6661938e-02, ...,
2.0832840e-02, 2.3828523e-02, -1.1581291e-02]], dtype=float32), 'scores': [0.8859604597091675, 0.9830712080001831, 0.966042160987854, 0.891857922077179]}
'''
# 当输入仅含有soure_sentence时,会输出source_sentence中每个句子的向量表示。
inputs2 = {
"source_sentence": [
"不可以,早晨喝牛奶不科学",
"吃了海鲜后是不能再喝牛奶的,因为牛奶中含得有维生素C,如果海鲜喝牛奶一起服用会对人体造成一定的伤害",
"吃海鲜是不能同时喝牛奶吃水果,这个至少间隔6小时以上才可以。",
"吃海鲜是不可以吃柠檬的因为其中的维生素C会和海鲜中的矿物质形成砷"
]
}
result = pipeline_se(input=inputs2)
print (result)
'''
{'text_embedding': array([[-9.9107623e-03, 1.3627578e-03, -2.1072682e-02, ...,
2.6786461e-02, 3.5029035e-03, -1.5877936e-02],
[ 1.9877627e-03, 2.2191243e-02, -2.7656069e-02, ...,
2.2540951e-02, 2.1780970e-02, -3.0861111e-02],
[ 3.8688166e-05, 1.3409532e-02, -2.9691193e-02, ...,
2.9900728e-02, 2.1570563e-02, -2.0719109e-02],
[ 1.4484422e-03, 8.5943500e-03, -1.6661938e-02, ...,
2.0832840e-02, 2.3828523e-02, -1.1581291e-02]], dtype=float32), 'scores': []}
'''
默认向量维度768, scores中的score计算两个向量之间的内积距离得到
模型训练
本模型基于Dureader Retrieval中文数据集(通用领域)上训练,在垂类领域英文文本上的文本效果会有降低,用户可以基于本模型做微调
# 需在GPU环境运行
# 加载数据集过程可能由于网络原因失败,请尝试重新运行代码
from modelscope.metainfo import Trainers
from modelscope.msdatasets import MsDataset
from modelscope.trainers import build_trainer
import tempfile
import os
tmp_dir = tempfile.TemporaryDirectory().name
if not os.path.exists(tmp_dir):
os.makedirs(tmp_dir)
# load dataset
ds = MsDataset.load('dureader-retrieval-ranking', 'zyznull')
train_ds = ds['train'].to_hf_dataset()
dev_ds = ds['dev'].to_hf_dataset()
model_id = 'damo/nlp_gte_sentence-embedding_chinese-base'
def cfg_modify_fn(cfg):
cfg.task = 'sentence-embedding'
cfg['preprocessor'] = {'type': 'sentence-embedding','max_length': 256}
cfg['dataset'] = {
'train': {
'type': 'bert',
'query_sequence': 'query',
'pos_sequence': 'positive_passages',
'neg_sequence': 'negative_passages',
'text_fileds': ['text'],
'qid_field': 'query_id'
},
'val': {
'type': 'bert',
'query_sequence': 'query',
'pos_sequence': 'positive_passages',
'neg_sequence': 'negative_passages',
'text_fileds': ['text'],
'qid_field': 'query_id'
},
}
cfg['train']['neg_samples'] = 4
cfg['evaluation']['dataloader']['batch_size_per_gpu'] = 30
cfg.train.max_epochs = 1
cfg.train.train_batch_size = 4
return cfg
kwargs = dict(
model=model_id,
train_dataset=train_ds,
work_dir=tmp_dir,
eval_dataset=dev_ds,
cfg_modify_fn=cfg_modify_fn)
trainer = build_trainer(name=Trainers.nlp_sentence_embedding_trainer, default_args=kwargs)
trainer.train()
模型效果评估
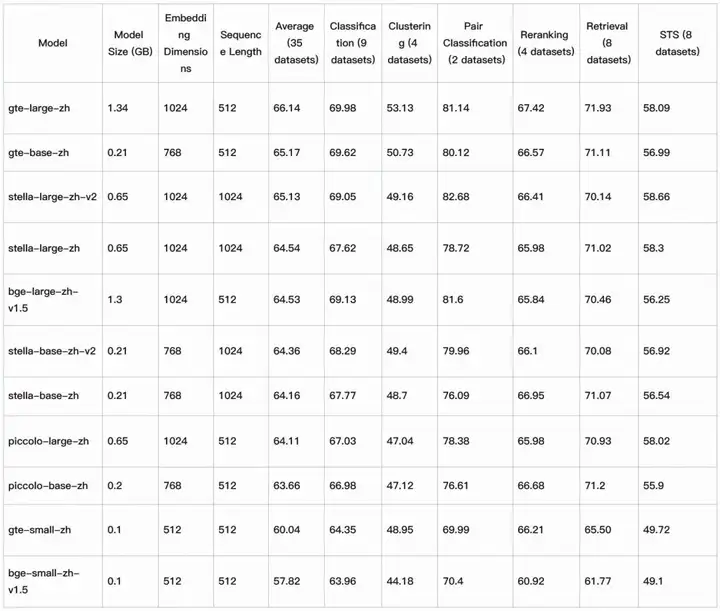
中文多任务向量评测榜单C-MTEB结果如下:
欢迎各位开发者小伙伴体验使用!
ModelScope-RAG技术交流群

算法专家直播回放
AI模型社 | GTE:大模型驱动的统一文本表示
链接:https://weixin.qq.com/sph/ANzvtd

PPT资料获取
关注魔搭微信公众号,后台发送“GTE”获取更多相关学习资料
点击直达模型开源链接:
https://www.modelscope.cn/models/damo/nlp_gte_sentence-embedding_chinese-base/summary










 已为社区贡献644条内容
已为社区贡献644条内容

所有评论(0)