
单卡A100可运行,如果自己的显卡显存不够,可以考虑使用多张3090显卡,或者对模型进行量化。
元象开源650亿参数高性能大模型,无条件免费商用!魔搭最佳实践来了!
·
导读
为推动国产大模型开源生态繁荣与产业应用快速发展,元象XVERSE公司宣布 开源650亿参数高性能通用大模型XVERSE-65B,无条件免费商用,业界尚属首次。 13B模型全面升级,提高“小”模型能力上限。这将让海量中小企业、研究者和AI开发者 更早一步实现“大模型自由” ,根据其算力、资源限制和具体任务需求,自由使用、修改或蒸馏元象大模型,推动研究与应用的突破创新。
XVERSE-65B底座模型在2.6万亿Tokens的高质量数据上从头训练,上下文窗口扩展至16K,支持中、英、俄、法等40多种语言。XVERSE-65B Chat版也将在近期发布。
元象坚持“高性能”定位,显著提升了65B三方面能力:
1、理解、生成、推理和记忆等基础能力,到 模型的多样性、创造性和精度表现,从优异到强大;2、扩展了工具调用、代码解释、反思修正等能力,为构建智能体(AI Agent)奠定技术基础,提高模型实用性;
3、显著缓解7B、13B中常见且可能很严重的幻觉问题,减少大模型“胡说八道”,提高准确性和专业度。
元象XVERSE-65B模型目前在魔搭社区开源,社区已推出模型推理、微调最佳实践教程,欢迎开发者们来体验!
环境配置与安装
-
python 3.8及以上版本
-
pytorch 1.12及以上版本,推荐2.0及以上版本
-
建议使用CUDA 11.4及以上
使用步骤
本文主要演示的模型为XVERSE-65B模型,在PAI-DSW使用(双卡A100)
模型链接和下载
XVERSE-65B模型现已在ModelScope社区开源,模型链接:
https://modelscope.cn/models/xverse/XVERSE-65B/summary
社区支持直接下载模型的repo:
from modelscope import snapshot_download
model_dir1 = snapshot_download("xverse/XVERSE-65B", revision = "master")
模型推理
推理代码:
import torch
from modelscope import AutoTokenizer, AutoModelForCausalLM, snapshot_download
model_dir = snapshot_download('xverse/XVERSE-65B', revision = 'v1.0.0')
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForCausalLM.from_pretrained(model_dir, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto')
model = model.eval()
inputs = tokenizer('北京的景点:故宫、天坛、万里长城等。\n深圳的景点:', return_tensors='pt').input_ids
inputs = inputs.cuda()
generated_ids = model.generate(inputs, max_new_tokens=64, eos_token_id=tokenizer.eos_token_id, repetition_penalty=1.1)
print(tokenizer.batch_decode(generated_ids, skip_special_tokens=True))
资源消耗:
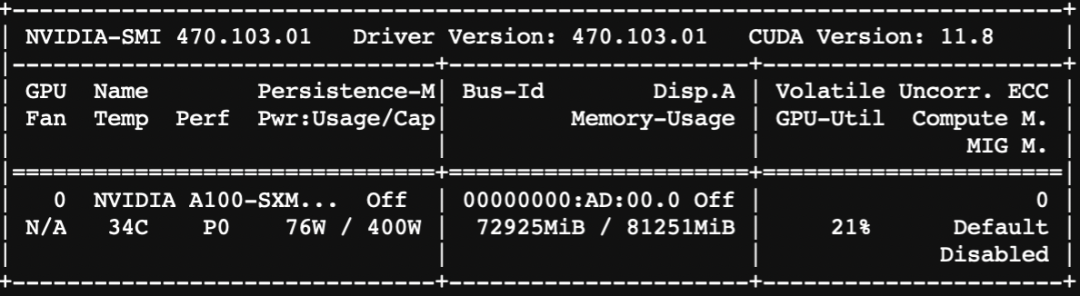
XVERSE-65B微调和微调后推理
微调代码开源地址: https://github.com/modelscope/swift/tree/main/examples/pytorch/llm
SWFIT是魔搭社区官方提供的LLM&AIGC模型微调推理框架,首先从github上将SWIFT clone下来:
# 设置pip全局镜像和安装相关的python包
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
git clone https://github.com/modelscope/swift.git
cd swift
pip install .[llm]
# 下面的脚本需要在此目录下执行
cd examples/pytorch/llm
# 如果你想要使用deepspeed.
pip install deepspeed -U
# 如果你想要使用基于bnb的qlora训练.
pip install bitsandbytes -U
模型微调脚本 (lora+device_map),在4bit量化情况下,LoRA训练该模型需要大约45G显存左右,考虑到家用显卡很难有这么大的显存,因此我们提供了双卡3090可运行的tensor并行训练脚本:
# Experimental environment: 2 * A100
# 2 * 23GB GPU memory
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0,1 \
python llm_sft.py \
--model_id_or_path xverse/XVERSE-65B \
--model_revision v1.0.0 \
--sft_type lora \
--tuner_backend swift \
--template_type default-generation \
--dtype bf16 \
--output_dir output \
--dataset dureader-robust-zh \
--train_dataset_sample -1 \
--num_train_epochs 1 \
--max_length 2048 \
--check_dataset_strategy warning \
--quantization_bit 4 \
--bnb_4bit_comp_dtype bf16 \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.05 \
--lora_target_modules ALL \
--gradient_checkpointing true \
--batch_size 1 \
--weight_decay 0.01 \
--learning_rate 1e-4 \
--gradient_accumulation_steps 16 \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10 \
模型微调后的推理脚本,请将下面--ckpt_dir的值改为--output_dir中实际存储的模型weights目录。
# Experimental environment: A100
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0 \
python llm_infer.py \
--ckpt_dir "output/xverse-13b/vx_xxx/checkpoint-xxx" \
--load_args_from_ckpt_dir true \
--eval_human false \
--max_length 2048 \
--max_new_tokens 2048 \
--temperature 0.9 \
--top_k 20 \
--top_p 0.9 \
--repetition_penalty 1.05 \
--do_sample true \
--merge_lora_and_save false \
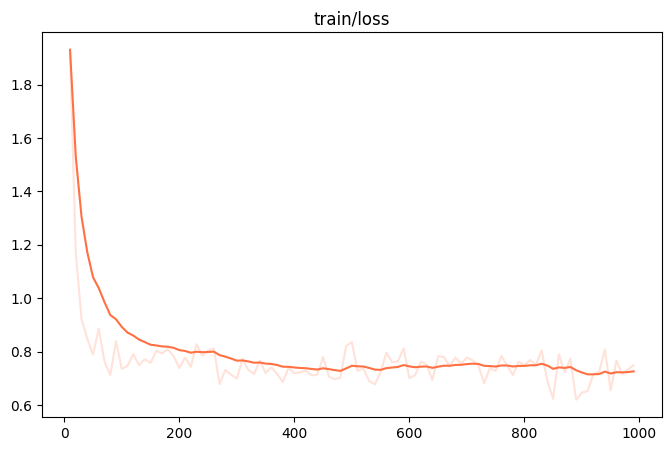
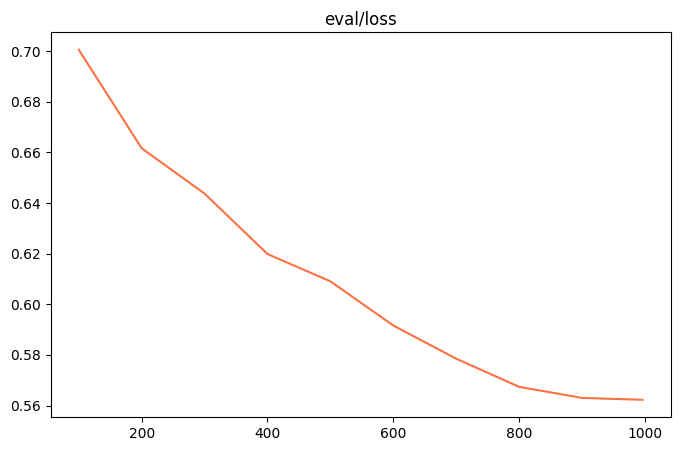
微调的可视化结果
训练损失:
评估损失
训练后生成样例
[PROMPT]Task: Question Generation
Context: 下载速度达到72mbp/s速度相当快。相当于500兆带宽。在网速计算中, b=bit,B=byte 8×b=1×B 意思是 8个小写的b 才是一个大写B。4M理论下载速度:4M就是4Mb/s 理论下载速度公式:4×1024÷8=512KB /s 请注意按公式单位已经变为 KB/s 依此类推: 2M理论下载速度:2×1024÷8=256KB /s 8M理论下载速度:8×1024÷8=1024KB /s =1MB/s 10M理论下载速度:10×1024÷8=1280KB /s =2M理论下载速度+8M理论下载速度 50M理论下载速度:50×1024÷8=6400KB /s 1Gb理论下载速度:1024×1024÷8=128MB /s 公式:几兆带宽×1024÷8=()KB/s。
Answer: 相当于500兆带宽
Question: [OUTPUT]72mbps什么速度<|endoftext|>
[LABELS]72mbps是多少网速
-------------------------------------------------------------------------------
[PROMPT]Task: Question Generation
Context: 下载速度达到72mbp/s速度相当快。相当于500兆带宽。在网速计算中, b=bit,B=byte 8×b=1×B 意思是 8个小写的b 才是一个大写B。4M理论下载速度:4M就是4Mb/s 理论下载速度公式:4×1024÷8=512KB /s 请注意按公式单位已经变为 KB/s 依此类推: 2M理论下载速度:2×1024÷8=256KB /s 8M理论下载速度:8×1024÷8=1024KB /s =1MB/s 10M理论下载速度:10×1024÷8=1280KB /s =2M理论下载速度+8M理论下载速度 50M理论下载速度:50×1024÷8=6400KB /s 1Gb理论下载速度:1024×1024÷8=128MB /s 公式:几兆带宽×1024÷8=()KB/s。
Answer: 500兆带宽
Question: [OUTPUT]72mbps是多少兆<|endoftext|>
[LABELS]72mbps是多少网速
-------------------------------------------------------------------------------
[PROMPT]Task: Question Generation
Context: 我个人感觉是吕颂贤版,剧情和原著差别不大,虽然TVB演员颜值和风光没有大陆的好。但是香港特区人口和地域的限制,只能注重在演员的演技方面发挥很出色,楼主看过大陆排《笑傲江湖》吧!在台词上表现的很生硬没有香港的注重神色配台词,比如杜燕歌把吕颂贤表情和性格几乎和原著差别不大。武打几乎沿用徐克和程小东动作的风格很注重实际技巧,没有大陆版的在武打场面依靠电脑特效表现的太夸张了。李亚鹏版的武打动作和导演还是香港的元彬,大陆毕竟还是在武侠剧起步的比较晚,主要是还是靠明星大腕压阵而香港却是恰恰相反。
Answer: 吕颂贤版
Question: [OUTPUT]哪一版的笑傲江湖好看<|endoftext|>
[LABELS]笑傲江湖哪个版本好看
-------------------------------------------------------------------------------
资源消耗:
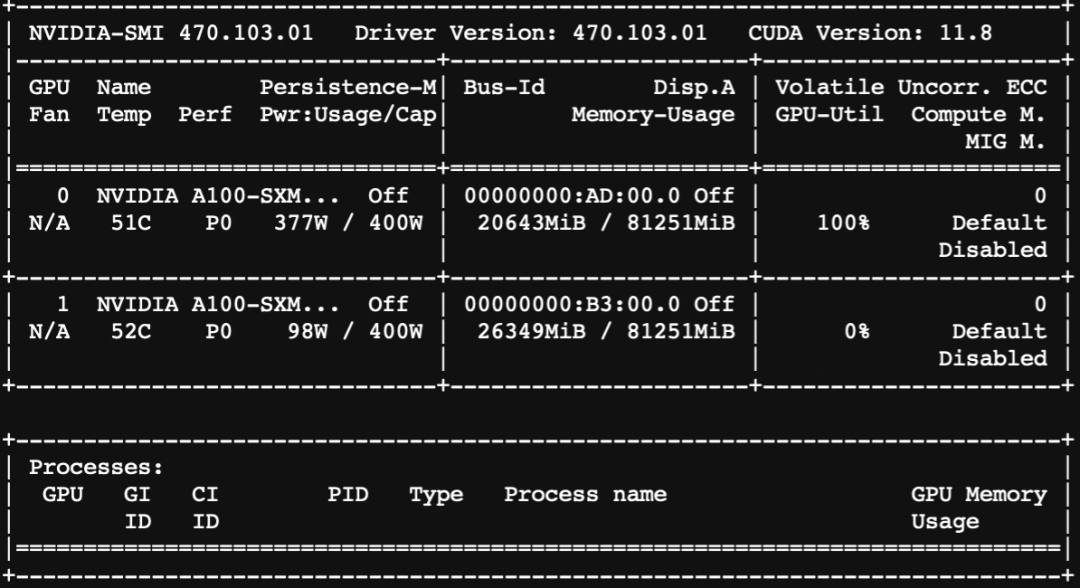
点击直达模型卡片
https://modelscope.cn/models/xverse/XVERSE-65B/summary

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献662条内容
已为社区贡献662条内容

所有评论(0)