
通过手机环拍构建出来的物体模型及贴图很完整自然,该服务当前已魔搭创空间上线并开放免费使用,操作简单,快来跟着小编一起试试吧!
社区供稿 | 3D物生成,帮你轻松造万物
·
最近魔搭上线了一项新能力——用手机环拍物体1min视频即可生成3D模型,该过程完全自动化且一小时左右即可构建完成!它不仅解救了传统行业手工建模的设计师们,也让芸芸众生的我们变身上古女娲,想在数字世界里生成什么,拿起手机即可生成,让我们来看看下面的效果:
1、注册并登陆魔搭平台
进入ModelScope官网:https://modelscope.cn/home,点击右上角“登陆/注册”,进入注册页面,并填写注册所需信息完成注册。建议用手机号注册,速度最快。
2、访问3D物生成的创空间页面
账号登陆后进入创空间页面 https://modelscope.cn/studios/Damo_XR_Lab/3D_AIGC/summary
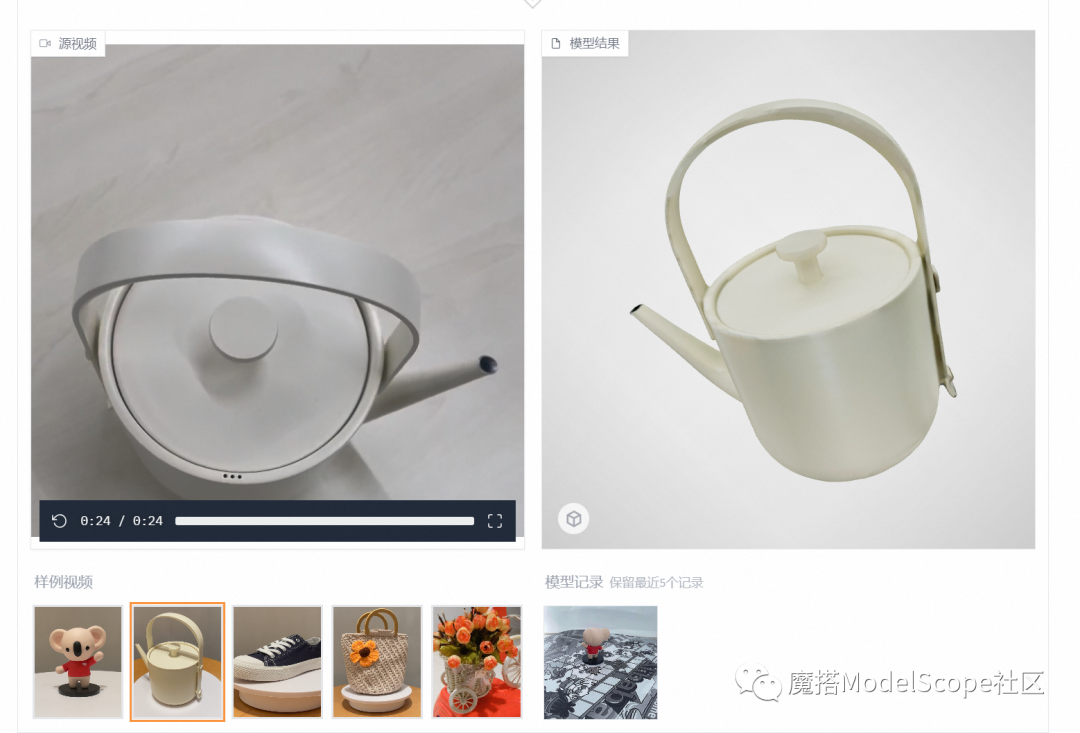
3、(简易体验版)选择页面下方的示例输入,即可在快速生成模型结果
4、(充分体验版)制作你元宇宙世界里的万物
仅需三步即可完成:
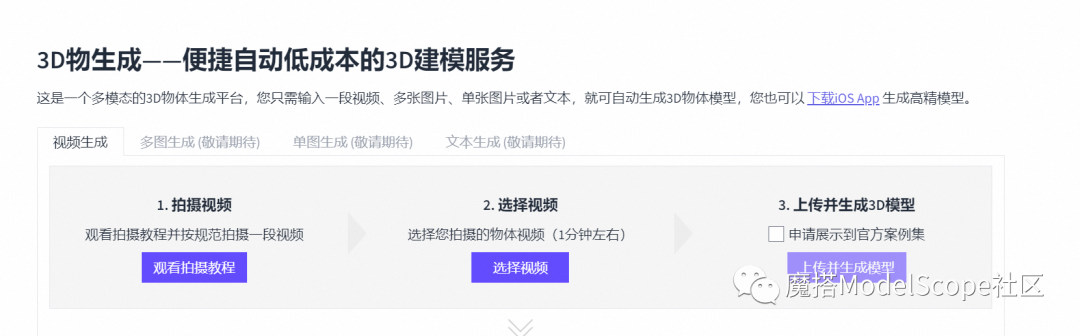
4.1 根据拍摄指引拍摄物体视频
https://live.csdn.net/v/324735
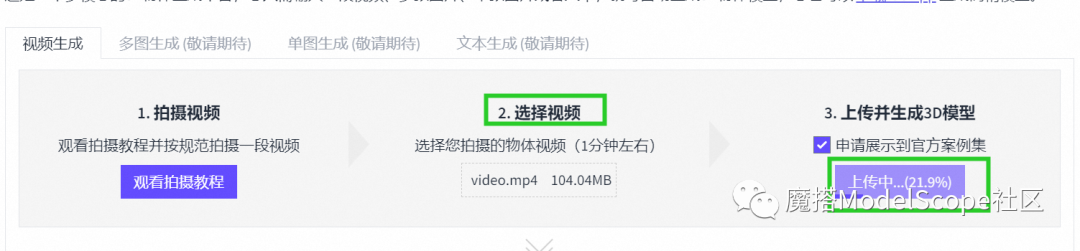
4.2 选择并上传您的视频
点击上图步骤中“选择视频”按钮,选择拍摄完成的视频进行上传。
温馨提示:由于视频文件较大,上传需一些时间,建议上传完成前保持页面,上传完成后再关闭。
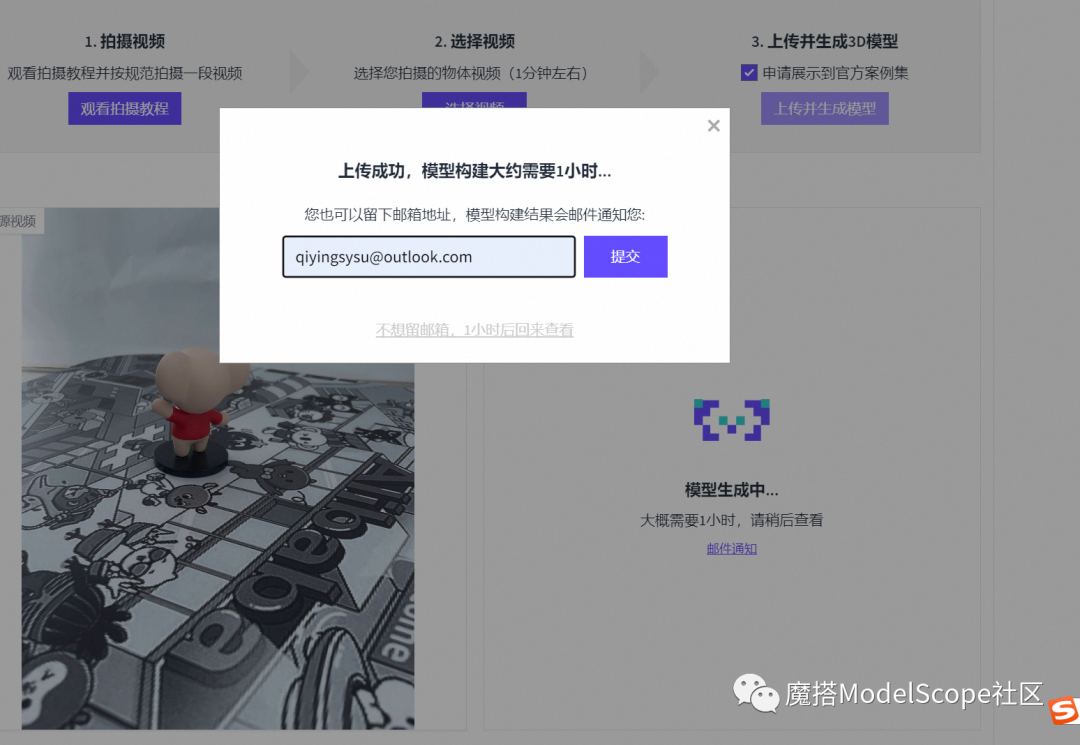
4.3 等待构建完成即可查看您的3D模型结果
上传完成后再视频框中即可出现您的原视频结果,可输入您的邮箱地址,我们将会在构建完成后进行邮件通知。
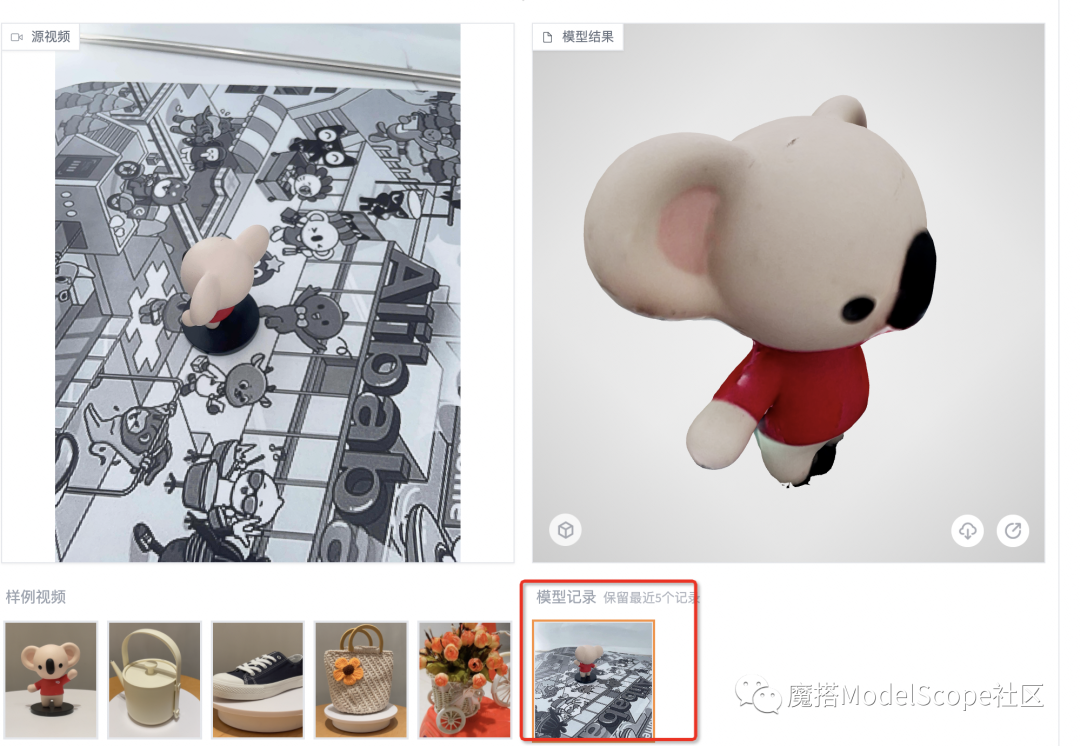
除了视频构建3D物体模型以外,未来我们还会上线图片生成以及文本生成,让用户可以尽情发挥想象力去创造未来3D世界!
5、(充分体验版)无限制构建你的3D物模型
如果你想保存所有扫描后的3D物体模型,可下载app进行充分体验更高精度的建模:

XR实验室长期探索3D内容生成,在此分享我们结合大模型的能力推进3D物生成的技术链路及思考,未来相应的生成模型都会通过ModelScope平台开放。
1、3D物生成框架:
用户输入一段视频、图片或者文本,可以生成相应的3D内容。
具体来说,我们可提供的能力大致分为:
-
视频转3D:通过输入一段拍摄物体的几十秒视频,AI在一个小时内生成具有纹理的3D模型
-
图像转3D:通过输入单张或者几张2D图像,AI自动将其转换为3D模型
-
文本转3D:通过文本输入,AI自动生成3D模型
-
AI 3D纹理:给定几何模型和文本提示,AI自动为模型进行纹理贴图
首先来分享下视频转3D的技术实现链路:
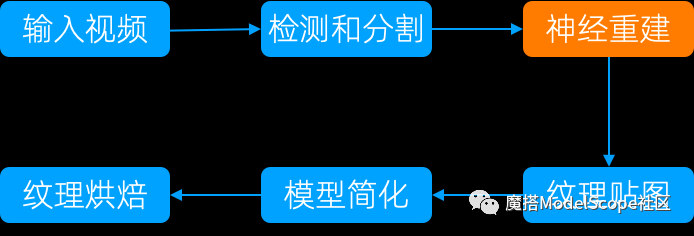
整个方案主要包含五大模块,分别是:检测和分割、神经重建、纹理贴图、模型简化、纹理烘焙。
下面重点介绍检测和分割、隐式神经重建两大模块。
-
检测和分割
目标是在视频帧中将物体从背景中分割出来,便于后续的处理。我们采用了基于图像分割大模型Segment Anything Model(SAM)[1]的视频跟踪方案。该方案要求在第一帧上能将物体自动分割出来,为此我们采用基于显著性目标检测的模块,它能够自动地检测出物体大致的Mask。借助SAM模型提供的:根据输入的提示比如鼠标选点、画框来获取分割区域的能力,我们将检测得到的Mask转换成选点,再经过SAM模型处理就得到物体精细的Mask。
-
神经重建
为了能够根据输入的多视角图片以及相应的相机位姿,重建出物体的几何,我们采用了神经隐式表面重建的方案。
神经重建的方案比如NeuS[2]、VolSDF[3],通过结合基于可微分的体渲染技术和符号距离场,可以高保真地恢复出物体几何,但是耗时比较长,通常一个物体的几何重建长达十小时。为了提高重建的效率和精度,我们采用自研的HIVE[4]方案,参考Instant-NGP[5],Plenoxels[6]等加速新视角合成的NeRF[7]方案,设计层次结构的体素方案来加速收敛和提升精度, 目前几何重建的时间最快能压缩到二十分钟。
除了视频生成方向,我们也在研发图像/文本转3D、AI 3D纹理技术。
-
图像/文本转3D的技术
目前大致有两类生成的方案,第一类是采用优化迭代的方案,得益于多模态领域和文生图模型的发展,通过文本或者图片的输入,可以直接输出高质量的3D模型,但是耗时较长。另外一类方案,采用3D数据来训练3D Diffusion模型,只需要单次前向预测,可以快速得到结果,但是效果受限于3D数据量。我们正在针对两类方案做一些优化改进,一是设计更加合理的3D表征结构,可以输出高质量的模型,二是利用2D图像的Depth、Normal等信息,提供更多的约束。
-
AI 3D纹理的技术
给定几何,根据文本提示词,可以自动给模型贴上纹理。我们目前正在基于Stable Diffusion的能力,生成多视角更加一致的图片,同时加入融合优化的策略,进一步提升质量。
提示词:"a white audi Q5 car, plain background"
结果:


[1] SAM: Kirillov A, Mintun E, Ravi N, et al. Segment anything
[2] NeuS: Wang P, Liu L, Liu Y, et al. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction
[3] VolSDF: Yariv L, Gu J, Kasten Y, et al. Volume rendering of neural implicit surfaces
[4] HIVE: Gu X, Yuan W, et al. Hierarchical volume encoding for neural implicit surface reconstruction
[5] Instant-NGP: Müller T, Evans A, Schied C, et al. Instant neural graphics primitives with a multiresolution hash encoding
[6] Plenoxels: Fridovich-Keil S, Yu A, Tancik M, et al. Plenoxels: Radiance fields without neural networks
[7] NeRF: Mildenhall B, Srinivasan P P, Tancik M, et al. Nerf: Representing scenes as neural radiance fields for view synthesis
试用3D物生成服务:
https://modelscope.cn/studios/Damo_XR_Lab/3D_AIGC/summary

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 0
0- 0



 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)