
clone swift仓库并安装swift
通义千问开源第二波!多模态来啦!(内含魔搭最佳实践)
·
近期,通义千问大规模视觉语言模型Qwen-VL上线魔搭社区,Qwen-VL以通义千问70亿参数模型Qwen-7B为基座语言模型研发,支持图文输入,具备多模态信息理解能力。相比于此前的模型,Qwen-VL除了基本的图文识别、描述、问答、对话能力之外,还新增了像视觉定位、图像中文字理解等重要基础能力,Qwen-VL可以接受图像,多语言文本作为输入,并输出图像或者文本。
目前,通义千问开源了 Qwen-VL 系列的两个模型:
-
Qwen-VL: Qwen-VL 以 Qwen-7B 的预训练模型作为语言模型的初始化,并以ViT-bigG作为视觉编码器的初始化,中间加入单层随机初始化的 cross-attention,经过约1.5B的图文数据训练得到。最终图像输入分辨率为448。
-
Qwen-VL-Chat: 在 Qwen-VL 的基础上,通义千问团队使用对齐机制打造了基于大语言模型的视觉AI助手Qwen-VL-Chat,可以让开发者快速搭建具备多模态能力的对话应用。
Qwen-VL是如何工作的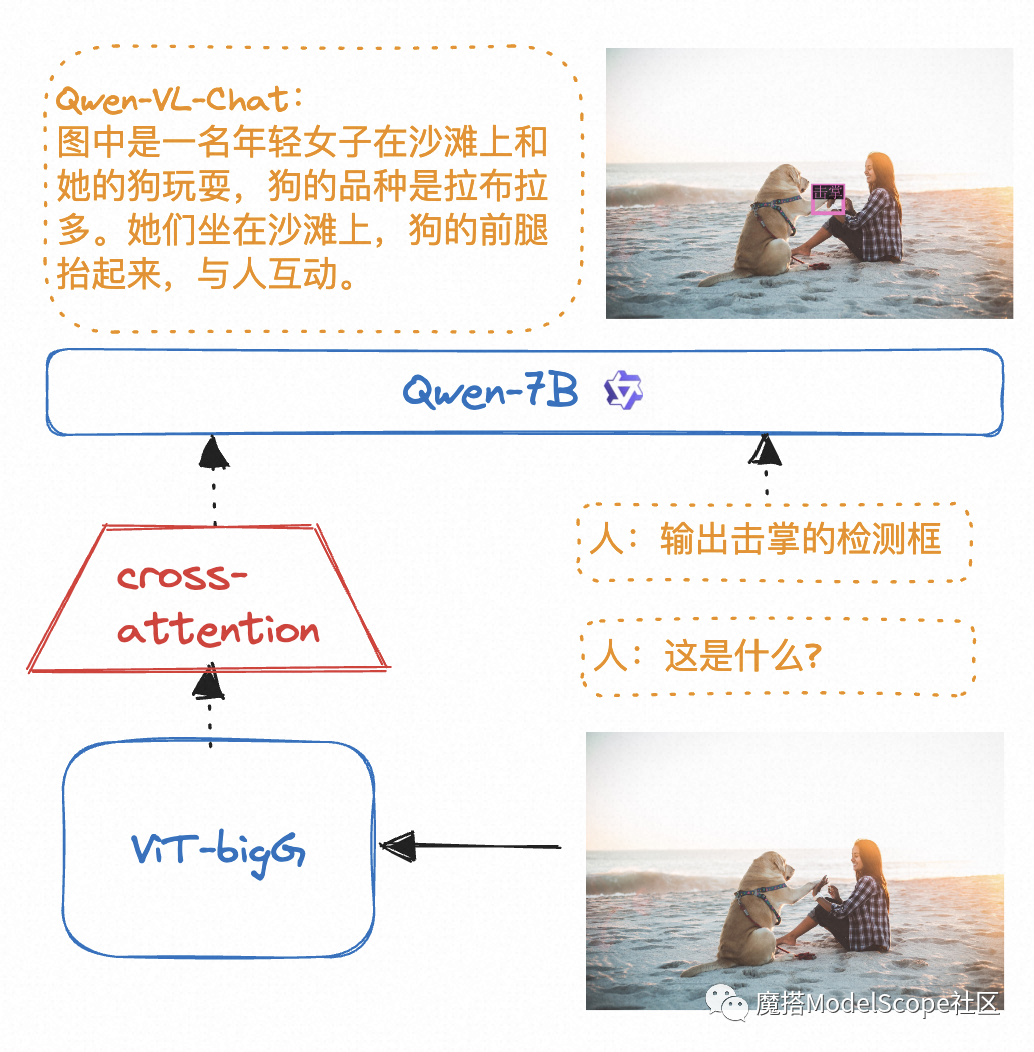
在上面图片中,输出“击掌”的检测框比输出人or狗的检测框更难,因为“击掌”是泛化出来的自然语言域的通用检测,训练集中没有。“人”和“狗”一般在检测训练集中大量存在,由此可见Qwen-VL较强的泛化能力。
-
python 3.8及以上版本
-
pytorch 1.12及以上版本,推荐2.0及以上版本
-
建议使用CUDA 11.4及以上(GPU用户需考虑此选项)
使用步骤
本文在ModelScope的Notebook的环境(这里以PAI-DSW为例)配置下运行 (可单卡运行, 显存要求24G)
服务器连接与环境准备
1、进入ModelScope首页:modelscope.cn,进入我的Notebook
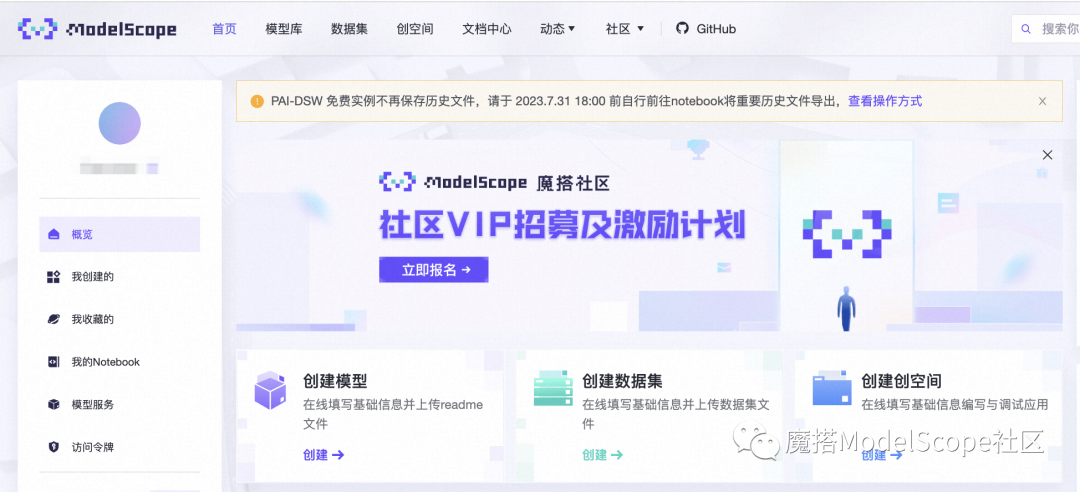
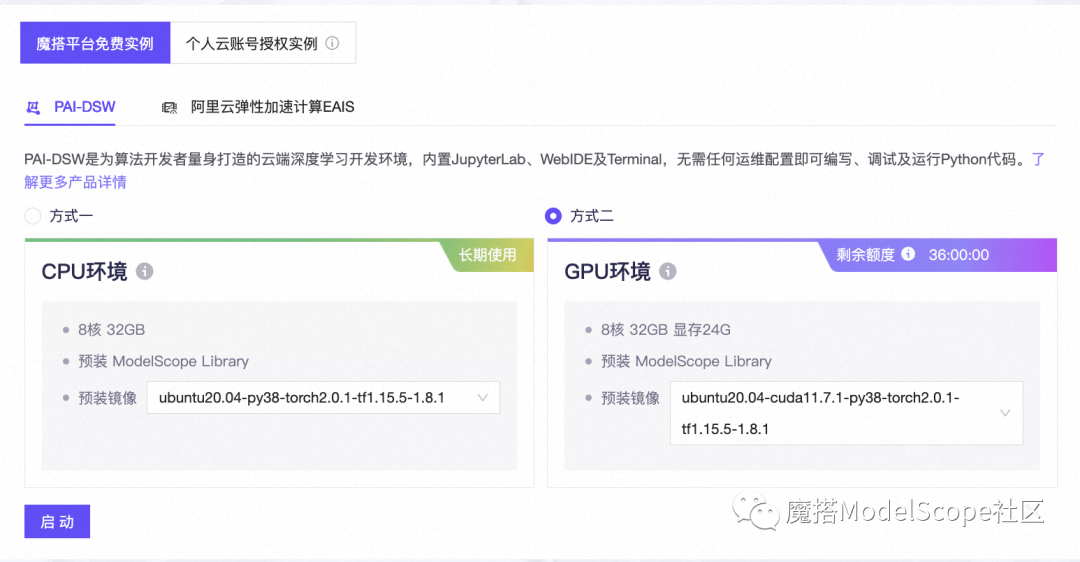
2、选择GPU环境,进入PAI-DSW在线开发环境
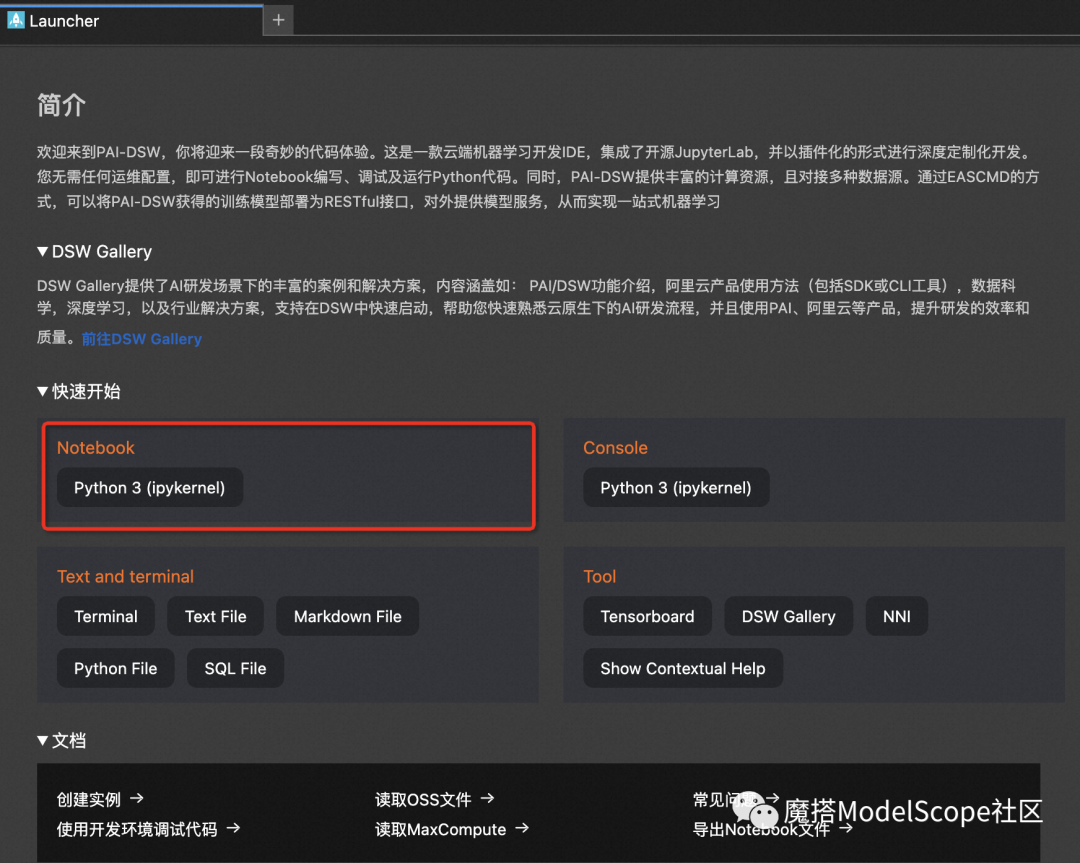
3、新建Notebook
模型零代码创空间体验地址:https://modelscope.cn/models/qwen/Qwen-VL-Chat
效果展示
视觉问答

文字理解

图片理解
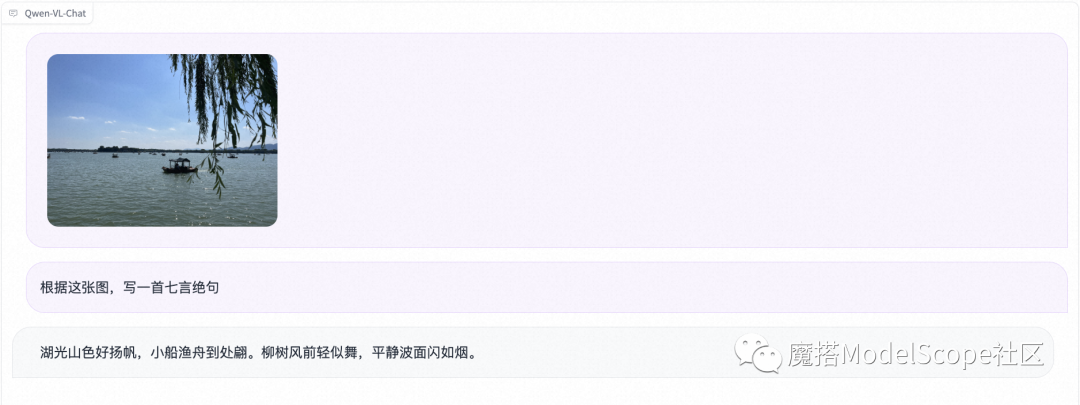
数学推理
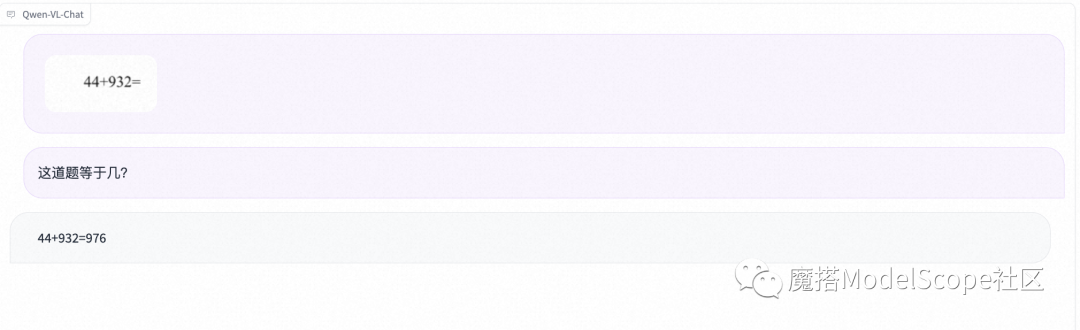
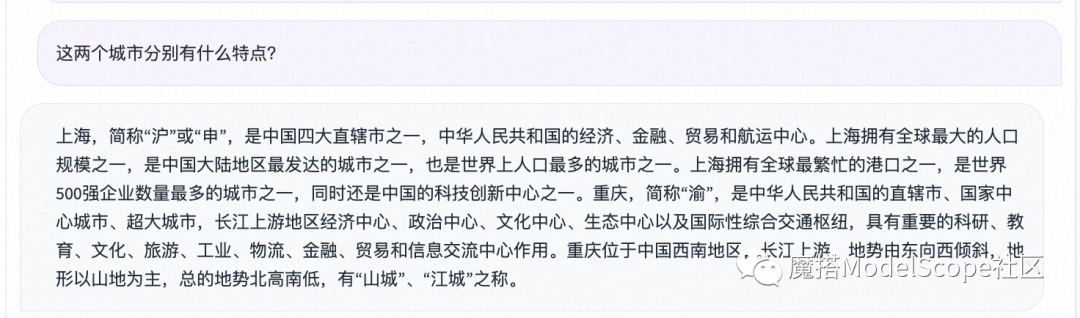
多图理解

Qwen系列模型现已在ModelScope社区开源,包括:
Qwen-VL-Chat
模型链接:https://modelscope.cn/models/qwen/Qwen-VL-Chat
Qwen-VL
模型链接:https://modelscope.cn/models/qwen/Qwen-VL
社区支持直接下载模型的repo:
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('qwen/Qwen-VL-Chat', 'v1.0.0')模型推理
安装依赖项和模型推理
#依赖项
!pip install modelscope -U
!pip install transformers accelerate tiktoken -U
!pip install einops transformers_stream_generator -U
!pip install "pillow==9.*" -U
!pip install torchvision
!pip install matplotlib -U
#推理代码:
from modelscope import (
snapshot_download, AutoModelForCausalLM, AutoTokenizer, GenerationConfig
)
import torch
model_id = 'qwen/Qwen-VL-Chat'
revision = 'v1.0.0'
model_dir = snapshot_download(model_id, revision=revision)
torch.manual_seed(1234)
# 请注意:分词器默认行为已更改为默认关闭特殊token攻击防护。
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
if not hasattr(tokenizer, 'model_dir'):
tokenizer.model_dir = model_dir
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, bf16=True).eval()
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, fp16=True).eval()
# 使用CPU进行推理,需要约32GB内存
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="cpu", trust_remote_code=True).eval()
# 默认使用自动模式,根据设备自动选择精度
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval()
# 可指定不同的生成长度、top_p等相关超参
model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True)
# 第一轮对话 1st dialogue turn
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'},
{'text': '这是什么'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)
# 图中是一名年轻女子在沙滩上和她的狗玩耍,狗的品种是拉布拉多。她们坐在沙滩上,狗的前腿抬起来,与人互动。
# 第二轮对话 2st dialogue turn
response, history = model.chat(tokenizer, '输出击掌的检测框', history=history)
print(response)
# <ref>"击掌"</ref><box>(211,412),(577,891)</box>
image = tokenizer.draw_bbox_on_latest_picture(response, history)
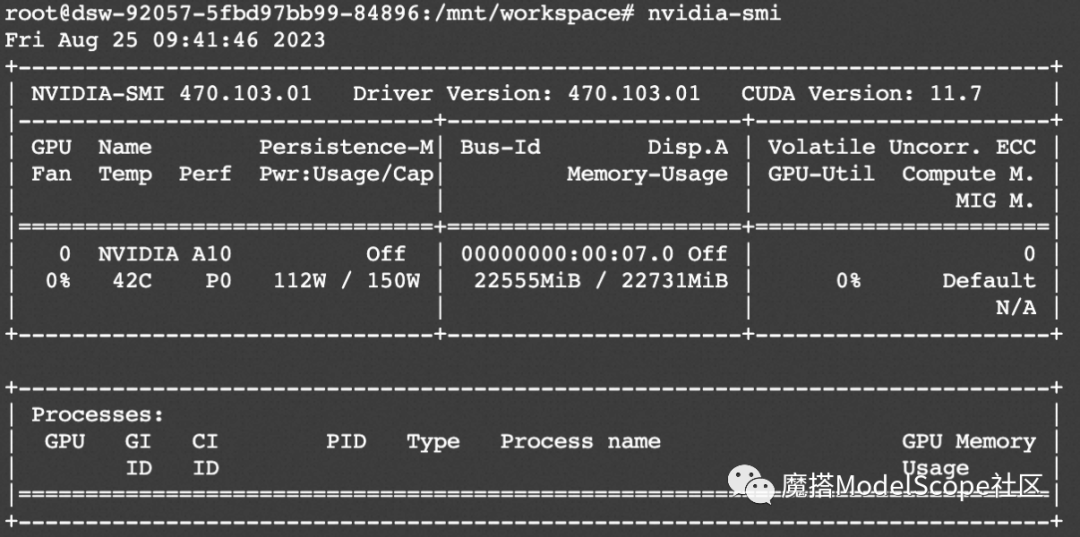
image.save('output_chat.jpg')资源消耗
模型微调和微调后推理
在notebook的Terminal下执行如下代码:
微调代码开源地址: https://github.com/modelscope/swift/blob/main/examples/pytorch/llm
git clone https://github.com/modelscope/swift.git
cd swift
pip install .
cd examples/pytorch/llm
模型微调脚本 (qlora)
# 14GB VRAM
CUDA_VISIBLE_DEVICES=0 \
python src/llm_sft.py \
--model_type qwen-vl-chat \
--sft_type lora \
--template_type chatml \
--dtype bf16 \
--output_dir runs \
--dataset coco-en \
--dataset_sample 20000 \
--num_train_epochs 1 \
--max_length 1024 \
--quantization_bit 4 \
--bnb_4bit_comp_dtype bf16 \
--lora_rank 64 \
--lora_alpha 16 \
--lora_dropout_p 0.05 \
--lora_target_modules ALL \
--batch_size 1 \
--weight_decay 0. \
--learning_rate 1e-4 \
--gradient_accumulation_steps 16 \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 10 \
--use_flash_attn false \
--push_to_hub false \
--hub_model_id qwen-vl-chat-qlora \
--hub_private_repo true \
--hub_token 'your-sdk-token' \
模型微调后的推理脚本
# 10G
CUDA_VISIBLE_DEVICES=0 \
python src/llm_infer.py \
--model_type qwen-vl-chat \
--sft_type lora \
--template_type chatml \
--dtype bf16 \
--ckpt_dir "runs/qwen-vl-chat/vx_xxx/checkpoint-xxx" \
--eval_human false \
--dataset coco-en \
--dataset_sample 20000 \
--quantization_bit 4 \
--bnb_4bit_comp_dtype bf16 \
--max_new_tokens 1024 \
--temperature 0.9 \
--top_k 50 \
--top_p 0.9 \
--do_sample true \微调的可视化结果
训练损失:
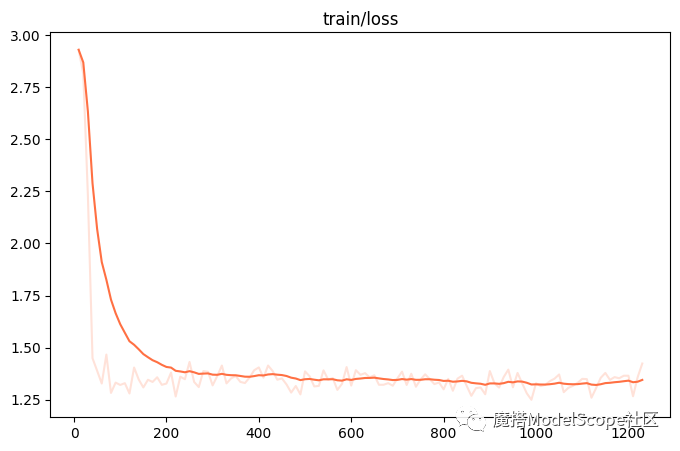
评估损失

资源消耗
qwen-vl-chat使用qlora的方式训练的显存占用如下,大约在14G. (quantization_bit=4, batch_size=1, max_length=1024)

大家如有其他问题与需求可以通过微信扫码加入通义千问群沟通~

体验链接: https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 1
1- 0



 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)