
社区供稿 | 10G显存,通义千问-7B-int4消费级显卡最佳实践
导读
在魔搭社区,通义千问团队发布了Qwen-7B-Chat的Int4量化模型,Qwen-7B-Chat-Int4。该方案的优势在于,它能够实现几乎无损的性能表现,模型大小仅为5.5GB,内存消耗低,速度甚至超过BF16。
环境配置与安装
- 本文实例均在魔搭社区的PAI-DSW Notebook(GPU版本)直接运行
- python>=3.8
使用步骤
本文在ModelScope的Notebook的环境(这里以PAI-DSW为例)配置下运行 (可单卡运行, 显存要求20G)
服务器连接与环境准备
1、进入ModelScope首页:modelscope.cn,进入我的Notebook
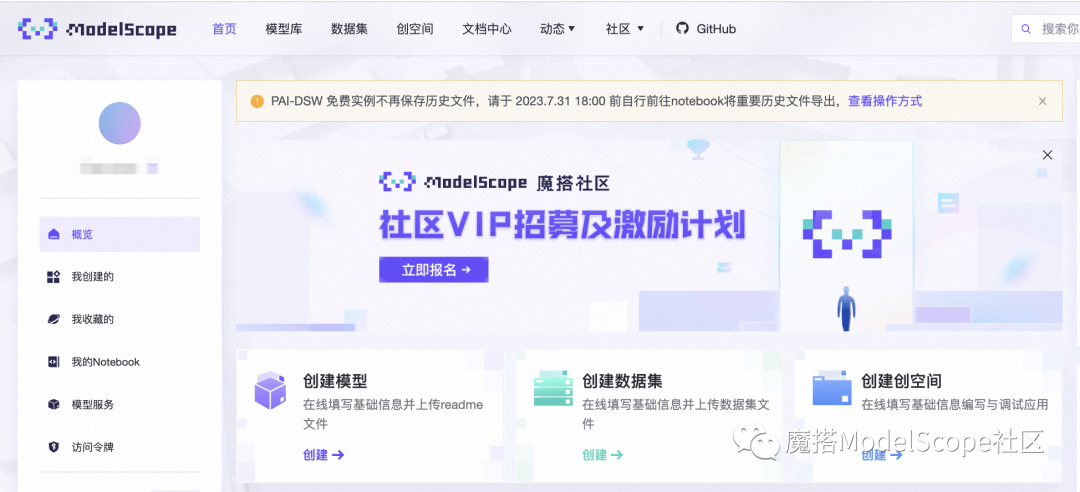
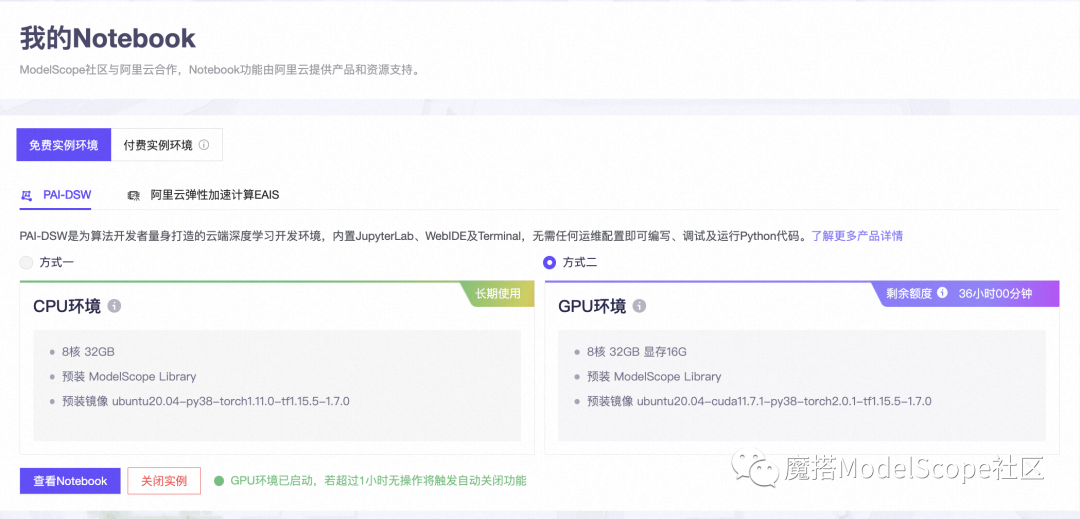
2、选择GPU环境,进入PAI-DSW在线开发环境
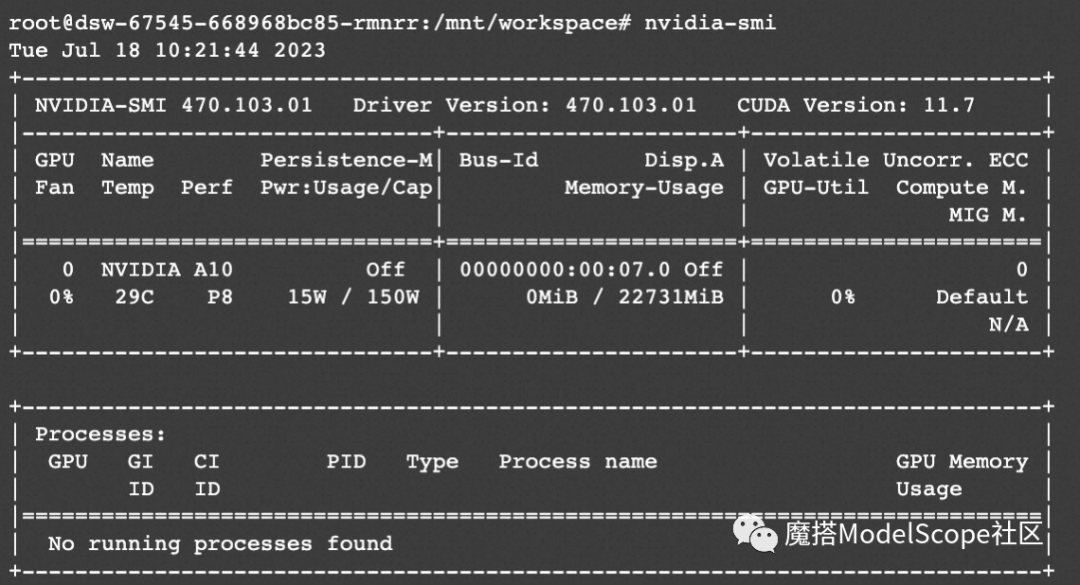
3、进入Terminal,先查看一下GPU的使用情况
更新量化方案为基于AutoGPTQ的量化,提供Qwen-7B-Chat的Int4量化模型。相比此前方案,该方案在模型评测效果几乎无损,且存储需求更低,推理速度更优。
以下我们提供示例说明如何使用Int4量化模型。在开始使用前,请先保证满足AutoGPTQ的要求,并使用源代码安装(由于最新支持Qwen的代码未发布到PyPI):
git clone https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
pip install .
模型下载
通义千问-7B-Chat-int4现已在ModelScope社区开源:https://modelscope.cn/models/qwen/Qwen-7B-Chat-Int4/summary
from modelscope import snapshot_download
from auto_gptq import AutoGPTQForCausalLM
model_dir = snapshot_download("qwen/Qwen-7B-Chat-Int4", revision='v1.0.0')
读取量化模型
随后便能轻松读取量化模型
from auto_gptq import AutoGPTQForCausalLM
model = AutoGPTQForCausalLM.from_quantized(model_dir, device_map="auto",revision = 'v1.0.0', trust_remote_code=True, use_safetensors=True).eval()
模型推理
推理方法和基础用法类似,但注意需要从外部传入generation config:
from modelscope import GenerationConfig
config = GenerationConfig.from_pretrained("qwen/Qwen-7B-Chat-Int4", revision='v1.0.0', trust_remote_code=True)
response, history = model.chat(tokenizer, "Hi", history=None, generation_config=config)
快速使用
如下是一个使用Qwen-7B-Chat-int4模型,进行多轮对话交互的样例:
from modelscope import (
snapshot_download, AutoModelForCausalLM, AutoTokenizer, GenerationConfig
)
from auto_gptq import AutoGPTQForCausalLM
model_dir = snapshot_download("qwen/Qwen-7B-Chat-Int4", revision='v1.0.0')
# Note: The default behavior now has injection attack prevention off.
tokenizer = AutoTokenizer.from_pretrained(model_dir, revision = 'v1.0.0',trust_remote_code=True)
model = AutoGPTQForCausalLM.from_quantized(model_dir, device_map="auto",revision = 'v1.0.0', trust_remote_code=True, use_safetensors=True).eval()
# Specify hyperparameters for generation
config = GenerationConfig.from_pretrained(model_dir, revision = 'v1.0.0',trust_remote_code=True)
response, history = model.chat(tokenizer, "你好", history=None, generation_config=config)
print(response)
# 你好!很高兴为你提供帮助。效果评测
效果评测
我们对BF16和Int4模型在基准评测上做了测试,发现量化模型效果损失较小,结果如下所示:
|
Quantization |
MMLU |
CEval (val) |
GSM8K |
Humaneval |
|
BF16 |
53.9 |
54.2 |
41.1 |
24.4 |
|
Int4 |
52.6 |
52.9 |
38.1 |
23.8 |
推理速度 (Inference Speed)
我们测算了BF16和Int4模型生成2048和8192个token的平均推理速度。如图所示:
|
Quantization |
Speed (2048 tokens) |
Speed (8192 tokens) |
|
BF16 |
30.53 |
28.51 |
|
Int4 |
45.60 |
33.83 |
具体而言,我们记录在长度为1的上下文的条件下生成8192个token的性能。评测运行于单张A100-SXM4-80G GPU,使用PyTorch 2.0.1和CUDA 11.4。推理速度是生成8192个token的速度均值。
显存使用 (GPU Memory Usage)
我们还测算了BF16和Int4模型编码2048个token及生成8192个token的峰值显存占用情况。结果如下所示:
|
Quantization Level |
Peak Usage for Encoding 2048 Tokens |
Peak Usage for Generating 8192 Tokens |
|
BF16 |
18.99GB |
24.40GB |
|
In4 |
10.20GB |
15.61GB |
具体显存占用截图:

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 1
1- 0



 已为社区贡献657条内容
已为社区贡献657条内容

所有评论(0)