


最近魔搭上线了一项新能力——仅需输入单张人像照片,利用文字或语音驱动即可秒级生成数字人AI视频!这让小编的短视频UP梦又重新启航燃起了希望!它完全解救了社恐星人,图生视频能力替你说话、唱歌、讲段子、吟诗....无需再对着摄像头NG,一整个绝绝子叠buff!
https://live.csdn.net/v/318703
颤抖的心,激动的手,看了如上用图片秒级生成视频的demo,接下来小编为大家解锁不同的玩法,并揭秘其中的技术原理,多视频预警!
玩法大赏
1、让它替你唱歌、Rap、讲段子....秒变演绎大咖
https://live.csdn.net/v/318704
https://live.csdn.net/v/318707
https://live.csdn.net/v/318710
2、快速制作企业数字形象名片
https://live.csdn.net/v/318709
3、多语种、多方言智能播报和讲解,更是不在话下
https://live.csdn.net/v/318708
https://live.csdn.net/v/318711
4、风格视频也是信手拈来
https://live.csdn.net/v/318727
咱们试想一下,有了通义万相文生图的能力,再叠加单图生成视频的能力,仅需要几个字,咱们就可以秒级生成数字人AI视频,这里面的趣味玩法欢迎来解锁。
作为达摩院XR实验室首个在魔搭上线的创空间,我们也为大家揭秘这其中的核心技术点。
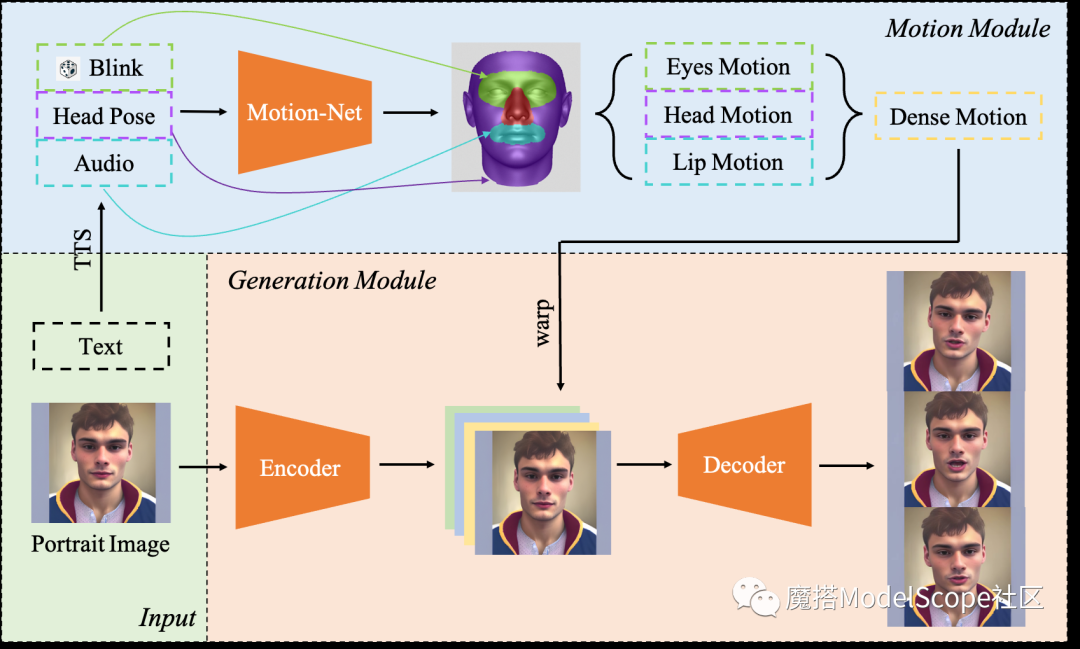
Live Portrait pipeline示意图
单图生成视频Live Portrait的能力可以划分为两个模块:运动模块(Motion Module)和生成模块(Generation Module)。
Motion Module
-
输入:用户上传的文字或音频
-
输出:稠密运动序列
-
描述:如果用户上传的是一段文字,我们会首先使用Text-to-Speech(TTS)技术将其转化为音频;我们将【音频、固定的头姿序列、随机的眨眼信号】输入Motion Net,预测得到嘴部运动特征(Lip Motion)、头部运动特征(Head Motion)和眼部运动特征(Eyes motion);随后,我们用一个简单的网络将三种运动特种融合并生成稠密运动序列(Piexl-Level Dense Motion Sequence)
Generation Module
-
输入:用户上传的照片 + Motion Module输出的稠密运动序列
-
输出:生成说话视频
-
描述:首先,我们将用户上传的照片输入Encoder得到中间层特征;随后,我们用Motion Module生成的稠密运动序列对原图和特征进行变形操作(warp),并将变形后的图片和特征进行拼接,输入Decoder生成最终的说话视频序列。
1、注册并登陆魔搭平台
进入ModelScope官网:https://modelscope.cn/home,点击右上角“登陆/注册”,进入注册页面,并填写注册所需信息完成注册。建议用手机号注册最快。
2、访问单图生成视频LivePortrait的创空间页面
账号登陆后进入创空间页面 https://modelscope.cn/studios/DAMOXR/LivePortrait/summary
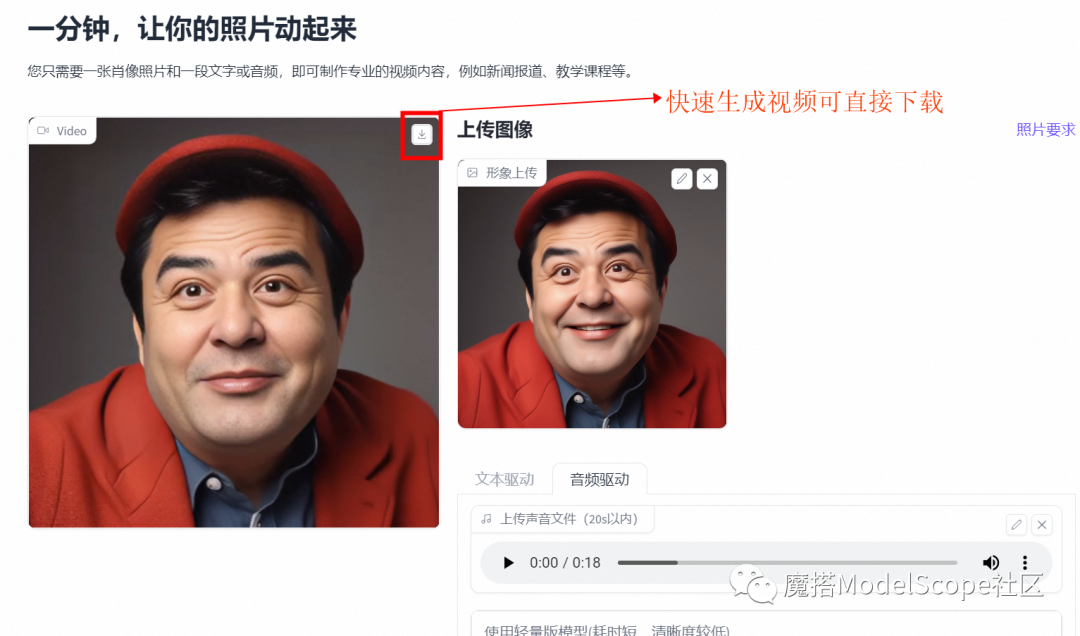
3、选择示例输入,即可在快速生成视频并下载(简易体验版)

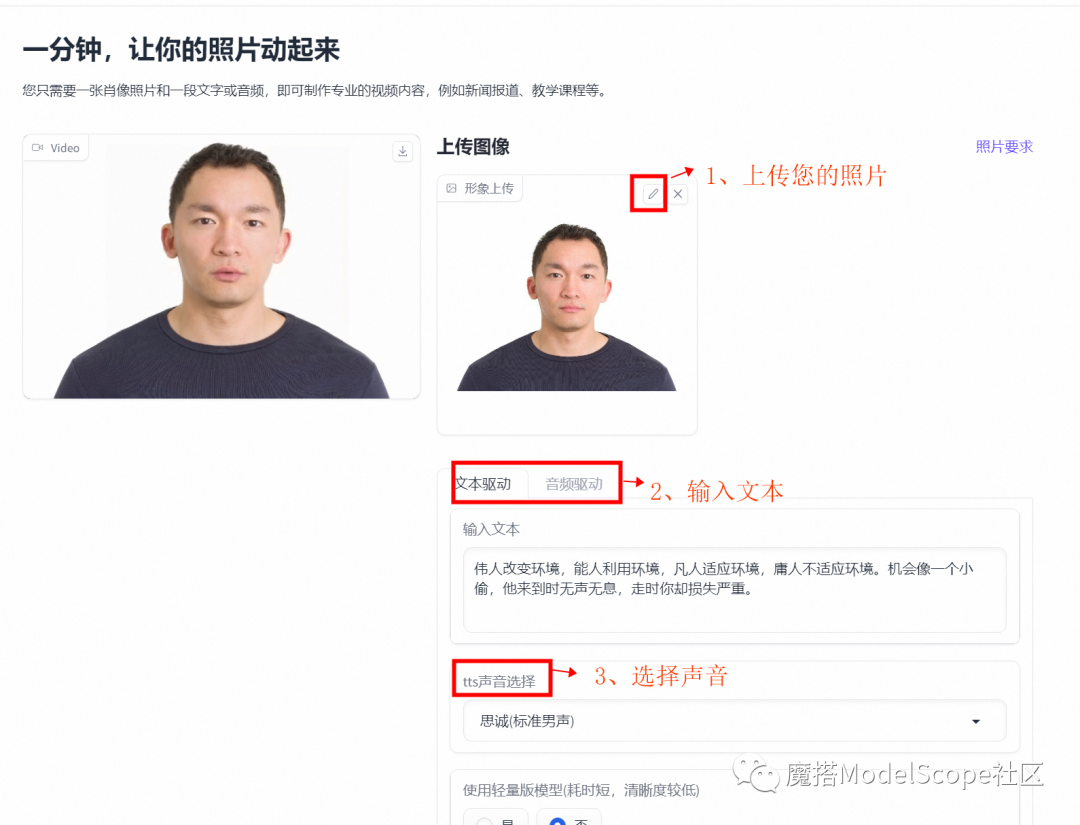
4、充分发挥你的创意(充分体验版)
文本驱动
音频驱动
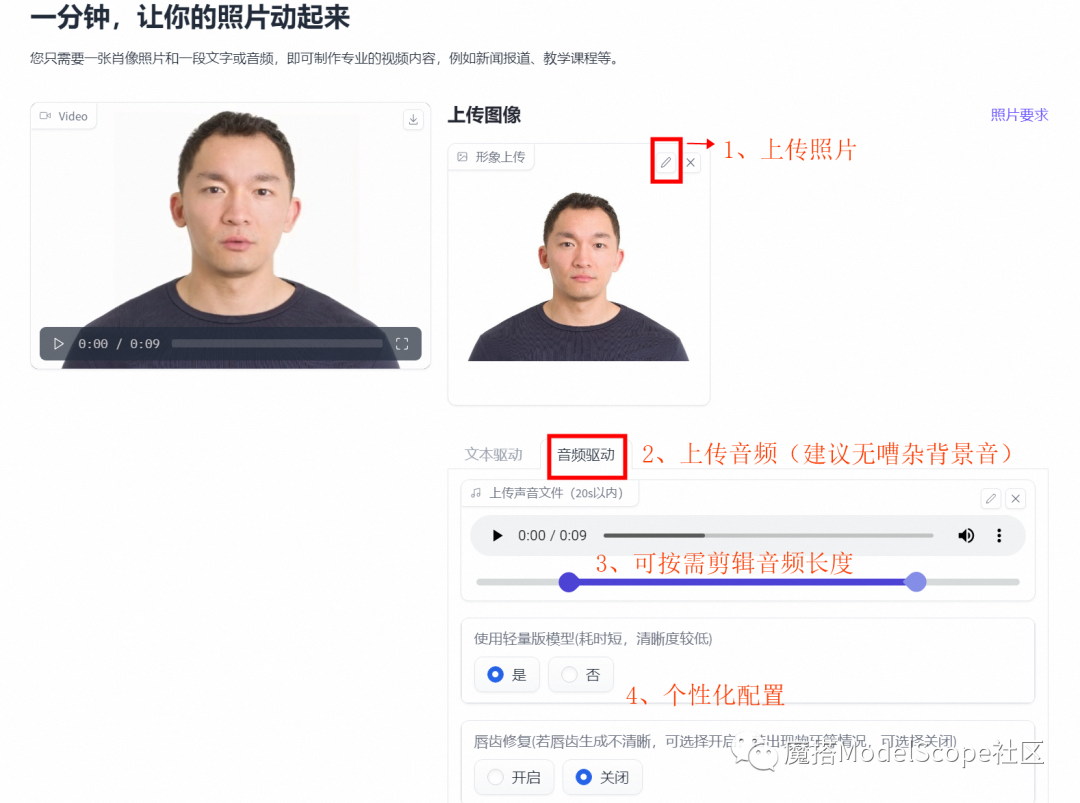
小Tips:请上传有版权的肖像照,涉及政治敏感等内容将被过滤。
如上配置完毕后请确认授权后开始生成
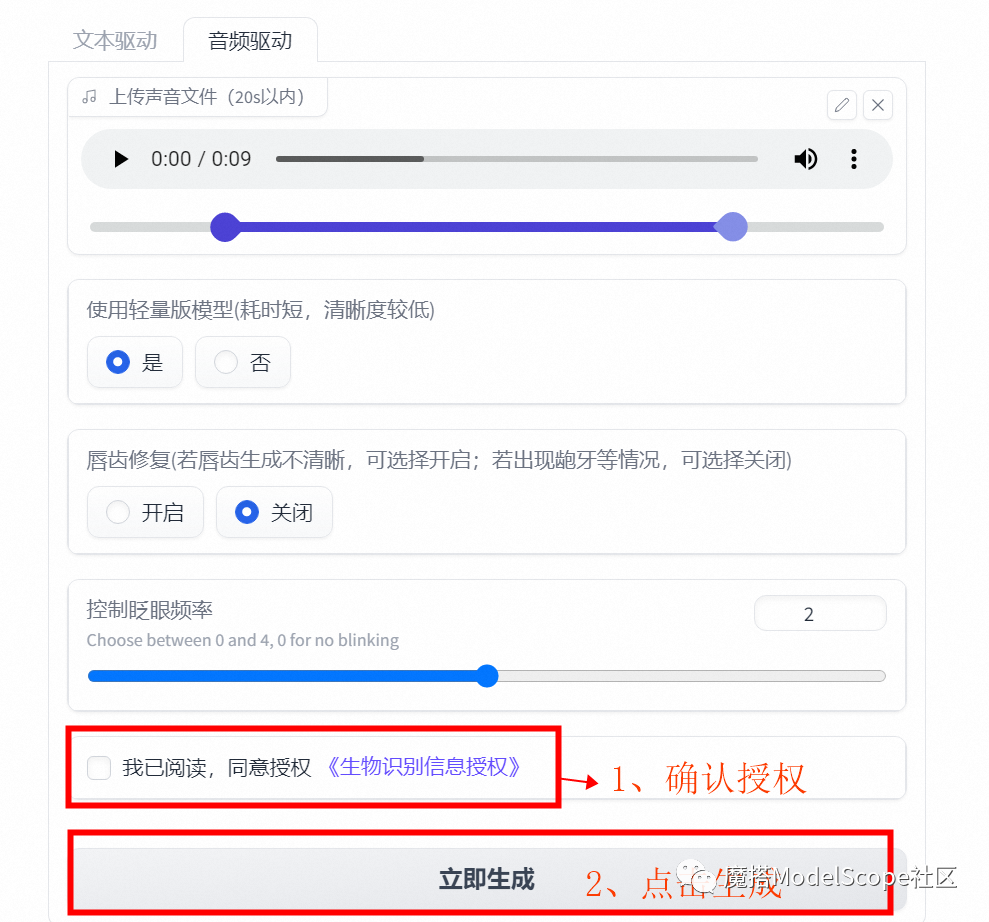
获取/保存视频结果
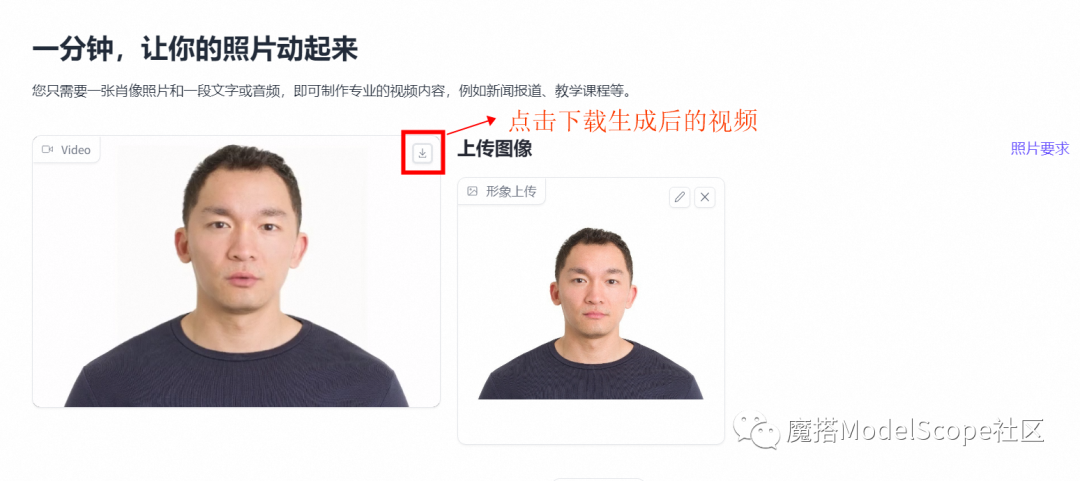
还在等什么,让我们一起来点燃梦想,铸就辉煌,在AIGC的路上成就更好的你!








 已为社区贡献644条内容
已为社区贡献644条内容

所有评论(0)