

导言:
魔搭社区前不久推出了ModelScopeGPT,允许各种LLM与ModelScope上各种行业SOTA模型进行交互,也为大模型产业化使用提供了新范式。本文结合LLM的理解能力,再去调用精确的OCR工具,来实现了智能文档agent的应用,也有很大的想象空间,比如发票报销小助手,个人证照管理助手等。
技术架构图:
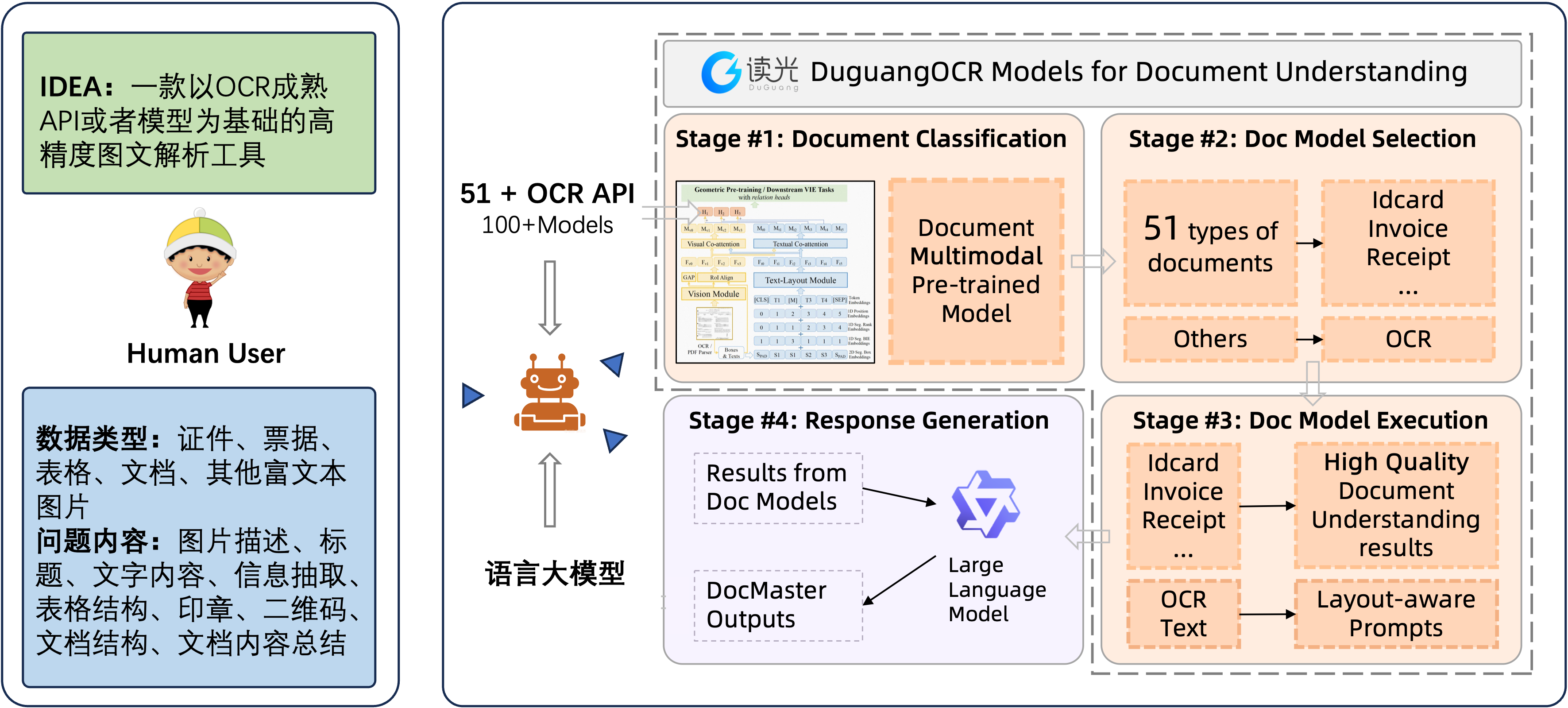
基于精准且种类丰富的OCR API或者模型,DocMaster可以读取理解并响应复杂的文档图文信息,不仅包括传统的OCR内容数字化,还包括多模态的信息抽取,以及调佣大模型可以完成的发散类问题。
DocMaster响应用户提问的处理的主流程分为四步
这四个步骤依次调用了:
1、文档分类功能。开发者可以训练自己的分类器,或是基于视觉,或是基于语言,再或基于视觉-语言联合的模型。纯视觉的方案在效率上会更高,但是对于视觉线索相近的类型会有降低。基于语言或者多模态的方案,需要做一遍OCR,效率上不占优势,但效果会更好。我们使用了多模态的方案,参考开源模型(https://modelscope.cn/models/damo/multi-modal_convnext-roberta-base_vldoc-embedding)
2、选择对应分类下的模型或者API。这一步的可扩展性较强,首先,开发者可以使用开源的OCR模型,不论是Modelscope上模型,还是Paddle上的OCR模型,组装成常规OCR服务,参考(https://modelscope.cn/studios/damo/cv_ocr-text-spotting/summary)。其次,开发者还可以使用成熟的API,如阿里云上的读光OCR API,或者其他云厂商的API ,这些API背后使用了更多专业数据以及算法精调和工程优化,效果和效率会更高。我们在这里使用了表格文字识别、手写文字识别、印章识别、卡证识别和票据识别等核心能力,可以参加下一章节的API链接。
3、使用开源模型或者API完成数字化和信息抽取以及构建OCR友好的prompts。数字化和信息抽取是在选择对应模型或者功能后要做的核心事情,常规的版面分析、文字检测、文字识别,都是做文档中文字和图像数字化的关键,而卡证和票据以及一些纯文本的IE算法都是做信息抽取的可取方案。得到不同来源的数字化和信息化之后,有必要对这些结果进行归一化,例如格式的对齐,key键值的对齐等。图文信息往往是二维的空间信息,且常常是有阅读顺序和层级结构化的,因此需要构建OCR优化的prompts,我们此处使用了Layout-aware prompts,后续会在学术成果发表开源给公众。
4、基于前述的OCR结果和用户的输入问题对,调用LLM完成问题的回答。在这里,我们利用了大语言模型三点优势来完成我们的文档精准对话问答,其一对用户输入问题的理解能力;其二对前述未覆盖的长尾文档的信息抽取能力;其三对开放式问题的回答能力。我们在这里使用了通义千问的能力,开发者也可以使用modelscope上众多的开源语言模型。
最佳实践:
利用modelscope上的OCR模型包括文字检测、印刷文字识别、手写文字识别、有线表格识别、无线表格识别,以及阿里云上可以免费或付费使用的OCR接口,你可以搭建票据解析助手、证件核验助手、以及表格信息统计助手等实用型工具,也可以DIY一个类似DocMaster的文档精准文档机器人,用更自然方式和人交流。
OCR模型库(https://modelscope.cn/topic/f285bd172da6452489e7adf99334cf45/pub/summary)
OCR API库(https://duguang.aliyun.com/)
目前DocMaster已经在魔搭创空间上线,开发者可以参考我们在创空间中的链路,了解agent的使用过程,后续待我们开源更多模型后,我们也会披露更多细节。
链接:https://modelscope.cn/studios/damo/DocMaster/summary








 已为社区贡献645条内容
已为社区贡献645条内容

所有评论(0)