
通晓多语言|PolyLM多语言模型和数据集魔搭社区发布
同时,基于SFT阶段,PolyLM的研发团队构建了一个名为MULTIALPACA的多语言指令数据集,包含了132,701个样本,设计了一种多语言自指导方法来自动生成数据,以175个英语种子为起点,利用多语言种子翻译、指令生成和过滤机制来提供高质量的多语言指令数据集。该数据集现已在魔搭社区开源。
-
本文可在双卡V100的环境配置下运行 (显存要求48G)
-
python>=3.8
实验环境准备
# Install the latest version of modelscope from source
git clone https://github.com/modelscope/modelscope.git
cd modelscope
pip install .
PolyLM-13B
https://www.modelscope.cn/models/damo/nlp_polylm_13b_text_generation/summary
PolyLM-MultiAlpaca-13B
https://modelscope.cn/models/damo/nlp_polylm_multialpaca_13b_text_generation/summary
PolyLM-Chat-13B
https://www.modelscope.cn/models/damo/nlp_polylm_assistant_13b_text_generation/summary
模型下载,load model,tokenizer
import torch
from modelscope import AutoConfig, AutoTokenizer, AutoModelForCausalLM
model_id = 'damo/nlp_polylm_13b_text_generation'
model_config = AutoConfig.from_pretrained(
model_id, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(
model_id, trust_remote_code=True, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(
model_id,
config=model_config,
device_map='auto',
torch_dtype=torch.bfloat16,
trust_remote_code=True)
MultiAlpaca多语言指令精调数据集现已在ModelScope社区开源
MultiAlpaca多语言指令精调数据集
https://modelscope.cn/datasets/damo/nlp_polylm_multialpaca_sft/summary
数据集下载,load
from modelscope.msdatasets import MsDataset
ds = MsDataset.load('damo/nlp_polylm_multialpaca_sft', subset_name='ar', split='train')
print(next(iter(ds)))
# Note: subset_name参数设置参考上表中的Language-key
PolyLM多语言智能服务机器人创空间链接:https://modelscope.cn/studios/damo/demo-polylm-multialpaca-13b/summary
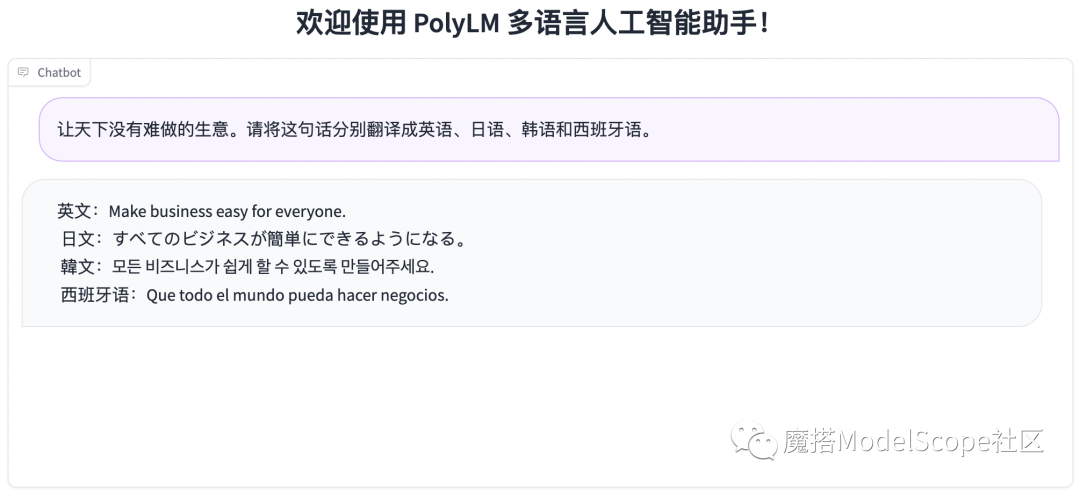
可以使用下面的代码进行PolyLM-13B模型的推理:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
polylm_13b_model_id = 'damo/nlp_polylm_13b_text_generation'
input_text = f"Beijing is the capital of China.\nTranslate this sentence from English to Chinese."
kwargs = {"do_sample": False, "num_beams": 4, "max_new_tokens": 128, "early_stopping": True, "eos_token_id": 2}
pipeline_ins = pipeline(Tasks.text_generation, model=polylm_13b_model_id)
result = pipeline_ins(input_text, **kwargs)
print(result['text'])
可以使用下面的代码进行PolyLM-MultiAlpaca-13B模型的推理:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
polylm_multialpaca_13b_model_id = 'damo/nlp_polylm_multialpaca_13b_text_generation'
input_text = f"Beijing is the capital of China.\nTranslate this sentence from English to Chinese."
kwargs = {
"do_sample": True,
"top_p": 0.8,
"temperature": 0.7,
"repetition_penalty": 1.02,
"max_new_tokens": 128,
"num_return_sequences": 1,
"early_stopping": True,
"eos_token_id": 2
}
pipeline_ins = pipeline(Tasks.text_generation, model=polylm_multialpaca_13b_model_id)
result = pipeline_ins(f"{input_text}\n\n", **kwargs)
print(result['text'])
可以使用下面的代码进行PolyLM-Chat-13B模型的推理:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
polylm_13b_model_id = 'damo/nlp_polylm_assistant_13b_text_generation'
input_text = f"Beijing is the capital of China.\nTranslate this sentence from English to Chinese."
input_text = "<|user|>\n" + f"{input_text}\n" + "<|assistant|>\n"
kwargs = {"do_sample": False, "num_beams": 4, "max_new_tokens": 128, "early_stopping": True, "eos_token_id": 2}
pipeline_ins = pipeline(Tasks.text_generation, model=polylm_13b_model_id, **kwargs)
result = pipeline_ins(input_text)
print(result['text'])

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)