
LLaMA 2系列来啦!内含魔搭最佳实践
近期,Facebook母公司Meta发布其首个开源可商用大语言模型LLama 2。据悉,LLama 2是Meta大语言模型Llama模型的最新商用版本,也是Meta首个免费商用的大语言模型。
魔搭社区第一时间针对LLama 2 系列模型的推理和微调做了适配,让开发者可以第一时间玩起来Llama 2。
环境配置与安装
1. 本文可在单卡3090的环境配置下运行 (显存要求16G)
2. python>=3.8
服务器连接与环境准备
# 服务器连接 (CentOS)
ssh root@xxx.xxx.xxx.xxx # 可通过vscode连接
passwd # 修改root密码
lsb_release -a # 查看操作系统版本
# 安装git并配置
yum install git
git config --global user.name "llama2"
git config --global user.email "llama2@abc.com"
git config --global init.defaultBranch main
git config --list
# 创建用户, 并设置密码(当然你也可以在root下操作)
useradd -d /home/llama2 -m llama2
passwd llama2
su llama2
# 安装miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 一直[ENTER], 最后一个选项yes即可
sh Miniconda3-latest-Linux-x86_64.sh
# conda虚拟环境搭建
conda create --name modelscope python=3.10
conda activate modelscope
# pip设置全局镜像与相关python包安装
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
pip install numpy pandas matplotlib scikit-learn
pip install transformers datasets -U
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
pip install tqdm tensorboard torchmetrics sentencepiece charset_normalizer
pip install accelerate transformers_stream_generator
# 安装最新版modelscope
pip install "modelscope==1.7.2rc0" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
# Resolve torchmetrics dependencies and update numpy
pip install numpy -U
git clone ModelScope,运行示例代码
git clone https://github.com/modelscope/modelscope.git进入python环境,获取环境基本信息
# https://github.com/modelscope/modelscope/blob/master/examples/pytorch/llm/_common.py
from _common import *
device_ids = [0, 1]
logger.info(device_ids)
select_device(device_ids)
seed_everything(42)
模型链接和下载
LLama 2系列模型现已在ModelScope社区开源,包括:
LLaMA-2-7B
模型链接:https://modelscope.cn/models/modelscope/Llama-2-7b-ms/summary
LLaMA-2-7B-chat
模型链接:https://modelscope.cn/models/modelscope/Llama-2-7b-chat-ms/summary
更多的LLaMa-2系列模型,社区上架中~~
社区支持直接下载模型的repo. 通过如下代码,实现模型下载,以及load model, tokenizer:
# ### Loading Model and Tokenizer
model_dir = snapshot_download('modelscope/Llama-2-7b-ms', 'v1.0.1')
model, tokenizer = get_llama2_model_tokenizer(model_dir)
模型推理
LLaMA-2-7B推理代码
from modelscope import snapshot_download, Model
from modelscope.models.nlp.llama2 import Llama2TokenizerFast
model_dir = snapshot_download("modelscope/Llama-2-7b-ms", 'v1.0.1')
model = Model.from_pretrained(model_dir)
tokenizer = Llama2TokenizerFast.from_pretrained(model_dir)
prompt = "Hey, are you conscious? Can you talk to me?"
inputs = tokenizer(prompt, return_tensors="pt")
# Generate
generate_ids = model.generate(inputs.input_ids, max_length=30)
print(tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0])
数据集链接和下载
这里使用alpaca-gpt4-data-zh,alpaca-gpt4-data-en作为指令微调数据集(保证代码的完整性)。
from modelscope import MsDataset
dataset_zh = MsDataset.load("AI-ModelScope/alpaca-gpt4-data-zh", split="train")
dataset_en = MsDataset.load("AI-ModelScope/alpaca-gpt4-data-en", split="train")
print(len(dataset_zh["instruction"]))
print(len(dataset_en["instruction"]))
print(dataset_zh[0])
"""Out
48818
52002
{'instruction': '保持健康的三个提示。', 'input': None, 'output': '以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。'}
"""
模型训练最佳实践
开源代码:
https://github.com/modelscope/modelscope/blob/master/examples/pytorch/llm/llm_sft.py
微调过程分为如下几步:
- 准备环境
- 使用modelscope下载模型, 并导入
- 使用modelscope提供的微调方法构建最终模型
- 使用modelscope提供的Trainer对模型进行微调
准备环境及命令后参数导入:
from _common import *
@dataclass
class Arguments:
device: str = '0,1' # e.g. '-1'; '0'; '0,1'
seed: int = 42
model_type: str = field(
default='llama2-7b',
metadata={
'choices':
['baichuan-7b', 'baichuan-13b', 'chatglm2', 'llama2-7b']
})
data_sample: Optional[int] = None
#
lora_target_modules: Optional[List[str]] = None
lora_rank: int = 8
lora_alpha: int = 32
lora_dropout_p: float = 0.1
#
gradient_checkpoint: bool = True
batch_size: int = 1
max_epochs: int = 1
eval_interval: int = 500
learning_rate: float = 1e-4
weight_decay: float = 0.01
n_accumulate_grad: int = 16
grad_clip_norm: float = 1.
warmup_iters: int = 200
last_max_checkpoint_num: int = 1
best_max_checkpoint_num: int = 1
#
logging_interval: int = 5
tb_interval: int = 5
def __post_init__(self):
if self.lora_target_modules is None:
if self.model_type in {'baichuan-7b', 'baichuan-13b'}:
self.lora_target_modules = ['W_pack']
elif self.model_type == 'chatglm2':
self.lora_target_modules = ['query_key_value']
elif self.model_type == 'llama2-7b':
self.lora_target_modules = ['q_proj', 'k_proj', 'v_proj']
else:
raise ValueError(f'model_type: {self.model_type}')
def parse_args() -> Arguments:
args, = HfArgumentParser([Arguments]).parse_args_into_dataclasses()
return args
args = parse_args()
logger.info(args)
select_device(args.device)
seed_everything(args.seed)
导入模型:
# ### Loading Model and Tokenizer
if args.model_type == 'baichuan-7b':
model_dir = snapshot_download('baichuan-inc/baichuan-7B', 'v1.0.5')
model, tokenizer = get_baichuan_model_tokenizer(model_dir)
elif args.model_type == 'baichuan-13b':
model_dir = snapshot_download('baichuan-inc/Baichuan-13B-Base', 'v1.0.2')
model, tokenizer = get_baichuan_model_tokenizer(model_dir)
elif args.model_type == 'chatglm2':
model_dir = snapshot_download('ZhipuAI/chatglm2-6b', 'v1.0.6')
model, tokenizer = get_chatglm2_model_tokenizer(model_dir)
elif args.model_type == 'llama2-7b':
model_dir = snapshot_download('modelscope/Llama-2-7b-ms', 'v1.0.0')
model, tokenizer = get_llama2_model_tokenizer(model_dir)
else:
raise ValueError(f'model_type: {args.model_type}')
#
if args.gradient_checkpoint:
# baichuan-13b does not implement the `get_input_embeddings` function
if args.model_type == 'baichuan-13b':
def get_input_embeddings(self):
return self.model.embed_tokens
model.__class__.get_input_embeddings = get_input_embeddings.__get__(
model)
model.gradient_checkpointing_enable()
model.enable_input_require_grads()准备LoRA:
# ### Preparing lora
lora_config = LoRAConfig(
replace_modules=args.lora_target_modules,
rank=args.lora_rank,
lora_alpha=args.lora_alpha,
lora_dropout=args.lora_dropout_p)
logger.info(f'lora_config: {lora_config}')
Swift.prepare_model(model, lora_config)
#
show_freeze_layers(model)
print_model_info(model)
_p: Parameter = list(model.parameters())[100]
logger.info(f'device: {_p.device}, dtype: {_p.dtype}')
model.bfloat16()导入datasets:
# ### Loading Dataset
tokenize_function = partial(tokenize_function, tokenizer=tokenizer)
train_dataset, val_dataset = get_alpaca_en_zh_dataset(
tokenize_function, split_seed=42, data_sample=args.data_sample)
# Data analysis
stat_dataset(train_dataset)
stat_dataset(val_dataset)
data_collate_fn = partial(data_collate_fn, tokenizer=tokenizer)
print_example(train_dataset[0], tokenizer)配置Config:
# ### Setting Config
cfg_file = os.path.join(model_dir, 'configuration.json')
#
T_max = get_T_max(len(train_dataset), args.batch_size, args.max_epochs, True)
work_dir = get_work_dir(f'runs/{args.model_type}')
config = Config({
'train': {
'dataloader': {
'batch_size_per_gpu': args.batch_size,
'workers_per_gpu': 1,
'shuffle': True,
'drop_last': True,
'pin_memory': True
},
'max_epochs':
args.max_epochs,
'work_dir':
work_dir,
'optimizer': {
'type': 'AdamW',
'lr': args.learning_rate,
'weight_decay': args.weight_decay,
'options': {
'cumulative_iters': args.n_accumulate_grad,
'grad_clip': {
'norm_type': 2,
'max_norm': args.grad_clip_norm
}
}
},
'lr_scheduler': {
'type': 'CosineAnnealingLR',
'T_max': T_max,
'eta_min': 0,
'options': {
'by_epoch': False,
'warmup': {
'type': 'LinearWarmup',
'warmup_ratio': 0.1,
'warmup_iters': args.warmup_iters
}
}
},
'hooks': [
{
'type': 'CheckpointHook',
'by_epoch': False,
'interval': args.eval_interval,
'max_checkpoint_num': args.last_max_checkpoint_num
},
{
'type': 'EvaluationHook',
'by_epoch': False,
'interval': args.eval_interval
},
{
'type': 'BestCkptSaverHook',
'metric_key': 'loss',
'save_best': True,
'rule': 'min',
'max_checkpoint_num': args.best_max_checkpoint_num
},
{
'type': 'TextLoggerHook',
'by_epoch': True, # Whether EpochBasedTrainer is used
'interval': args.logging_interval
},
{
'type': 'TensorboardHook',
'by_epoch': False,
'interval': args.tb_interval
}
]
},
'evaluation': {
'dataloader': {
'batch_size_per_gpu': args.batch_size,
'workers_per_gpu': 1,
'shuffle': False,
'drop_last': False,
'pin_memory': True
},
'metrics': [{
'type': 'my_metric',
'vocab_size': tokenizer.vocab_size
}]
}
})
开启微调:
# ### Finetuning
def cfg_modify_fn(cfg: Config) -> Config:
cfg.update(config)
return cfg
trainer = EpochBasedTrainer(
model=model,
cfg_file=cfg_file,
data_collator=data_collate_fn,
train_dataset=train_dataset,
eval_dataset=val_dataset,
remove_unused_data=True,
seed=42,
device='cpu', # No placement for model, leave the model to `device_map`
cfg_modify_fn=cfg_modify_fn,
)
trainer.train()
可视化:
Tensorboard 命令: (e.g.)
tensorboard --logdir /home/llama2/my_git/modelscope/runs/llama2-7b/v1-20230719-161919 --port 6006
# ### Visualization
tb_dir = os.path.join(work_dir, 'tensorboard_output')
plot_image(tb_dir, ['loss'], 0.9)
训练损失:
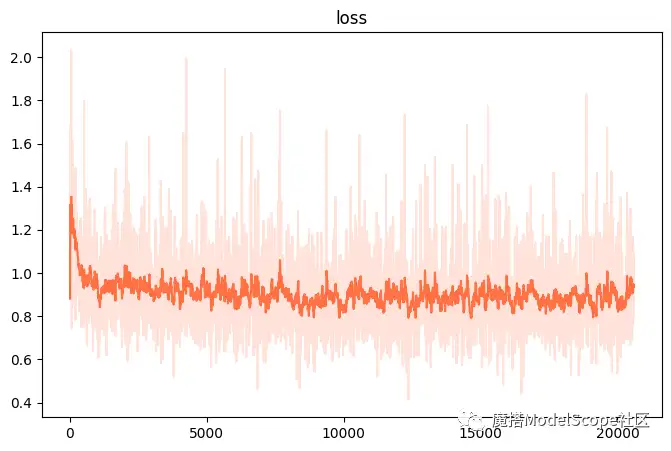
验证损失:
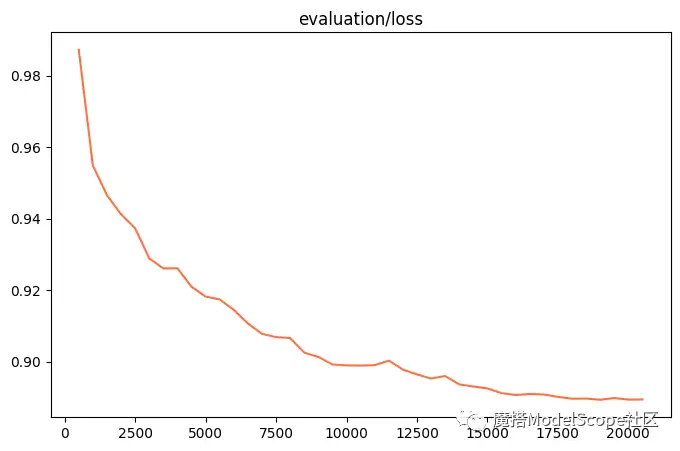
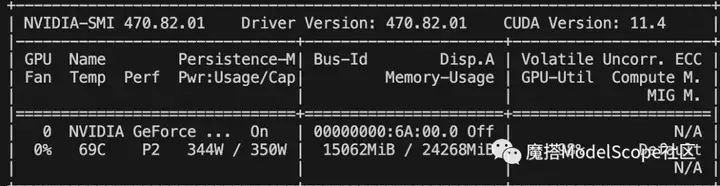
资源消耗
LLaMA-2-7B用lora的方式训练的显存占用如下,大约在16G. (batch_size=1, max_length=2048)
推理训练后的模型
开源代码:
https://github.com/modelscope/modelscope/blob/master/examples/pytorch/llm/llm_infer.py
# ### Setting up experimental environment.
from _common import *
@dataclass
class Arguments:
device: str = '0' # e.g. '-1'; '0'; '0,1'
model_type: str = field(
default='llama2-7b',
metadata={
'choices':
['baichuan-7b', 'baichuan-13b', 'chatglm2', 'llama2-7b']
})
ckpt_fpath: str = '' # e.g. '/path/to/your/iter_xxx.pth'
eval_human: bool = False # False: eval test_dataset
data_sample: Optional[int] = None
#
lora_target_modules: Optional[List[str]] = None
lora_rank: int = 8
lora_alpha: int = 32
lora_dropout_p: float = 0.1
#
max_new_tokens: int = 512
temperature: float = 0.9
top_k: int = 50
top_p: float = 0.9
def __post_init__(self):
if self.lora_target_modules is None:
if self.model_type in {'baichuan-7b', 'baichuan-13b'}:
self.lora_target_modules = ['W_pack']
elif self.model_type == 'chatglm2':
self.lora_target_modules = ['query_key_value']
elif self.model_type == 'llama2-7b':
self.lora_target_modules = ['q_proj', 'k_proj', 'v_proj']
else:
raise ValueError(f'model_type: {self.model_type}')
#
if not os.path.isfile(self.ckpt_fpath):
raise ValueError('Please enter a valid fpath')
def parse_args() -> Arguments:
args, = HfArgumentParser([Arguments]).parse_args_into_dataclasses()
return args
args = parse_args()
logger.info(args)
select_device(args.device)
# ### Loading Model and Tokenizer
if args.model_type == 'baichuan-7b':
model_dir = snapshot_download('baichuan-inc/baichuan-7B', 'v1.0.5')
model, tokenizer = get_baichuan_model_tokenizer(model_dir)
elif args.model_type == 'baichuan-13b':
model_dir = snapshot_download('baichuan-inc/Baichuan-13B-Base', 'v1.0.2')
model, tokenizer = get_baichuan_model_tokenizer(model_dir)
elif args.model_type == 'chatglm2':
model_dir = snapshot_download('ZhipuAI/chatglm2-6b', 'v1.0.6')
model, tokenizer = get_chatglm2_model_tokenizer(model_dir)
elif args.model_type == 'llama2-7b':
model_dir = snapshot_download('modelscope/Llama-2-7b-ms', 'v1.0.0')
model, tokenizer = get_llama2_model_tokenizer(model_dir)
else:
raise ValueError(f'model_type: {args.model_type}')
# ### Preparing lora
lora_config = LoRAConfig(
replace_modules=args.lora_target_modules,
rank=args.lora_rank,
lora_alpha=args.lora_alpha,
lora_dropout=args.lora_dropout_p,
pretrained_weights=args.ckpt_fpath)
logger.info(f'lora_config: {lora_config}')
Swift.prepare_model(model, lora_config)
model.bfloat16() # Consistent with training
# ### Inference
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generation_config = GenerationConfig(
max_new_tokens=args.max_new_tokens,
temperature=args.temperature,
top_k=args.top_k,
top_p=args.top_p,
do_sample=True,
pad_token_id=tokenizer.eos_token_id)
logger.info(generation_config)
def inference(data: Dict[str, Optional[str]]) -> str:
input_ids = tokenize_function(data, tokenizer)['input_ids']
print(f'[TEST]{tokenizer.decode(input_ids)}', end='')
input_ids = torch.tensor(input_ids)[None].cuda()
attention_mask = torch.ones_like(input_ids)
generate_ids = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
streamer=streamer,
generation_config=generation_config)
output_text = tokenizer.decode(generate_ids[0])
return output_text
if args.eval_human:
while True:
instruction = input('<<< ')
data = {'instruction': instruction, 'input': None, 'output': None}
inference(data)
print('-' * 80)
else:
_, test_dataset = get_alpaca_en_zh_dataset(
None, True, split_seed=42, data_sample=args.data_sample)
mini_test_dataset = test_dataset.select(range(10))
for data in mini_test_dataset:
output = data['output']
data['output'] = None
inference(data)
print()
print(f'[LABELS]{output}')
print('-' * 80)
# input('next[ENTER]')点击查看模型:

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 0
0- 0



 已为社区贡献645条内容
已为社区贡献645条内容

所有评论(0)