环境配置和安装
本文在ModelScope的Notebook的环境(PAI-DSW)配置下运行 (可以单卡运行, 显存要求12G)
服务器连接与环境准备
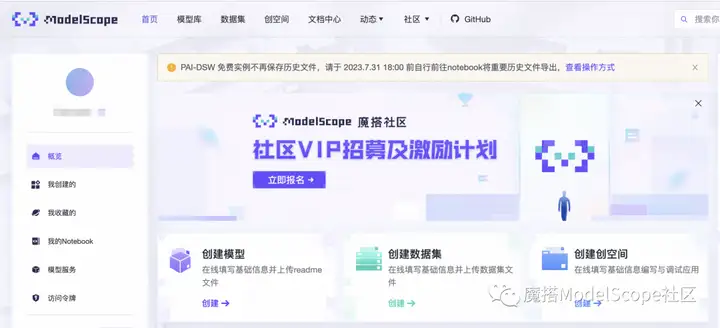
1、进入ModelScope首页:modelscope.cn,进入我的Notebook
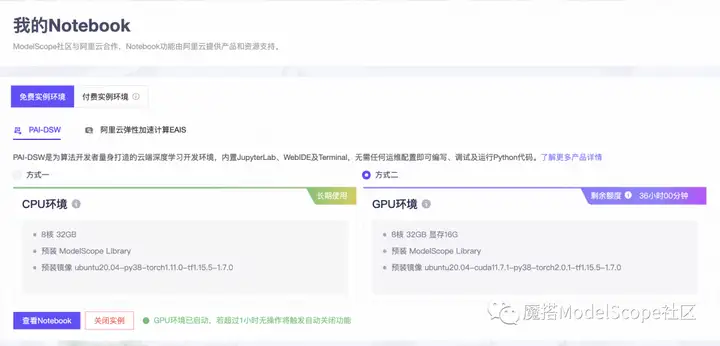
2、选择GPU环境
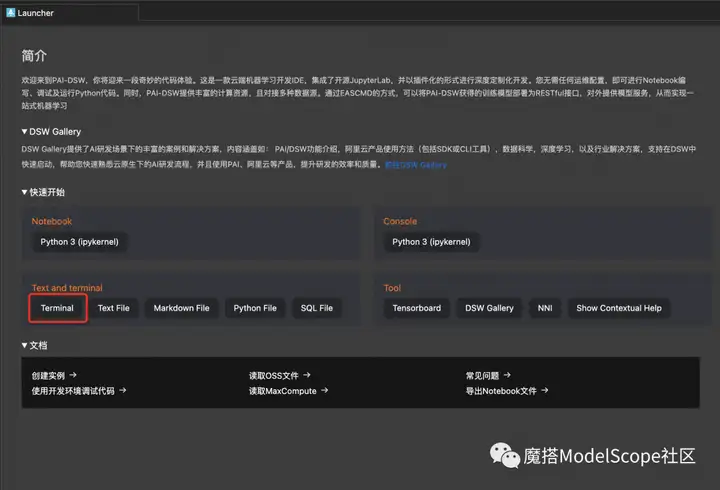
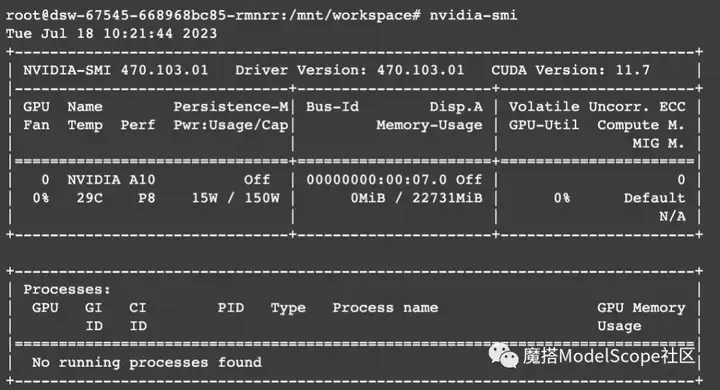
3、进入Terminal,先查看一下GPU的使用情况
git clone ModelScope,运行示例代码
#获取示例代码
git clone https://github.com/modelscope/modelscope.git
cd modelscope/
sh examples/pytorch/stable_diffusion/lora/run_train_lora.sh
使用社区开发者分享的stable diffusion系列模型,本文推荐的是stable-diffusion-v1.5:
模型链接:https://www.modelscope.cn/models/AI-ModelScope/stable-diffusion-v1-5/summary
社区支持直接下载模型的repo
# ### Loading Model and Tokenizer
WORK_DIR = 'runs/stable-diffusion-v1.5'
#使用社区lib下载模型
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('AI-ModelScope/stable-diffusion-v1-5', 'v1.0.9')
stable-diffusion-v1.5推理代码
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
import cv2
pipe = pipeline(task=Tasks.text_to_image_synthesis,
model='AI-ModelScope/stable-diffusion-v1-5',
model_revision='v1.0.9')
prompt = '飞流直下三千尺,油画'
output = pipe({'text': prompt})
cv2.imwrite('result.png', output['output_imgs'][0])
本文使用小柯基的数据集作为微调数据集:https://modelscope.cn/datasets/buptwq/lora-stable-diffusion-finetune/summary.
from modelscope.msdatasets import MsDataset
data = MsDataset.load(
'buptwq/lora-stable-diffusion-finetune',
split='train', # Options: train, test, validation
use_streaming=True
)
print(next(iter(data)))
微调过程分为如下几步:
-
使用ModelScope提供的微调方法构建最终模型
-
使用ModelScope提供的Trainer对模型进行微调
准备配置文件和数据集:
@dataclass(init=False)
class StableDiffusionLoraArguments(TrainingArgs):
prompt: str = field(
default='dog', metadata={
'help': 'The pipeline prompt.',
})
training_args = StableDiffusionLoraArguments(
task='text-to-image-synthesis').parse_cli()
config, args = training_args.to_config()
if os.path.exists(args.train_dataset_name):
# Load local dataset
train_dataset = MsDataset.load(args.train_dataset_name)
validation_dataset = MsDataset.load(args.train_dataset_name)
else:
# Load online dataset
train_dataset = MsDataset.load(
args.train_dataset_name,
split='train',
download_mode=DownloadMode.FORCE_REDOWNLOAD)
validation_dataset = MsDataset.load(
args.train_dataset_name,
split='validation',
download_mode=DownloadMode.FORCE_REDOWNLOAD)
def cfg_modify_fn(cfg):
if args.use_model_config:
cfg.merge_from_dict(config)
else:
cfg = config
cfg.train.lr_scheduler = {
'type': 'LambdaLR',
'lr_lambda': lambda _: 1,
'last_epoch': -1
}
return cfg
开启微调:
kwargs = dict(
model=training_args.model,
model_revision=args.model_revision,
work_dir=training_args.work_dir,
train_dataset=train_dataset,
eval_dataset=validation_dataset,
cfg_modify_fn=cfg_modify_fn)
# build trainer and training
trainer = build_trainer(name=Trainers.lora_diffusion, default_args=kwargs)
trainer.train()
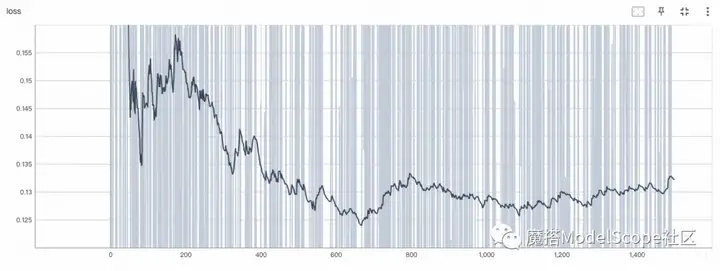
可视化:
Tensorboard 命令: (e.g.)
tensorboard --logdir /home/lora_diffusion/runs/events.out.tfevents.1689651932.dsw-4419-56cf86fcf8-ctp6l.236607.0 --port 6006
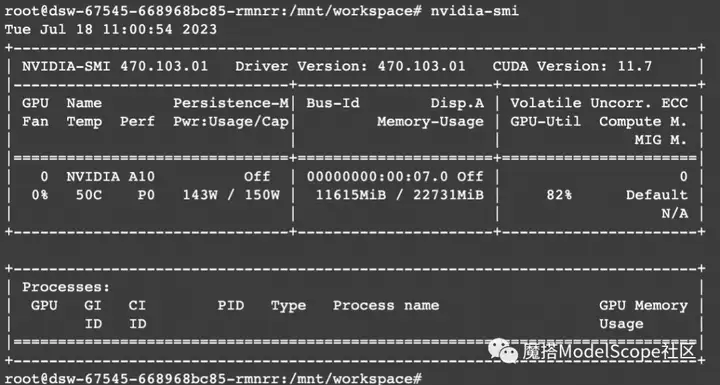
资源消耗
stable-diffusion-v1.5用lora的方式训练的显存占用如下,大约在12G.
# pipeline after training and save result
pipe = pipeline(
task=Tasks.text_to_image_synthesis,
model=training_args.model,
lora_dir=training_args.work_dir + '/output',
model_revision=args.model_revision)
output = pipe({'text': args.prompt})
# visualize the result on ipynb and save it
output
cv2.imwrite('./lora_result.png', output['output_imgs'][0])
训练集:

生成结果:

开源代码链接:
https://github.com/modelscope/modelscope/tree/master/examples/pytorch/stable_diffusion/lora










 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)