ModelScope魔搭社区
科代表划重点!| 魔搭公布AI编程大赛赛题,Agent、AIGC文生图赛道等你来战 科代表划重点!| 魔搭公布AI编程大赛赛题,Agent、AIGC文生图赛道等你来战
今日,魔搭首届AI编程挑战赛赛题正式公布,本次大赛共设置创新应用、模型开发两个赛道,共计四道赛题。赛道一:创新应用赛道(开放赛题) Agent for X,以LLM为核心结合各模态模型拓展创新应用,解决个人生活或产业发展的痛点。赛道二:模型开发赛道(半开放赛题,3个任选其一) 赛题一:文生图任意风格定制挑战 赛题二:多定制概念的文到图生成 赛题三:Special LLM for A
今日,魔搭首届AI编程挑战赛赛题正式公布,本次大赛共设置 创新应用、模型开发 两个赛道,共计四道赛题。
赛道一:创新应用赛道(开放赛题)
Agent for X,以LLM为核心结合各模态模型拓展创新应用,解决个人生活或产业发展的痛点。
赛道二:模型开发赛道(半开放赛题,3个任选其一)
赛题一:文生图任意风格定制挑战
赛题二:多定制概念的文到图生成
赛题三:Special LLM for Agent
赛道一、二评选均为48小时coding+线上3分钟/线下5分钟路演(含PPT讲解+demo展示)。
https://modelscope.cn/aihackathon
天池大赛: https://tianchi.aliyun.com/competition/entrance/532106/information
赛题核心围绕AI应用在Agent、AIGC文生图的创新探索,接下来将重点围绕这两个方面进行相关技术和背景解读,以帮助大家更好地理解本次赛题任务。
目前大多数开源语言 大模型LLM本身功能比较局限,仅单一的QA问答,文生图、文生视频等多模态能力仍较弱。而LLM凭借愈发强大的意图理解和逻辑推理泛化能力,具备利用外部工具/插件完成某个场景的具体任务的潜力。近几个月,HuggingGPT(浙江大学+微软亚洲研究院)、Transformers Agents(HuggingFace官方)、Function Calling(OpenAI)均在验证该项技术让LLM更“多能全能”的可行性。
在模型开发赛道,需基于开源LLM+魔搭社区,搭建一个自主智能体(Agent),通过集成一些小模型到LLM,增强LLM本身缺失的能力(比如,语音、视频、图像),以完成一些复杂的AI任务。魔搭社区(https://modelscope.cn/)目前已经开源开放了 900 多个优质 AI 模型,不乏 SOTA(业界领先)模型。 参赛选手需演示开源LLM 可调用魔搭社区上的2-3个模型API接口。
在创新应用赛道,基于Agent能力,进一步探索在更多行业、应用场景中的商业机会点。
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
https://arxiv.org/pdf/2303.17580.pdf
https://huggingface.co/docs/transformers/transformers_agents
OpenAI:Function Calling 论文
https://openai.com/blog/function-calling-and-other-api-updates
2.1 文生图任意风格定制 关联:赛道二-赛题一
背景介绍 图像的风格化作为一个经典的CV任务,近年来在生成扩散模型提出后有了更新,效果更好的解法。如何通过少量的特定风格的图片训练一个定制化的生成扩散模型需要借助高效的调优方法如Lora等。风格化的生成模型的研究还可以进一步帮助推动可控生成模型的研究和发展,该任务目前已经得到学术界和工业界的关注,如
ControlLora算法,google的dreambooth,styledrop等。
任务解读
在训练阶段,基于给定的风格和风格图对文生图模型进行风格微调,并得到(一个或多个)能够生成规定风格图像的模型;
在测试阶段,给定某种风格图和prompt作为输入,模型将基于prompt生成特定内容
赛题意义及目标 一些例子
推荐学习资料:
ModelScope: 生成扩散模型高效调优(ControlLora)
https://www.modelscope.cn/models/damo/multi-modal_efficient-diffusion-tuning-control-lora/summary
https://dreambooth.github.io/
https://styledrop.github.io/
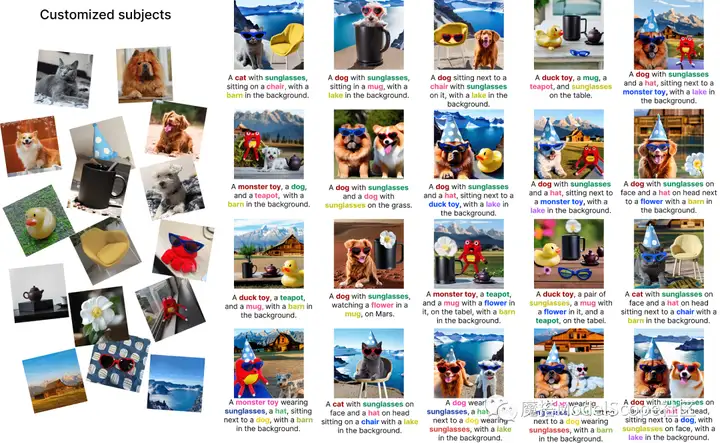
2.2 多定制概念的文到图生成
文本到图像生成最近取得了令人瞩目的进展,而定制某些用户私有概念,使真实世界的物体进行符合文本描述的生成,进一步证明了文生图模型的潜力。而一张图中往往不仅存在单一概念,想象一下,同时定制自己的形象和自己的宠物或是其他任意概念,出现在世界上的任意位置,这是更加有趣的。多概念定制生成,让每个用户能够生成完全由自己所提供概念组成的图片,使文生图更加可控,进一步拓展文生图模型的能力边界。
多概念定制化在一个场景里实现,通过prompt来实现场景塑造,实现速度快、效果优的训练任务。
如下图所示,提供一些多概念的图像(含背景、不同类型的实物主题),通过prompt指令将这些不同概念的图像组合生成各种场景:
技术应用举例:
推荐学习资料:
https://arxiv.org/abs/2208.12242
https://arxiv.org/abs/2208.01618
https://arxiv.org/abs/2212.04488
https://arxiv.org/abs/2303.05125
https://arxiv.org/abs/2305.19327
正如本次大赛的Slogan“We Create,AI Generate” 和 魔搭社区“让模型应用更简单”的宗旨,期待大赛能为广大AI开发者和创业者提供一个展示自我的平台,为AI应用的发展提供更广阔的想象空间和市场信心!来吧,等你来战!
即日起至 6 月25 日,大赛火热报名中(点击下方阅读原文即可报名)
https://modelscope.cn/aihackathon
大家如果对于赛题、赛制还有更多问题或讨论,也可以扫描组队报名二维码,在群中反馈相应问题,@比赛小助手 记录反馈,后续大赛方将持续通过魔搭ModelScope社区发布更多赛事赛题解读,欢迎关注!
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
加入社区














 已为社区贡献662条内容
已为社区贡献662条内容

所有评论(0)