
图像分类基础与实战
理论
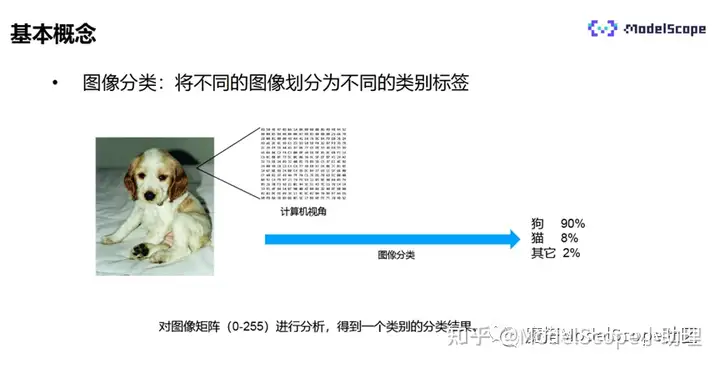
什么是图像分类?
图像分类指将不同图像划分为不同类别标签的过程。从计算机的视角来看,一张图片是一个值从0到255的矩阵,计算机对矩阵进行分析,得到类别结果,即计算机视觉的图像分类。
图像分类是计算机视觉领域最基础的问题,解决的问题是:给定一个图像,正确地给出图像所属类别,是最底层、最基本的任务,常作为其他任务的预处理或与其他任务融合在一起,目标检测也是图像分类的子任务。
可以说,计算机视觉基础模型的发展是图像分类提升任务的发展,做好图像分类任务,关系到后续更高阶的内容。
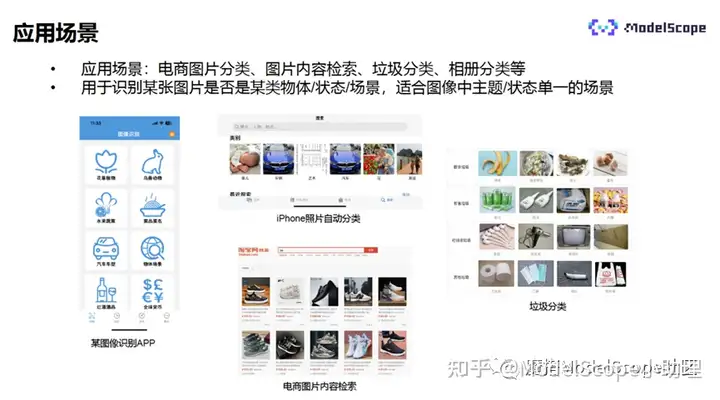
图像分类的应用场景非常丰富,比如图像识别APP,能够识别动物、植物,汽车的车型,水果、蔬菜等;比如iPhone手机上自带的照片自动分类功能;比如电商平台图像内容检索,用户每天可能会上传几万张鞋子图片,后台需要将照片进行分类处理,建立数据库,用户进行图像搜索时,能够实现更精准的搜索;另外,也可用于垃圾分类等场景。
总的来说,图像分类是用于识别某张图片是否为某个物体/状态/场景,适合图像中的主题或状态单一的场景。
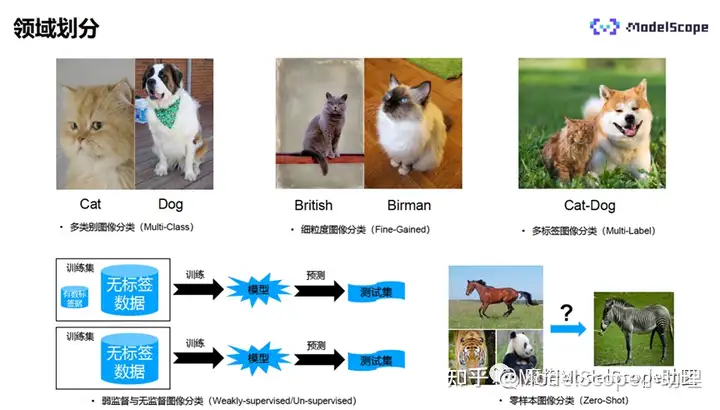
图像的领域划分主要有:
- 多类别图像分类,指每个图像只属于其中一个类别,比如一张图像只能属于猫或只能属于狗。特点为具有较大的类间方差,较小的类内误差,是图像分类中最简单最基本的任务。
- 细粒度图像分类,比如两张图像中都是猫,但属于不同品种的猫,具有相似的外观和特征,类内差异比较大,因此分类难度更高。
- 多标签图像分类:每个图像都拥有两种以上的类别,比如一张图中既有猫也有狗,因此标签类别既是猫也是狗。
- 根据监督信息的不同,分为有监督、弱监督、无监督、自监督等学习:
- 弱监督学习是机器学习中最经典的任务之一,在训练集中只有少数的标签数据,大部分为未标签数据,训练出的模型用来预测的测试集中有可能是有标签的,也有可能是无标签的;
- 无监督图像分类指训练集中都是无标签的数据,训练出的模型用来预测的测试集中都是没有标签的。
- 0样本图像分类:也称为0样本学习模型,能够识别出训练阶段没有出现过的类别,即训练集和测试集在数据的类别上没有交集,是解决类别标签缺失的一种方法。比如图像中训练的数据只有马、老虎和熊猫三个类别的数据,0样本图像分类会通过已有的知识,比如马、老虎与熊猫的描述,对同时拥有马的形状、老虎的斑纹、熊猫的黑白颜色特征的动物识别为斑马。
0样本图像分类指利用类别的高维语义特征来代替样本的低维特征,使得训练出来的模型具有迁移性。比如斑马的高维语义指马的外形、老虎的斑纹和熊猫的颜色,通过高维的语义刻画了斑马类别的特征,从而识别出模型从来没有见过的斑马图像。
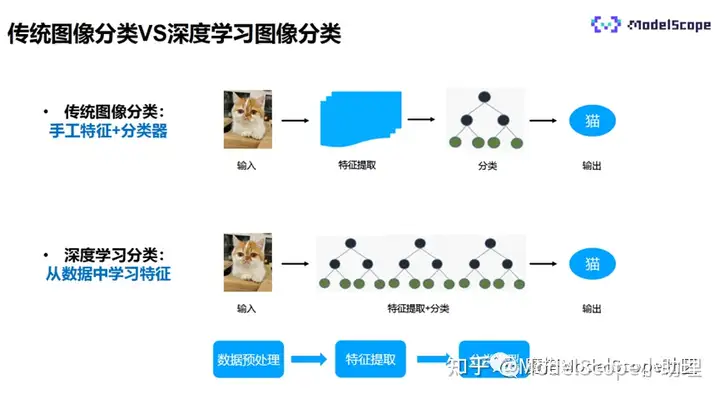
传统图像分类的过程为:输入一张图片,手工提取特征,再使用分类器进行分类,最终输出分类的结果。
深度学习的图像分类过程为:将特征提取和分类器合并在一起,输入一张图像,自动提取特征,输出分类结果,是端到端的识别过程。
传统的图像分类与深度学习的图像分类过程大致一样,都是数据的预处理、特征提取、分类的过程。

上图为图像分类常用的评估指标。
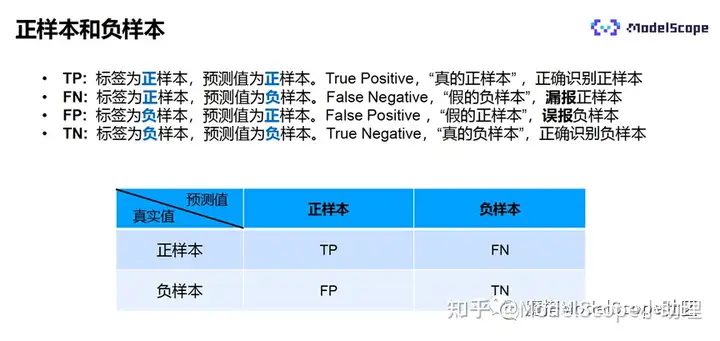
标签值和预测值之间会产生4种组合,分别是:
- TP:标签为正样本,预测也为正样本。说明模型预测正确,是真正的正样本,也说明模型能够正确识别正样本。
- FN:标签为正样本,预测值为负样本,说明预测错误,是假的负样本。属于漏报了正样本。
- FP:标签为负样本,预测值为正样本,说明预测错误,是假的正样本。属于误报了负样本。
- TN:标签为负样本,预测也为负样本,说明模型正确预测了负样本,是真的负样本。

精度(也称为查准率)的定义为:预测为正样本的所有样本中,真正的正样本所占比例,P=TP/(TP+FP)。
召回率(也称为查全率)指预测为正样本的样本占所有正样本的比例,R=TP/(TP+FN)。
F1-score指综合考虑精度和召回率,是两者的调和平均,F1=2*P*R/(P+R)。
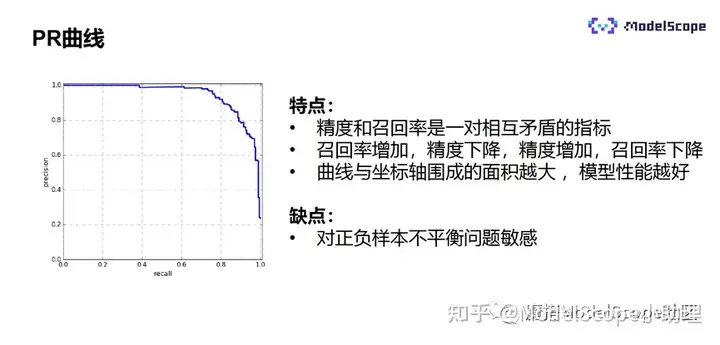
PR曲线是描述精度和召回率关系的曲线,横坐标是召回率,纵坐标是精度。精度和召回率是一对相互矛盾的指标,如果召回率增加,则精度下降;如果精度增加,则召回率下降。曲线和坐标轴围成的面积越大,说明模型的性能越好。但PR曲线对正负样本不均衡较为敏感,正负样本类别差异较大时,PR曲线会变化较严重。

为了解决PR曲线的问题,业内提出了ROC曲线,它涉及到两个基本指标,分别是:
- TPR:指预测的正样本中真实的正样本占所有正样本的比例。
- FPR:指预测的负样本中真实的负样本占所有负样本的比例。
ROC曲线对正负样本的不平衡问题不敏感。ROC曲线下的面积被称为AUC,AUC越大,说明模型的性能越好。ROC表示随机挑选正样本和负样本,分类器对正样本给出的预测值高于负样本的概率。
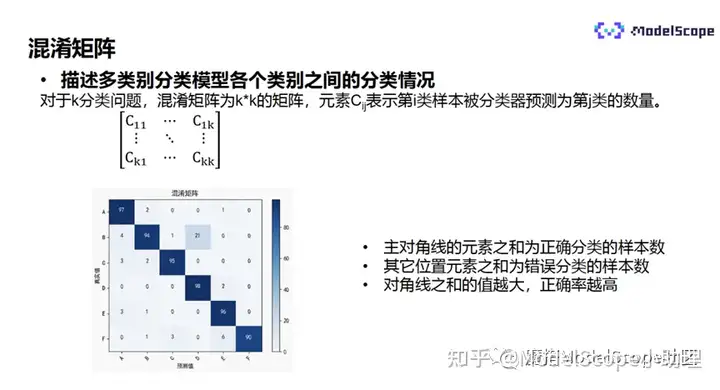
混淆矩阵描述了多类别分类模型各个类别之间的分类情况。
对于k分类问题,混淆矩阵为k*k的矩阵,元素Cij表示第i类样本被分类器预测为第j类的数量。混淆矩阵是分类任务常用的评估指标。对角线上是正确分类的样本数,其他是错误分类的样本数。对对角线上的值越大,说明正确率越高。
混淆矩阵可以非常直观地展示模型的表现情况,尤其是不同类别之间的混淆情况,能够清晰地反映出某样本会以多大概率被分为其他类别,直观地展示哪些类别之间比较容易混淆。
比如上图中的“21”表示标签值的类别为b、却被预测为d类别的样本数,说明模型很容易将类别b识别成类别d,需要针对性地对该种情况进行调整。

上图为图像分类常用的优化指标。

0-1损失指当预测值等于标签值时损失为1,否则损失为0。0-1损失也是非常直观的损失定义,是真实的优化目标。但无法求导,且不连续,无法进行反向传播,只有理论意义。

学术界更常用的是以熵为代表的分类损失。
熵表示热力学系统的无序程度,在信息学中用于表示信息的多少。不确定性越大,概率越低,则表示携带的信息越多,熵也越高。
常用的分类损失是交叉熵,用于衡量两个概率分布之间的相似性。假设有n个样本、m个类别,yij表示第i个样本,属于第j类的标签,f(Xij)表示第i个样本预测为第j类的概率。
可以将yij看作标签的概率分布,f(Xij)看作分类模型预测值的概率分布,交叉熵衡量主要用于两个概率分布之间的相似程度。
Softmax损失指:当f(Xij)为Softmax函数时,Softmax损失是交叉熵损失的特例。

KL散度通常用来估计两个分布之间的相似性。假设有两个分布p和q,则KL散度等于p和q的交叉熵加上p和p的交叉熵的负值。如果p是一个已知的分布,则-l(p,p)是一个常数,此时的KL散度与交叉熵l(p,q)只相差一个常数,因此它们是等价的。

上图为经典的开源数据集。其中PASCAL数据集常用于目标检测,也可以用来做图像的分类。ImageNet是图像分类最重要的数据集,很多的论文都将其作为训练后的测试基准。
图像分类CNN模型
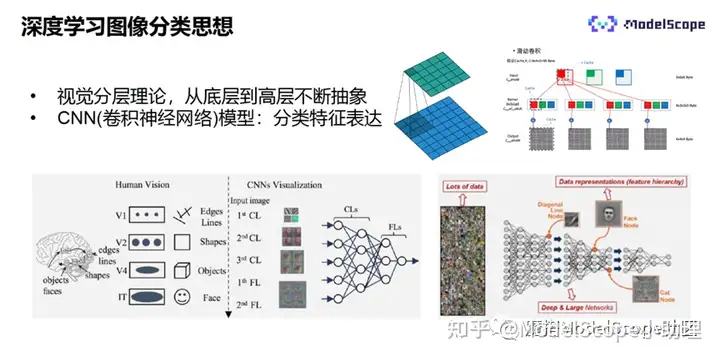
CNN指卷积神经网络,借鉴人类视觉的基本原理,人类视觉具有分层的机制,与计算机的视觉相比,人类视觉从V1到V2到V4,抽象层次依次提升。人类观察一个物品,会先看到的边缘的线条,再看到的形状,再看到物体,最后抽象为某个事物。
CNN是由很多网络堆叠而成的模型,从图像输入到最后得到可以完成模式识别的高层特征,也是逐层抽象的过程。
在浅层,算子提取到的是浅层的特征,比如边缘特征和颜色;随着模型的加深,会逐渐提取到更深层的、抽象的特征。其中特征提取使用的便是神经网络,其核心为卷积的操作。
上图为单个卷积的示意图像。卷积的本质为:在输入特征图像上通过滑动窗口的方式进行乘加的求和。右上角是卷积层的示意图,假设输入为3个通道的特征图像,通过4*3个卷积核的权重,每一个卷积核都与输入的特征进行卷积,最终输出4个特征图像,以上便是一层的卷积。
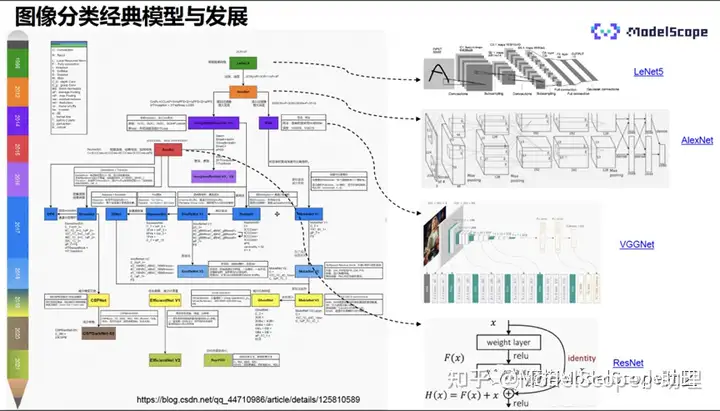
上图展示了图像分类的经典CNN模型与发展历程。
CNN模型的开山之作是LeNet5,具有三个卷积层,两个池化层,两个全连接层,并且增加了非线性的映射,输入大小为32*32,经过一个卷积层、上采样、卷积层、上采样、卷积层,最后经过两个全连接层,输出分类的结果。该模型较为简单,深度只有3层。
深度学习真正爆发在于2012年提出的AlexNet模型网模型,它取得了ImageNet分类比赛的冠军,且分类准确率远远超过使用传统方法得到的分类结果,是真正意义上的现代神经网络。因此,2012年也成为深度学习的元年。
AlexNet共有5个卷积层,3个全连接层,同时使用了一些工程上的技巧,比如利使用多GPU的训练,利用两个GPU并行地对特征进行分别的训练,可以尽可能地使用更多的特征图像,并且能够减少计算量。另外,AlexNet第一次使用了ReLU的激活函数,加快了模型的收敛;还使用了LRN的归一化,增强了模型的泛化能力;引用了dropout正则,防止模型的过拟合和收敛;使用了数据增强,比如裁剪、反转等,提高了模型的泛化能力。且上述技巧到目前为止依然在使用,因此,它是真正意义上的现代的神经网络。
2014年,业内提出了VGG,相比AlexNet,它堆叠了更多的卷积层和池化层,并且增加了模型深度。首次使用了3*3的小卷积核,此前多为5*5或7*7的大卷积核,且第一次提出了1*1的小卷积核,网络更简洁,深度达到19层。
2015年,业内提出了具有划时代意义的模型ResNet(深度残差网络)。此前,网络层之间直接通过x来求得输出F(x),但是ResNet从输入x到输出多了一个连接,网络层建模输入和输出的差值,称为残差,输出变为输入与残差之和,通过该方式解决了网络深度增加导致梯度消失的问题,将神经网络加得更深,进一步增强了网络的表达能力。ResNet可以将网络增加至1000+层。
后续,基于ResNet发展出了更高精度、高效的模型结构,包括移动端上的高效模型比如MobelNet系列等。
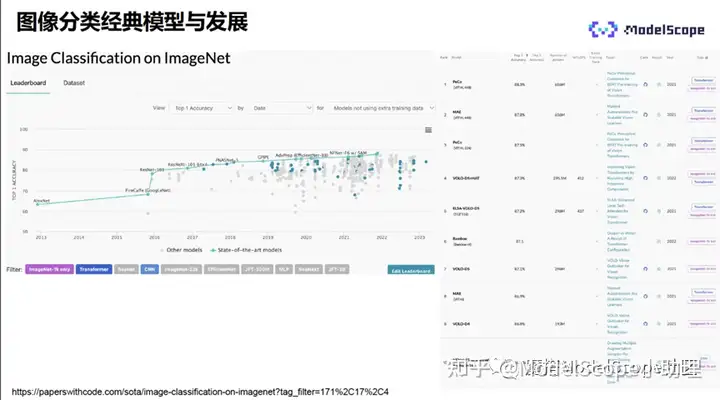
上图左侧展示了当前所有分类模型在ImageNet上的分类性能情况。从AlexNet开始,图像分类的性能逐年不断提升,且每年都有大量模型结构被提出,特别是近几年,SOTA模型一直在刷新分类的精度。
右侧展示了当前TOP10的模型。可以看出,当前TOP10的模型已经不是CNN模型,而是Transformer模型。这也意味着Transformer是当前模型的新趋势。
图像分类Transformer模型
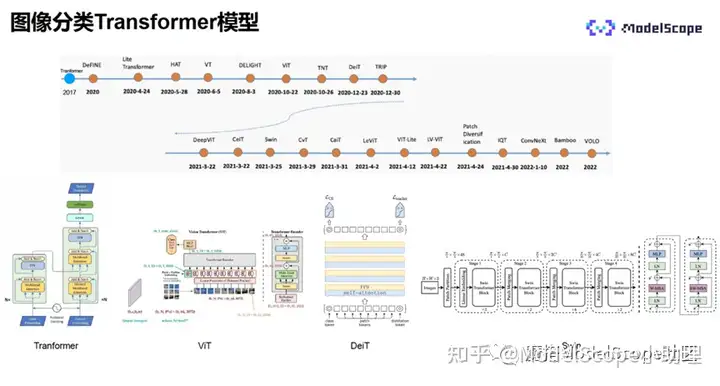
2017年,谷歌在自然语言领域中首次提出了Transformer模型。2020年,Transformer开始在自研语言领域中广泛应用。2020年10月,ViT模型被提出,该模型是自然语言领域中的Transformer在计算机视觉上的第一次应用。
在此之后,业界基于Transformer提出了许多不同的模型结构,也不断地刷新着模型的精度。
Transformer模型中,最为核心的是自注意力。
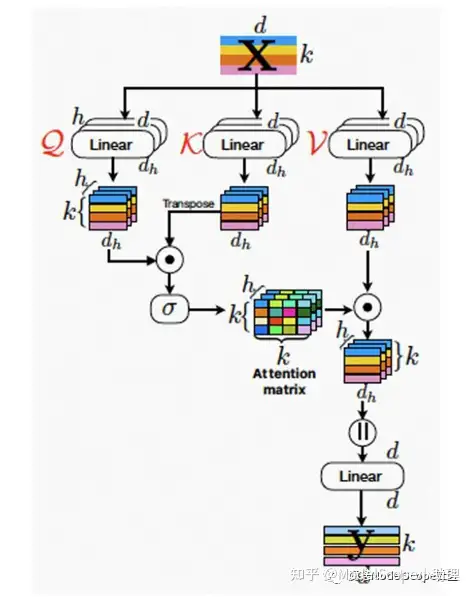

自注意力的计算流程和原理如上图所示:
输入向量后,经过线性变换(如右图公式),输出Q、K、V,K和V矩阵做内积运算得到注意力。注意力除以,d指输入向量的维度。q的矩阵乘以k的矩阵的值大小与维度成正比,为了使训练更稳定,因此此处除以。加上位置编码之后求softmax。得到的结果再与v做内积计算,得到自注意力。
上述流程可以类比于查询数据库的过程,q是查询的向量,k是键值,v是要查询的数据。q矩阵和k矩阵做内积,衡量两个矩阵之间的相似程度。使用查询向量与键值做对比,对比的结果即数据的索引,通过索引查找数据所在位置。
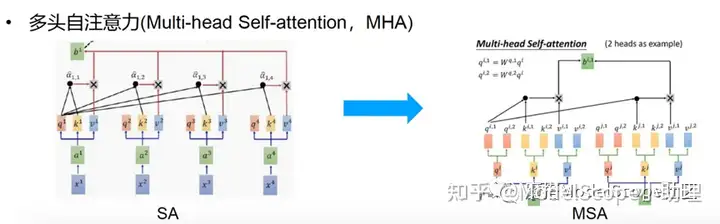
上图左侧为自注意力的示意图像,每个输入q和k做内积之后乘以v得到自助力的输出。
右侧为多头自注意力示意图,将q、k和v分为多个头,本示例分为两个头,每个头的q、k和v分别做自注意力的计算,最后得到多头自注意力的输出。相比自注意力,多头自注意力的表达能力更强,因此目前一般使用多头注意力作为自注意力的计算。
下文将介绍几个比较经典的Transformer模型。
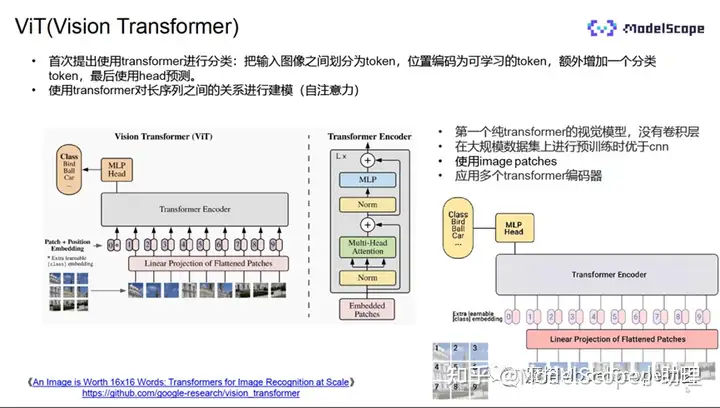
Vit(Vision Transformer)模型,首次提出使用Transformer进行分类,是第一个纯Transformer的视觉模型,没有任何卷积,在大规模数据集上进行训练的结果优于之前的所有CNN。
Transformer主要在自然语言领域中应用的,要求输入序列,那么ViT如何将图像转换为序列?
采用的方式为:将输入图像分块,每一块视为一个向量,所有向量合并成为序列,经过线性映射之后,加入分类的token和位置编码,经过Transformer encoder编码,再使用分类的token和NLP进行分类。NLP是两个全连接层,即分类器。Transformer encode由L个基本单元堆叠而成,基本单元中输入的token首先经过nomal layer,再经过多头的注意力计算,最后经由NLP输出。模型过程较简洁。
ViT的缺点在于,必须使用较大规模的数据集才能得到较好的结果。上图示例中使用了3亿张图像,使用谷歌的8核TPU训练了一个月才得到结果,成本较高。

为了解决上述缺陷,业界推出了DeiT模型,它是一种训练策略,使用蒸馏的方式,帮助Transformer更快地学习到局部的信息,大幅降低了ViT训练的数据量,仅需140多万张数据集,使用8卡的GPU训练2-3天即可。
训练过程与ViT大致相似,区别在于额外加入了蒸馏的token,计算loss时,蒸馏的token和teacher模型的预测标签计算蒸馏的交叉熵损失,再加上分类的交叉熵损失作为模型的总损失。
总的来说,DeiT模型大幅减少了训练的数据量和训练成本。
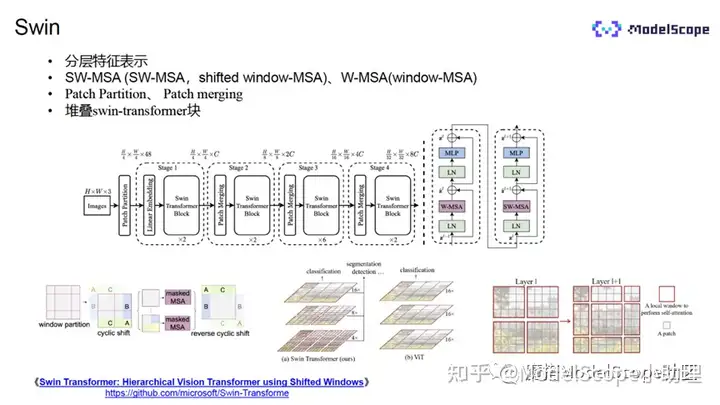
ViT的模型的计算量很大,复杂度为输入分辨率的二次方。在ViT模的模型中,会将输入划分为多个patch(小的窗口)。在进行多头自注意力计算时,任何patch都要与其他所有的patch做自注意力的计算。因此当patch的大小固定时,计算量便与图片分辨率的平方成正比,计算量非常大。
而Swin中采用了W-MSA的方式。首先,将输入的图像分为多个窗口,不同的窗口包含相同数量的patch,比如这相的patch,只针对window里面的patch进行多头的注意力计算。图片大小增加时,计算量只成线性的增长。
然而,该种方式下,同一window之间的patch可以相互交互,但是不同window之间的信息无法交互,会降低模型的性能。
为了解决上述问题,学术界推出了滑动窗口(shifted window)的方式,将窗口进行偏移。
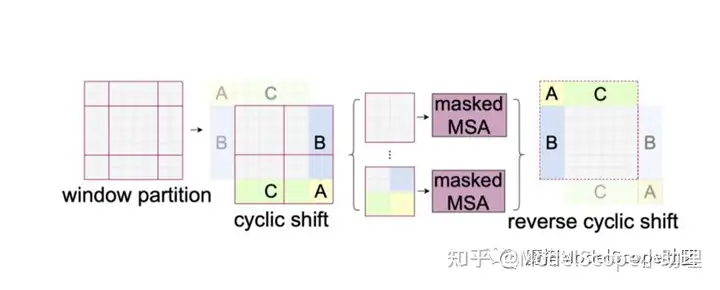
但偏移之后会出现空缺,需要采用了cyclic shift的方法进行填补,比如将左二图中浅色ABC部分的数据迁移到了对应的深色ABC区域,然后对不同区域进行以掩码计算,得到新的窗口,再做自注意力的计算。通过这种方式提高了计算速度,也提高了模型的性能。
实践

本次实战将演示在私有数据集上对模型进行微调训练,生产定制化模型的过程。
详细教程请点击:
https://blog.csdn.net/tantanweiwei/article/details/130139458
首先,进入ModelScope官网,登录。
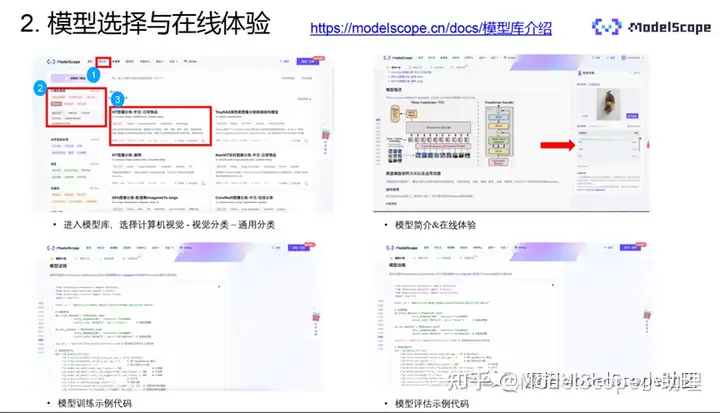
搜索ViT图像分类-中文-日常物品,进入模型详细页面。
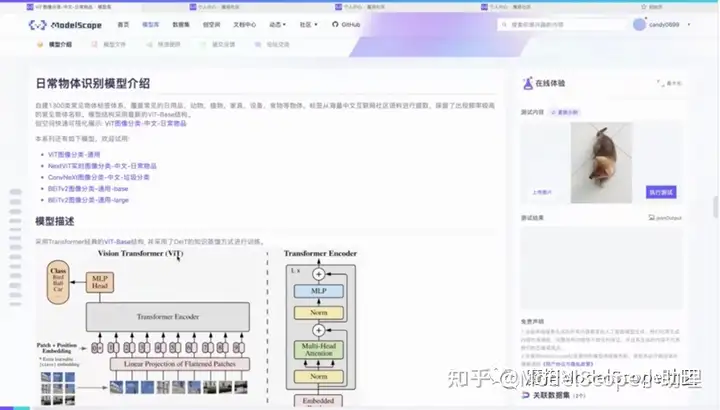
详情页包含模型的基本介绍。自建1300类常见物体标签体系,覆盖常见的日用品,动物,植物,家具,设备,食物等物体,标签从海量中文互联网社区语料进行提取,保留了出现频率较高的常见物体名称。模型结构采用最新的ViT-Base结构。
另外,也可以在官网的文档中心-模型详解-计算机视觉模型中找到对应的模型文档。
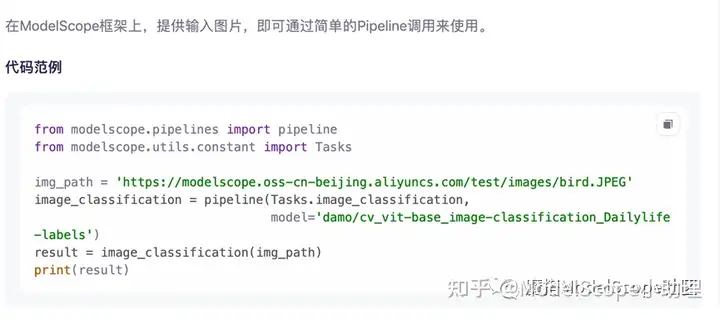
推理使用的示例代码非常简单,除了引用依赖包,仅需两行代码即可调用模型进行分类任务的测试。
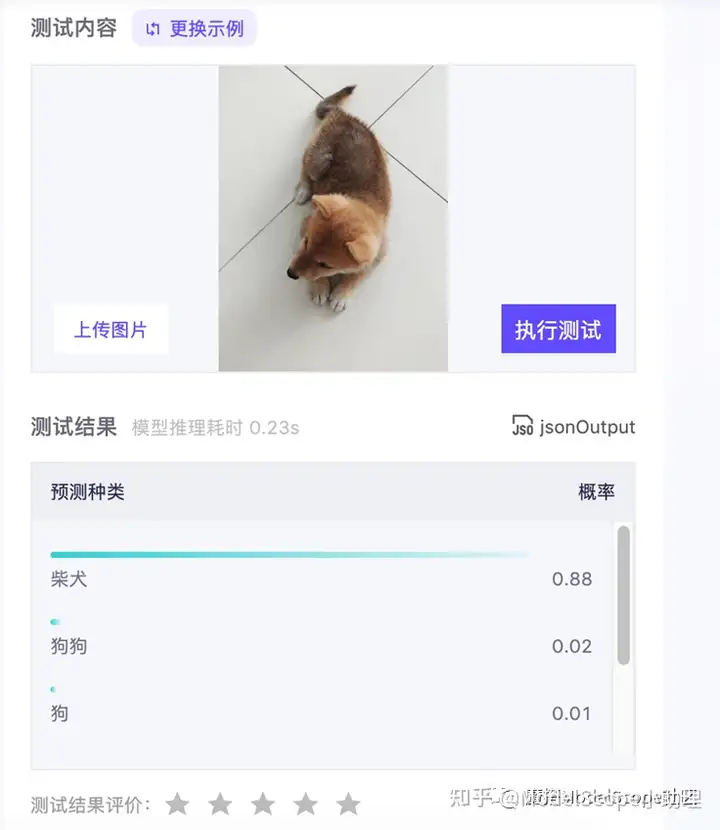
页面右上方提供了在线模型的体验,可视化了推理的过程。可以上传图片或直接使用示例的图片进行测试。结果如上图所示,排在结果第一位的是柴犬,后面数字表示概率。

另外,还可以在创空间进行分类结果的可视化体验。点击上方创空间快速可视化展示即可体验。
创空间界面如上图所示。上传图片即可体验。
点击右上角NoteBook快速开发,选择CPU或GPU环境启动。
点击笔记本,创建python文件。
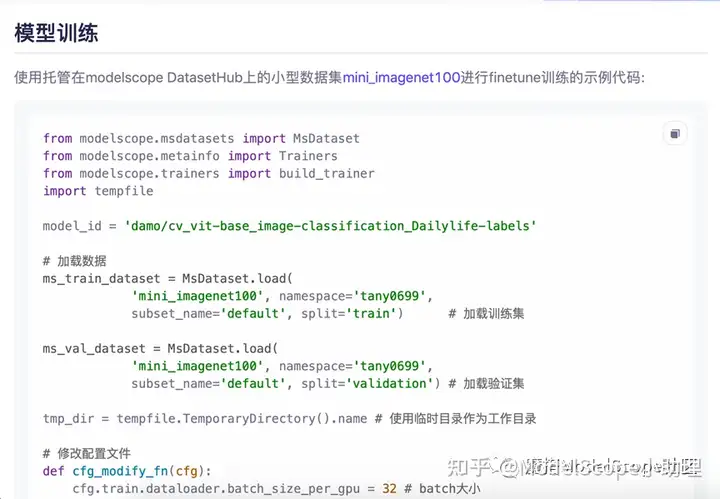
返回模型页,复制模型训练相关代码
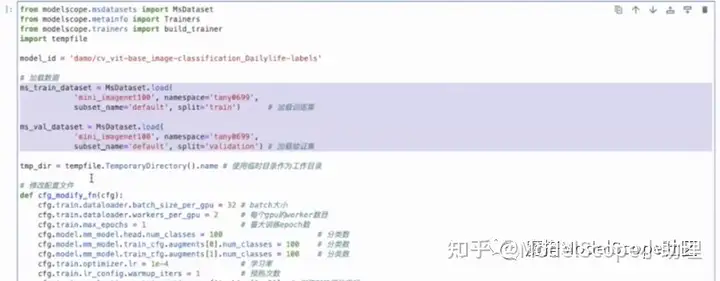
在详情页复制数据集加载相关代码,替换上图选中的部分代码。

修改配置参数,将分类的类别数改为14。

将工作目录修改为当前的根目录下的vit_base_flower目录。
开始进行训练。

训练完成的结果显示如上图,topone的精度是87.75,TOP5的精度是98.97。
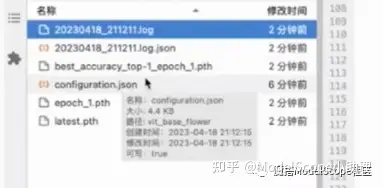
训练完成后的工作目录如上图所示。log文件中保存了训练的日志,configuration文件中保存了配置相关信息。best_accuracy_top-1_epoch_1中保存了训练集上精度最好的模型权重,为了后续对模型进行评估,需要将该文件重命名为pytorch_model_pt。
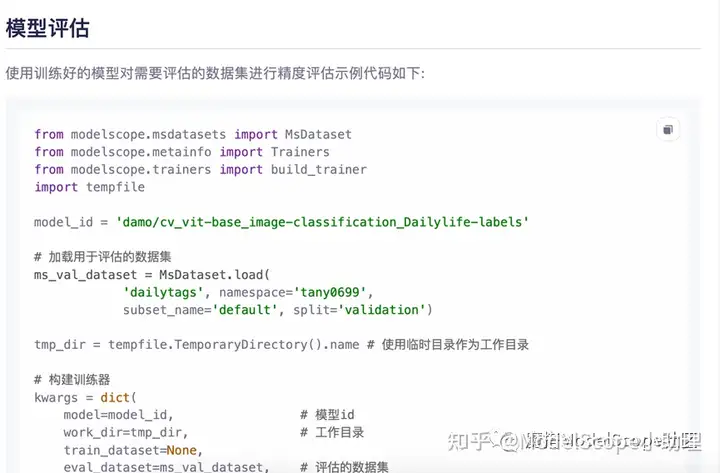
返回模型详情页,复制模型评估相关代码。

复制详情页中的数据集加载相关代码(上图选中部分),替换原代码中“加载用于评估的数据集”部分代码,重新加载数据的校验集。
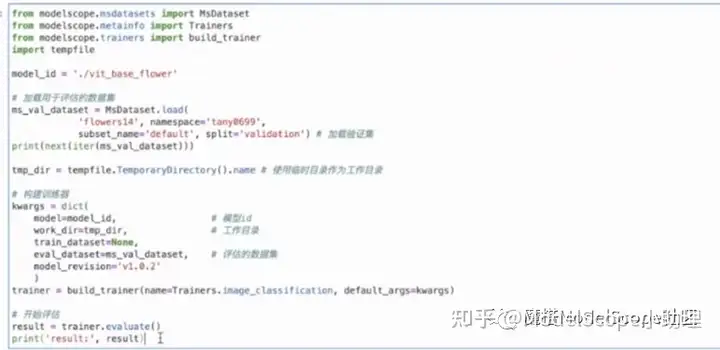
将model_id修改为工作目录下的vit_base_flower。本次训练的只进行校验,因此训练的数据集设为空,只需填入使用评估的数据集。
执行代码,开始进行评估。
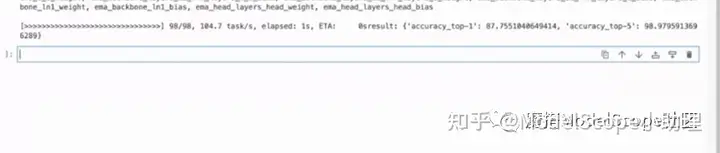
结果如上图,与训练之后的评估完全一直,TOP1是87.75,TOP5是98.97,可正常用。
接下来进行模型推理。
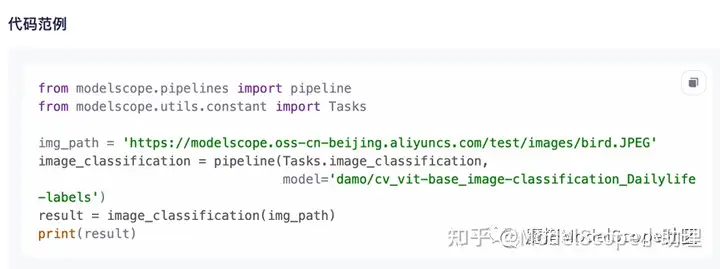
复制详情页代码。
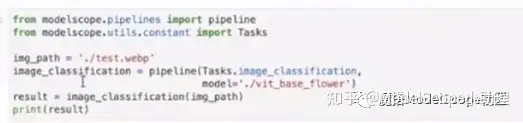
在工作目录下上传一张图片,修改图片路径和模型路径如上图。执行代码。

结果显示如上图,TOP1是向日葵。但top5的概率较为接近,说明训练不够充分。实际训练时,可以将epoch调大,学习率调小,以得到更优化的结果。
在模型页面右上角点击创建创空间,填写相关信息,创建创空间。
创建后的页面如上图所示。
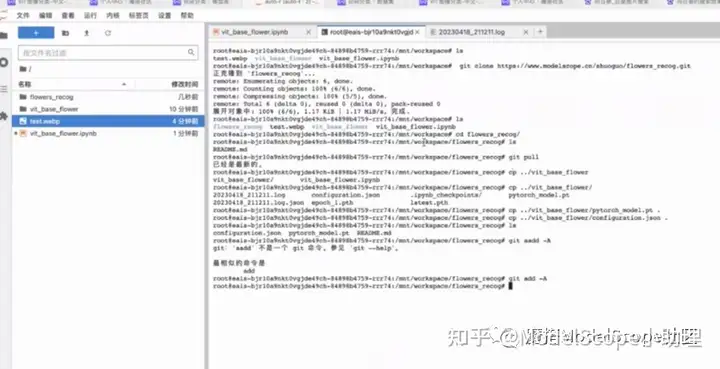
复制上图中git clone代码,将前面训练好的权重与配置文件拷贝过来,上传到的modelscode模型的空间中。
上传完成后页面如上图。
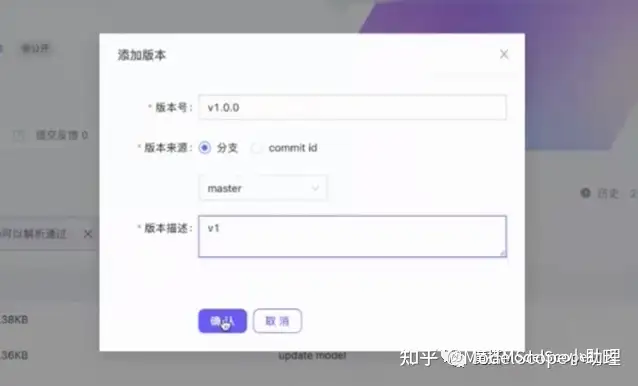
点击右上角,添加版本号,即可使用模型。
接下来测试发布到ModelScope上的模型是否可用。

复制模型页面下的代码并对其进行修改。
代码中的模型ID修改为创建的模型ID(页面左上角),图片地址修改为根目录下的测试图片。
创建创空间时选择了非公开模型,因此此处需要对模型进行授权,代码如下:
from modelscope.hub.api import HubApi
#YOUR_ACCESS_TOKEN =
'请从ModelScope个人中心->访问令牌获取’
#api= HubApi()
#api.login(YOUR_ACCESS_TOKEN)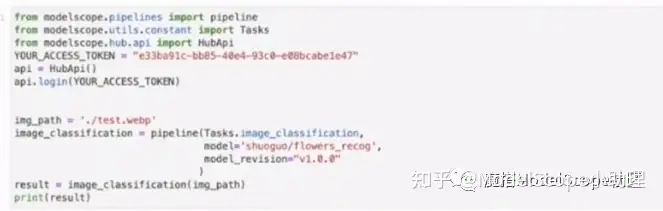
另外,因为设置了模型的版本,需要重新写版本。最终修改后的代码如上图。

结果显示如上图,证明模型可以正常使用。

回到创空间,打开空间文件下的readme文件,可以直接复制其他模型的readme文件(如上图右侧所示)进行修改后使用。
需要修改模型ID,在创建的模型名称下方复制即可。entry_file指文件入口,本示例中不使用GPU进行推理,因此是GPU为0。

执行代码也可以从其他创空间模型中复制后进行修改使用。新建一个app.py文件,将代码粘贴至文件中。首先需要修改授权码。回调函数为interface,输入的类型为图片,输出为label类型,显示top5的结果,设置默认测试图片的地址。
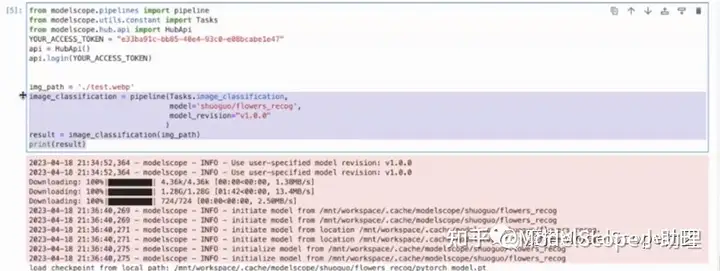
复制前文的推理代码并进行修改。
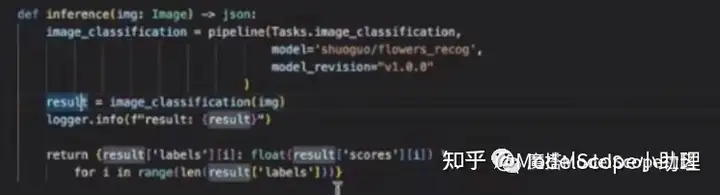
输入的类型是图像,因此需要将 result=image_classification()内的参数修改为img。
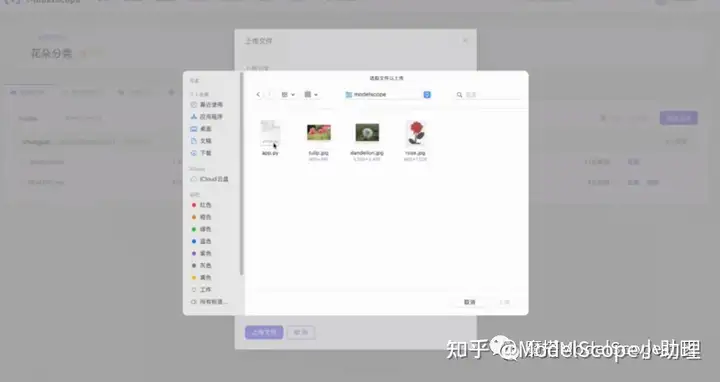
在空间文件里点击上传文件,将app.py文件上传至创空间。
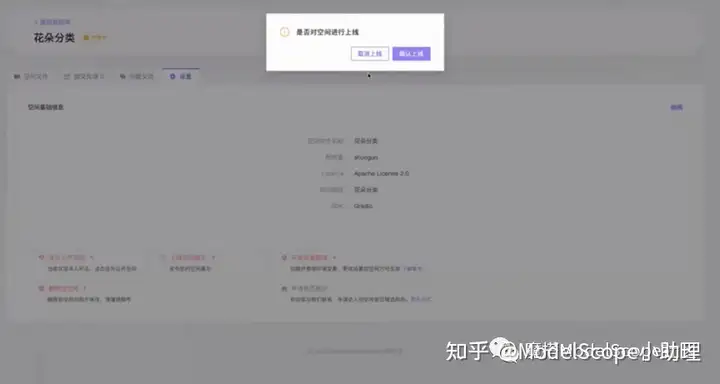
在设置里点击上线创空间。
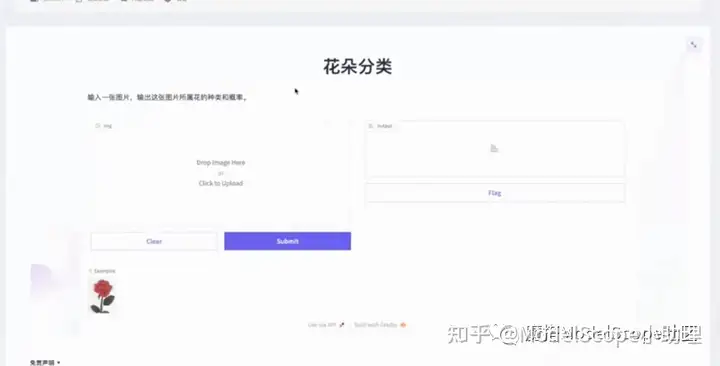
至此,创空间搭建完毕。页面如上图所示。
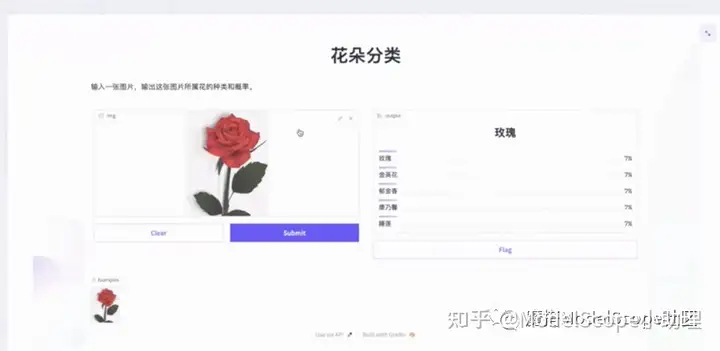
点击图片,提交后会显示结果。

其他模型的训练流程与本文示例基本一致,主要区别在于使用的数据集不同。所有数据、模型、代码均已开源,欢迎进入Modelscope官网搜索使用。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献645条内容
已为社区贡献645条内容

所有评论(0)