

前言
在前三篇文章中,我们建立了GPT模型微调的环境,并使用微调让GPT学习了新知识,同时了解了ChatGPT中的Prompt技巧与设计。在本章中,我们将利用本地数据库,构建一个基于本地知识库的GPT问答机器人,而非使用Langchain。
附录:
《打造个性化离线ChatGPT - GPT模型微调实战指南》
《微调的小型模型在专业领域性能勉强接近GPT-3.5 - GPT 模型微调实战指南(二)》
《ChatGPT中的Prompt技巧与设计 - GPT 模型微调实战指南(三)》
环境准备
由于modelscope社区正在举办活动,新注册用户可以免费获得100小时的GPU算力,因此我们将使用modelscope提供的环境来进行本次实验。这将为大家提供更方便的测试和体验。
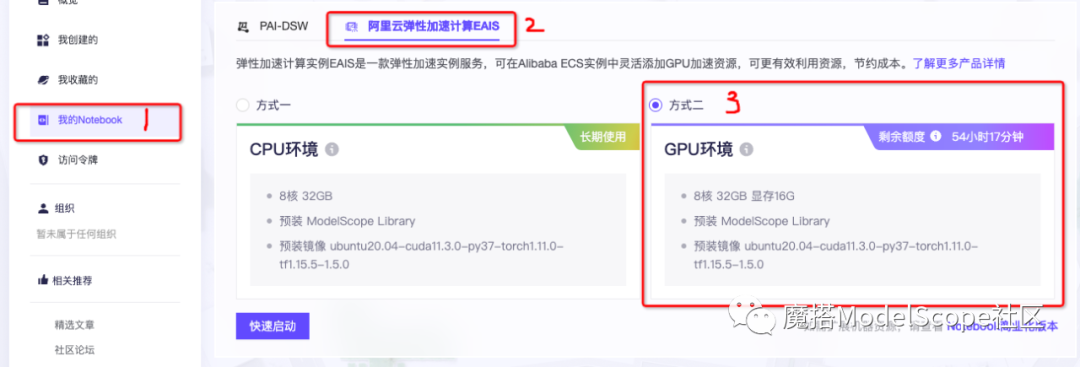
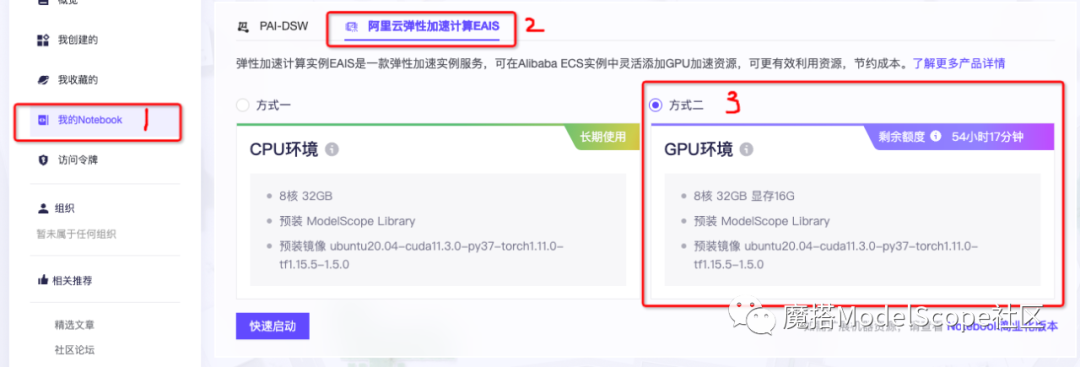
1、打开 https://modelscope.cn/my/mynotebook
2、依次点击 我的Notebook→阿里云弹性加速计算EAIS→GPU环境→快速启动。
3、稍等一会,即可进入界面。
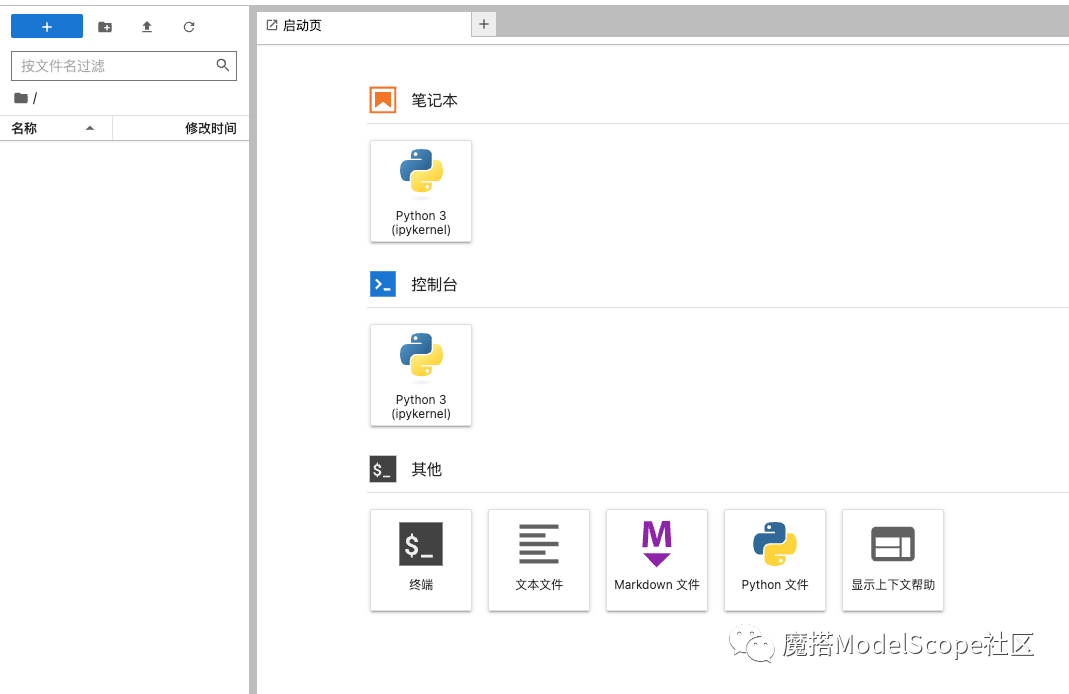
至此,我们的基础环境准备好了。
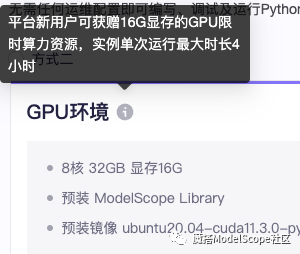
注意,该环境乃测试环境,使用的时间和最大时长有限制任何数据记得及时做好备份!!!
知识库结构
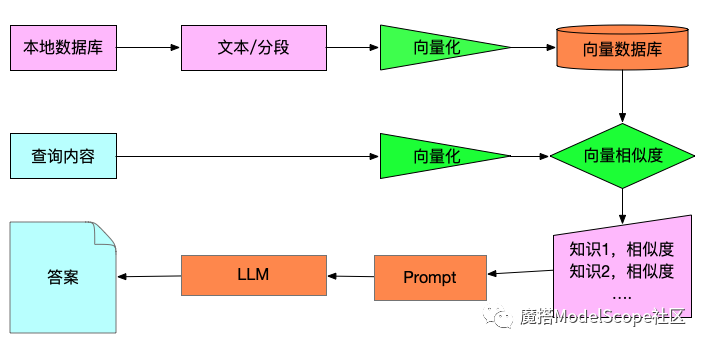
由于我们希望在后期可以进行自定义定制,并且架构相对简单,因此本文决定不使用Langchain,而是准备自己实现整个流程。
主要涉及Prompt编写、向量库、向量算法以及文本切割。下面将详细介绍如何实现的过程。
Prompt编写
根据吴恩达在《ChatGPT中的Prompt技巧与设计》课程中介绍的范式,我们经过多次尝试后,决定采用该模板来构建的问答的Prompt。
请根据上下文来回答问题,
如果上下文的信息无法回答问题,请回答"我不知道"。
上下文:
"""
{根据用户输入的问题,从向量数据库查询的结果。一行一个}
"""
问题:"""{用户输入的问题}"""
回答:为了让LLM认为从向量数据库查询的结果是一句完整的话,我在每个结果的末尾添加一个了句号。当然,这个模板仍然无法完全约束模型的生成结果,仍可能会存在编造结果的情况。
我尝试了调整模型的 top_p 和 temperature 这两个参数,但是并没有消除这种情况的出现。要达到更好的效果,还是需要进行微调,并限制模型的思考范围和输出结果的格式。
向量数据库的选型
在众多的向量库类型中,我选择了Chroma向量库,原因如下:
-
可以本地部署,不需要连接到外部服务,保证了数据的隐私性。
-
结构简单,易于理解和魔改。
-
可以自定义实现量化算法,从而优化检索速度和准确度。
-
数据可以持久化,便于长期存储和管理。
因此,我们选择了Chroma向量库作为本次实验的数据库。
详细文档 https://docs.trychroma.com/
注:默认Chroma会收集匿名使用的信息,如何关闭请查阅https://docs.trychroma.com/telemetry。
文本的分割
在导入文本到向量库之前,我们可以参考Langchain是如何对文本分割的,以便更好地理解该过程。
https://python.langchain.com/en/latest/modules/chains/index_examples/summarize.html
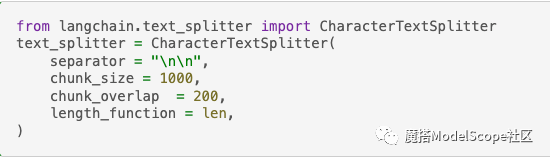
我们可以看到,默认使用的文本分割器是 CharacterTextSplitter。该文本分割器需要一个字符列表separator,它会尝试根据第一个字符进行分割,但如果任何块太大,则会转移到下一个字符。默认情况下,它会尝试拆分的字符是["\n\n", "\n", " ", ""]。
除了控制separator可以拆分哪些字符外,我还可以通过以下参数来控制文本分割器的行为:
-
length_function:用于计算块的长度的函数。默认情况下,只计算字符数量,但通常会传递一个标记计数器。
-
chunk_size:块的最大大小(由长度函数测量)。
-
chunk_overlap:块之间的最大重叠。保持一定的连续性(例如滑动窗口)可以很好地维护一些重叠。
除了使用文本分割器对文本进行分割外,langchain还介绍了其他几种方式来对大段文本进行切割。
https://docs.langchain.com/docs/components/chains/index_related_chains
stuff: Stuffing 方法是最简单的方法,只需将所有相关数据作为上下文放入提示中,以传递给语言模型。在 LangChain 中实现为 StuffDocumentsChain。
优点:只需要向 LLM 进行一次调用。在生成文本时,LLM 可以一次性访问所有数据。
缺点:大多数 LLM 都有一个上下文长度,对于大型文档(或许多文档),这种方法将不起作用,因为它会导致提示大于上下文长度。
map_reduce: 这种方法涉及对每个数据块运行初始提示(对于摘要任务,这可能是该块的摘要;对于问答任务,这可能是仅基于该块的答案)。然后,运行一个不同的提示来组合所有初始输出。这在 LangChain 中实现为 MapReduceDocumentsChain。
优点:可扩展到比 StuffDocumentsChain 更大的文档(和更多的文档)。对单个文档的 LLM 调用是独立的,因此可以并行化。
缺点:需要比 StuffDocumentsChain 更多的 LLM 调用。在最终的合并调用过程中会丢失一些信息。
refine: 这种方法涉及在第一个数据块上运行初始提示,生成一些输出。对于其余文档,将传递该输出以及下一个文档,并要求LLM基于新文档来改进输出。
优点:可以提取更相关的上下文,比 MapReduceDocumentsChain 的信息丢失可能更少。
缺点:需要比 StuffDocumentsChain 更多的 LLM 调用。这些调用也不是独立的,意味着不能像 MapReduceDocumentsChain 那样并行化。文档的排序也可能存在一些潜在的依赖关系。‘
Map-rerank: 这种方法涉及在每个数据块上运行初始提示,它不仅尝试完成任务,还为其答案的确定性打分。然后根据这个得分对响应进行排序,并返回最高得分。
优点:类似于 MapReduceDocumentsChain。与 MapReduceDocumentsChain 相比,需要较少的调用。
缺点:不能在文档之间合并信息。这意味着当你期望在单个文档中有单一简单的答案时,它最有用。
本次用来做测试的是西游记,这种大段的文本通过map_reduce或者refine 的效果会更好一些,因为是小说,有上下文的含义。不过这里为了方便展 , 直接按照 100的长度进行分割打入数据库了。
不同的业务场景需要根据实际的需求来选择不同的方式进行分割文本,这样才可以达到比较好的效果。
向量算法的选型
完成了文本导入后,可以尝试测试一下效果了。
Chroma向量库中原生的embeddings效果不理想,使用的是 all-MiniLM-L6-v2 算法来进行向量嵌入。这个算法来自于 Sentence Transformers 库。Sentence Transformers 的还有其他算法:
|
Model |
Performance Semantic Search (6 Datasets) |
Queries (GPU / CPU) per sec. |
|
multi-qa-MiniLM-L6-dot-v1 |
49.19 |
18,000 / 750 |
|
multi-qa-distilbert-dot-v1 |
52.51 |
7,000 / 350 |
|
multi-qa-mpnet-base-dot-v1 |
57.60 |
4,000 / 170 |
拿西游记的全文向量化导入后,查询 东胜神洲(孙悟空的老家花果山) 相关的信息,发现基本无法命中结果。

于是重新修改向量的算法,看了一下,如果要自定义向量算法,只需要按照以下的数据导入到库里就行。
collection.add(
文章内容:documents=["doc1", "doc2", "doc3", ...],
向量内容:embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
原始数据:metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],
ID:ids=["id1", "id2", "id3", ...]
)我们在魔搭ModelScope社区。
在https://modelscope.cn/models/damo/nlp_corom_sentence-embedding_chinese-base/summary上查看有关该模型的详细信息 。 在不同的领域还可以选择不同的的CoROM模型。
我们对文本分割器和向量库进行了修改后,重新导入了文本,并进行了查询,这次终于成功地获得了有关东胜神洲的相关信息。

最终效果
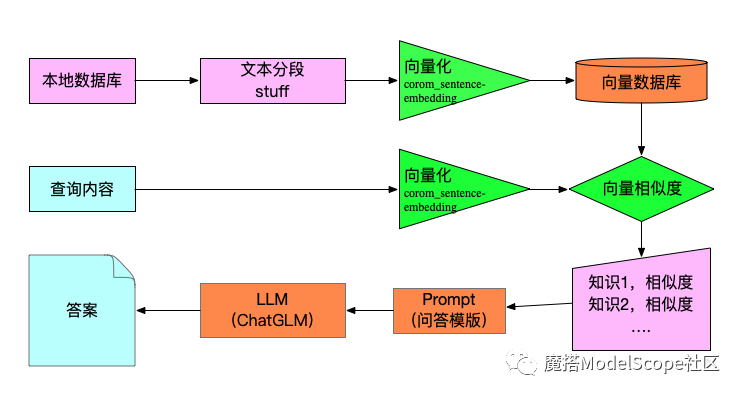
把模型+Prompt+向量算法+向量数据库组合起来后,选用的技术和框架如下图所示:
问题1:

问题2:

总结
用手工编写的方式实现了完整基于个人知识库的QA Bot,采用手工编写的方式。相比于langchain,这种方法具有以下优点:
-
可以通过SaaS服务对每个部分进行加速,
-
每个部分都可以轻松地进行自定义修改。通过简单修改modelid可以使用modelscope的社区的模型,更加适合中文场景。
-
在满足硬件条件的情况下,可以轻松地将其改为分布式架构,以处理高频访问。
然而,我们可以看到回答的效果仍然不是很好, 文本分割和向量化的过程会直接影响结果,但是对比直接使用langchain,灵活性和中文的相关性好了很多(不过langchain也可以改向量算法)。
在专业领域来说,如果有已经构建好知识图谱的数据,使用这种方式可能会取得非常好的效果。
30分钟快速体验
以下代码已经在modelscope社区的notebook的环境中测试通过。从编写代码到回复,大概需要30分钟左右即可完成,非常适合测试和验证。
1、 安装依赖 ,为了方便使用,我已经把上述的代码整合成一个微型框架 vectorGPTBot 中。
pip install protobuf==3.20.0 transformers==4.27.1 icetk cpm_kernels chromadb
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
pip install vectorGPTBot=="0.1.6" -i https://pypi.Python.org/simple/2、 在modelscope的环境中,由于pyhton是3.7的版本。请按照以下步骤修改文件
/opt/conda/lib/python3.7/site-packages/chromadb/api/types.py
将第一行修改为以下两行:
from typing import Optional, Union, Dict, Sequence, TypeVar, List
from typing_extensions import Literal, TypedDict, Protocol保存文件并退出。
3、 启动
有三个参数可以自由定义 , 后面两个可以去modelscope社区根据自己的需求进行更换。
v= mainClass(
'/mnt/workspace/test2', #向量数据库保存的路径
"damo/nlp_corom_sentence-embedding_chinese-base", #文本向量算法
"ZhipuAI/ChatGLM-6B", #llm模型
)核心是两个命令
-
v.put_data 把数据导入向量库
-
v.query_data 查询数据
from vectorGPTBot.vectorGPTBot import mainClass
v= mainClass(
'/mnt/workspace/test2', #向量数据库保存的路径
"damo/nlp_corom_sentence-embedding_chinese-base", #文本向量算法
"ZhipuAI/ChatGLM-6B", #llm模型
)
v.put_data([
'你是谁?我是向量知识库问答机器人。',
'你可以做什么?回答问题。',
'吃了海鲜后是不能再喝牛奶的,因为牛奶中含得有维生素C,如果海鲜喝牛奶一起服用会对人体造成一定的伤害',
'吃海鲜是不能同时喝牛奶吃水果,这个至少间隔6小时以上才可以。',
'吃海鲜是不可以吃柠檬的因为其中的维生素C会和海鲜中的矿物质形成砷。',
])
v.query_data('你是谁?')等待20多分中左右,即可看到回复:
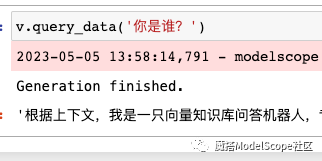
可以再问一下档案库里面的问题:









 已为社区贡献631条内容
已为社区贡献631条内容

所有评论(0)